Compiler Construction Lecture 2/7
Menu
先週の復習
先週は、以下のことを勉強した。- 手続き呼び出し
最適化
基本ブロックとフローグラフ
これまでは、式(expression)単位のコンパイルを考えてきた。このコンパイルは、直接的で簡単である。レジスタの数の少ない6809では最適に近いコードを出力ることができる。しかし、最適化(optimize)を考える時、特にレジスタの数の多いRISCの場合は、これではレジスタを有効利用しているとはいえない。式の単位での最適化と、式を越えた大域的な最適化を考えるために、基本ブロック(Basic Block)とフローグラフ(Flow Graph)というものが工夫された。
基本単位は、単純に言えば、条件分岐や分岐を含まない逐次計算の部分である。フローグラフは、一つの手続の中で基本ブロックを分岐を結んだものである。
mc.c の reverse() はリストを逆順にするものだが、
484 reverse(t1)
485 int t1;
486 {int t2,t3;
487 t2=t1;
488 while(type!=t1)
489 { t3=cadr(type);
490 rplacad(type,t2);
491 t2=type;
492 type=t3;
493 }
494 type=t2;
495 }
このcadr()とかrplcad()は
2840 cadr(e)
2841 int e;
2842 { return heap[e+1];
2843 }
2894 rplacad(e,n)
2895 int e,n;
2896 { heap[e+1]=n;
2897 return e;
2898 }
である。すると、
484 reverse(t1)
485 int t1;
486 {int t2,t3;
487 t2=t1;
488 while(type!=t1)
489 { t3=heap[type+1];
490 heap[type+1]=t2;
491 t2=type;
492 type=t3;
493 }
494 type=t2;
495 }
としてよい。
問題1
このフローグラフを考えてみよう。このフローグラフ(flow graph)を作るには、まず基本ブロック(basic block) を抜きだす。基本ブロックは、分岐(barch)の入らない部分のまとまりをさす。次に、flow-chart のように基本ブロックを接続する。あと、入力される変数と、出力される変数を記述する。
flow-chart と違い、基本ブロックは最適化の単位となるので、可能な限り一つにまとめなければならない。結果は以下のようになる。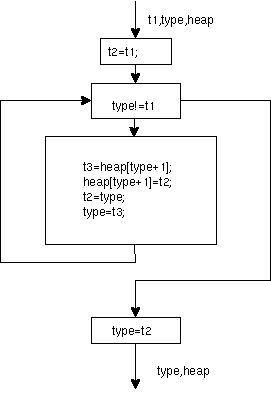
基本ブロック内部では条件分岐がないので、文(statement)の実行順序(execution order)をプログラムの意味を変えない範囲で変更してコンパイルして良い。これは局所的最適化と呼ばれる。
基本ブロックの間で再利用出来る式、計算する必要のない式、あるいは、使わない変数などを見つけると、それらを共有したり、削ったりすることができる。さらに、簡単なループの場合は内部の基本ブロックの定数などをループの外に出すことも行われる。これらは大域的最適化と呼ばれる。これらが終わると、変数にレジスタを割り当てる(register allocation)。RISCでは、このレジスタの割り当て方法が重要である。
基本ブロックの最適化 Optimization of basic block
基本ブロックの最適化では共通の式などを抜きだす。このためには、基本ブロックの中の式を一度、DAG グラフ(Directed Acyclic Graph)に直すのが良い。DAGの作り方
- 入力となる変数を一番下に置く
- 演算を行った順に、演算のノードを作る
- この時に同じ形のDAGは再利用して良い (これにより共通部分式(common expression) を取り除くことができる)
- 結果を変数に代入する時にはノードの横に変数名を書く
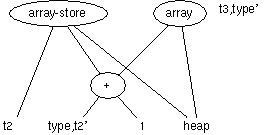 DAGからコード生成する時には、単に上から生成していくというわけにはいかない。ちゃんと計算可能な部分から計算し、代入する時には、他の演算がその前の値を使おうとしていないかを確かめなくてはならない。
DAGからコード生成する時には、単に上から生成していくというわけにはいかない。ちゃんと計算可能な部分から計算し、代入する時には、他の演算がその前の値を使おうとしていないかを確かめなくてはならない。
問題 1
以下のプログラムのDAGを作成せよ。できれば、作成したDAGにしたがってi386 のアセンブラを作成せよ。
A: a=b+c; b=a-d; c=b+c; d=a-d;
B: a=b+c; b=b-d; c=c+d; e=b+c;
C: e=a+b; f=e-c; g=f*d; h=a+b; i=i-c; j=i+g;
ヒント。単にグラフの形だけでなく、式の意味を考えて共通部分式としても良い。
局所的最適化 Local Optimization
局所的最適化の代表的なものは peep hole optimization と呼ばれるものである。これはいったんコードを生成した後に、そのコードを狭い範囲で見て、より良いものに置き換えられるならば置き換えるというものである。共通部分式の置き換えなどはできないが、簡単で効果的であることが知られている。コード生成の時点で行ってしまっても良い。例えば、micro-C ではそうなっている。- mov r3,a(r31); mov r3,a(31) などは後者は必要がない
