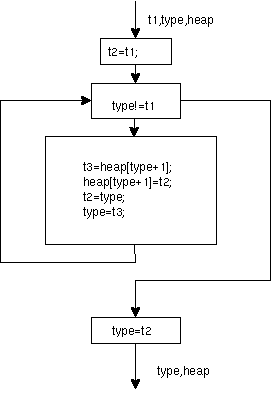
先週は、以下のことを勉強した。
484 reverse(t1)
485 int t1;
486 {int t2,t3;
487 t2=t1;
488 while(type!=t1)
489 { t3=heap[type+1];
490 heap[type+1]=t2;
491 t2=type;
492 type=t3;
493 }
494 type=t2;
495 }
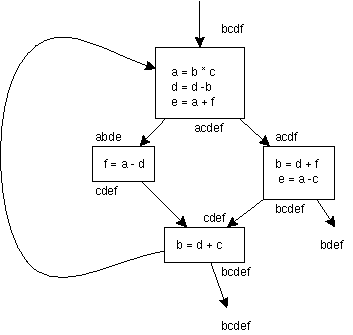
このフローグラフを考えてみよう。
flow-chart と違い、基本ブロックは最適化の単位となるので、可
能な限り一つにまとめなければならない。結果は以下のようになる。

peep holeや基本ブロックの中だけの解析には限界がある。特に、 レジスタの有効利用をおこなうためには、使われない変数を探しだ し、それに割り当てたレジスタを再利用することが重要である。ま た、直前の基本ブロックで再利用出来る値があれば、それを使うこ とが望ましい。そのためには、フローグラフ上で解析を行うのが良 い。
これらの解析は大域的データフロー解析(Global dataflow analsys) と呼ばれる。まず、基本ブロックの変数の代入に番号をつける。こ の代入によって定義された値(gen)がある。一方、代入された変数 の前の値は死んでしまった(kill)。そして、基本ブロックには、入 力(in)と出力(out) がある。gen,kill,in,out は変数の代入の番号 の集合である。基本ブロックSに対して、これらの間にフロー方程 式と呼ばれる関係がある。
out[S] = gen[S]∪(in[S] - kill[S])この方程式を利用して、あるブロックで他のどのブロックの定数が生きている かどうかを調べよう。(1)
in[B] = {} B は開始ブロック
in[S] = ∩ out[P] P はSに先行するブロック
out[S] = gen[S]∪(in[S] - kill[S])
この方程式を繰り返してフローグラフに適用すると、いつかは変化
がなくなる。最後に得られたin[S]により、この時点での利用可能
な式がわかる。これらの演算はビット演算(and, or)を使うことが
でき高速に計算することができる。
逆にoutからinを計算すると、その時点で生きている変数を調べる ことができる。(2)ここでは、変数の使用よりも優先して確実に定義さ れる変数の集合をdef[B]、変数の定義よりも優先して使用される変 数の集合をuse[B]とする。defとする。
in[S] = use[S]∪(out[S] - def[S]) out[S] = ∪ in[B] B は後続ブロック
上のフローグラフについて、(1),(2) の 大域的データフロー解析をおこなってみよ。
前の方法で生きている変数がわかると、それにレジスタを割り当て ることになる。同時に生きている変数には同じレジスタを割り当て てはいけない。
このためには、変数を節点とするグラフを考える。同時に生きてい る変数を線で結ぶ。隣同士が同じ色にならないように、グラフを塗 り分けることができれば、その色がレジスタ割り当てを表している。
もちろん適当に塗り分けるのではなく、ループの中を優先するなど の努力が必要である。