if(0) {...} などの決まった条件分岐を消す - 連続した分岐を一つにする
- a+0, a*1 などの計算を止める
- a*2 などを足し算で置き換える
- load and update などのPowerPC独自の機能を使う
より進んだコンパイラ
今まで勉強したの最適化は、ある意味でアーキテクチャに関係しない。しかし、実際には、アーキテクチャにはアーキテクチャの特性があり、それに合わせた最適が必要となる。ここでは、大雑把に次の4種類のアーキテクチャを考えよう。- 組み込み用マイクロプロセッサ
- RISCプロセッサ
- ベクトル計算機
- 並列計算機
組み込み用プロセッサでは、8bit 程度のCPUであることが多く、レジスタの数も多くはない。したがってレジスタ関連の最適化はそれほど難しくはない。しかしメモリが限られていることがからコードの大きさの縮小などが重要である。Micro-C は、この用途に設計されている。また、Real-time monitor やI/Oアクセスと同時に用いられることが多く、アセンブラとの協調が必要である。
RISCプロセッサは現在の汎用計算機の主流であり、命令レベルの並列度を利用する。10年前は1命令1クロックなどと言われていたが現在ではバス幅を増やし、1クロックに複数の命令を実行するできるようになっている。命令レベルの並列度には2種類あり、RISCの方式として以下のように区別される。
- スーパーパイプライン 1命令の実行をさらに細かい単位(7段から10段)に分け、隣り合う命令を重ね合わせながら実行する
- スーパースカラー 複数の命令から同時に実行できる部分を自動的に検出し、実行順序の変更もおこないながら、並列実行をおこなう。
ベクトルプロセッサは、配列や行列の高速実行に適したアーキテクチャである。そのために、長い浮動小数点パイプラインを複数本持ち、専用の命令を持つ。RISCプロセッサでもソフト的にベクトル処理をおこなうことが行われている。ベクトルプロセッサ用のコンパイラでは配列処理をよりきめ細かに分析し、並列度とともに配列の効率的なアクセスを可能にするようなコードを出力しなくてはならない。
最近の数値計算マシンの主流は、ベクトル計算を備えた並列マシンであり、この分野では日本の技術は他の追従を許していない。(ただしあまり宣伝もしていない) アメリカのイリノイ大学はこの分野のメッカであるが、WWWはイリノイの計算機センタ(NCSA)の成果を広めるために開発されたともいえる。(もとは CERN で開発された)
しかし、並列計算機のコンパイラに関しては、まだ系統的に最適化をおこなうようなアルゴリズムやコンパイラ設計手法は確立されていない。現実には並列アーキテクチャは、個々のアーキテクチャの違いが大きく、人間による命令単位の調節がものをいう。特にプロセッサ間の通信のタイミングによりパフォーマンスは数10%も変わってしまう。一つの手法は、データ並列と呼ばれるもので、とにかく相互に依存度の低いデータをプロセッサごとに割り付けてしまうという方法がある。
命令単位の最適化
8bit CPUや、IBM/360, PDP-11, VAX あるいは MC68000 系のCPUでは複雑な命令が用意されており、それらを使うことによる最適化が重要である。これらのアーキテクチャ内部には並列度はあまりなく、レジスタもそう多くはない。しかもアドレッシングは複雑である割に、どのアドレッシングもそれほど実行時間に差があるわけではないので、できるだけ複雑な動作を一命令で実行することが重要になる。このような場合に有効な手法は、動的計画法による最適化とスーパーオプティマイザである。
パイプライン
RISC CPUでは、従来の2段から3段といったパイプライン実行ではなく、7段から10段といった深いパイプラインが採用されている。これは一つの命令の実行が終る前に数命令先が既に読み込まれ実行されつつあることを意味している。この時に先に実行されている命令が条件分岐命令であった時には、次の命令をどこから取って来るかを予測することはできなくなってしまう。この時、CPU は分岐先が決まるまで実行を一時中断する必要がある。これをストール(stall)といい5-7 clockのlossが生じる。条件分岐は実行時間の大半を支配する一番内側のループに必ずあるわけだから、このpenaltyは大きい。このペナルティを防ぐにはいくつか方法がある。
- 分岐命令が実行される時に分岐の方向が決まっているようにする
- 命令でどちらの方に良く分岐するかを指定する
- 分岐命令直後に実行する部分を前もって決めておく(delayed slot)
PowerPC の分岐予測
8つのflag brach bit
スーパースカラ
RISCの引き続く命令は、そのままの順序で実行されたのと同等に実行されなければならない。しかし、引き続く命令の関連がなければ、それらの順序を変えても良いし、並列に実行しても良い。並列に実行できないような場合は、命令に依存関係がある場合である。これらの干渉はパイプラインでも生じる問題である。パイプラインの場合にはパイプラインのストールという症状になる。
複数演算を同時に実行する命令 (内積演算、MMX)
ソフトウェアパイプライン
ベクトルプロセッサ
ベクトルプロセッサの場合は、配列全体の依存関係を見ているだけでは不十分である。同じ配列をアクセスする演算でも、その演算の干渉がなければ、それを別々のパイプライン(の命令)にすることにより高速な実行が可能となる。添字の干渉の判定(diophantos equation)
Fortran Syndorome
並列化コンパイラ
- SIMD, MIMD
- Tightly coupled
- Distributed
- データパラレル
- バリア
ランタイムコンパイラ
- JIT
- SDF