Compiler Construction Lecture 12/18
Menu
先週の復習
先週は、yacc による構文解析について勉強した。yacc を使うことにより、文法構造を直接に反映したプログラムを行うことができる。(今日はアンケート を取ります...)
1/8 は休日です。1/15 はお休み。なので、授業は、1/22 からです。
Simple Compilerの構成
では簡単なコンパイラとその構成を調べて見よう。
Makefile どのようにcompileするかの指示 s-compile.c compiler本体(interpreterとほとんど同じ) s-intel.c Code Generator s-token.c Tokenizer s-tree-compile.c Intermidiate Tree Version s-yacc.y Yacc version
Simple CompilerのMakefile
プログラムを作るときには必ず Makefile を作り、make を使うことにしよう。つまらないタイプミスから開放される。3回以上コマンドを手で入力するのはコンピュータに対する侮辱である。以下は Makefile の一部である。実行するコマンドの部分はタブで始めることに注意よう。
1 TEST = s-intel-r
2
3 CC = gcc
4 CFLAGS = -g
5 COMPILER = s-compile.o s-token.o
6 # COMPILER = s-tree-compile.o s-token.o
7 # COMPILER = s-yacc.o s-token.o
8
9 TARGET = s-calc s-intel s-intel-r s-sparc
10 all: $(TARGET)
11
12 s-calc: s-calc.c s-token.o
13 $(CC) $(CFLAGS) -o s-calc s-calc.c s-token.o
14 s-intel: $(COMPILER) s-code-intel.o
15 $(CC) $(CFLAGS) -o $@ $>
16 s-intel-r: $(COMPILER) s-code-intel-r.o
17 $(CC) $(CFLAGS) -o $@ $>
18 s-sparc: $(COMPILER) s-code-sparc.o
19 $(CC) $(CFLAGS) -o $@ $>
20 s-yacc.o: s-yacc.y
21 $(YACC) s-yacc.y
22 mv y.tab.c s-yacc.c
23 $(CC) -c s-yacc.c
24 test: $(TEST)
25 ./$(TEST) < s-input.txt > s-output.s
26 $(CC) s-output.s
27 ./a.out
28
29 clean:
30 rm -f *.o $(TARGET) a.out s-output.s s-output.a09 s-output
31
32 # DO NOT DELETE
33
34 calc.o: /usr/include/stdio.h /usr/include/sys/cdefs.h
35 ...
最初の7行は変数の定義。ここではi386用のemulatorとassemblerを指定している。その後の$(COMPILER)などは最初に指定した変数で置き換えられる。
12行目では s-calc の作り方を説明している。:のすぐ後には、s-calc.c つまり、s-calc.c が s-calc を作るために必要なことを示している。s-calc の作り方は、次の行に書いてある。s-token.o は、s-token.c から作成するが、*.o は object file であり、*.c があれば、それから作られると make は考えている。実際には、これらの暗黙のルールがライブラリなどに置いてある。BSD/OSでは、 /usr/share/mk/sys.mk に置いてあるので参照してみよう。もちろん、man make の実行結果を参照することも重要である。
実際の作り方は、: の行のあとにタブを先頭に持つ行を続けて書く。スペースではいけない。良くある間違いなので気を付けよう。この行が指定され変数を置換された後、 sh に渡されて実行される。s-calc では、token.o が既に作られていれば、それを使ってs-calcをlinkする。
make は、Makefile を参照しながら、ファイルの時間を見る。そして、生成されたものよりも、新しい変更時間を持つ原料があれば、その生成をやり直す。もちろん、原料の作り直しが必要かどうかも自動的に判断する。これは、一種の interpreter である。
# DO NOT DELETE
から以下の行は、makedepend というコマンドで自動的に生成される部分である。ここには、#include によって生じるC言語の依存性を記述する。もっとも、この程度のコマンドは、自分でsed/perlなどで書いても10分もあればできてしまう。
問題
Makefile の中で、
TEST = s-intel
COMPILER = s-compile-tree.o s-token.o
とすると、i386 の tree を使ったコンパイラが生成されてテストされる。すべての*.o
が、まだ作成されていない時に、make test とすると、どのような順序で、どのようなコマンドが実行されるかを記述せよ。そのコマンドが成功したとして、さらにs-compile-tree.c を編集したする。その後、make test としたら、コマンドはどのような順序で実行されるかを記述せよ。また、なぜ、その順序で実行されたのかを Makefile の中のルールに合わせて、簡単に説明せよ。
分割コンパイル
複雑なプログラムになると、プログラムを一つのファイルにまとめることもできなくなる。また、そうしなければ、複数の人間でプログラムを書くということもできない。そこで、プログラムを分割してcompileするということが必要になる。分割した時に、分割した部分のどこを外に見せて、どこを隠すかというのが問題になる。この場合の単位は module と呼ばれる。すべてを見せてしまっては、分割した意味がないともいえる。しかし、見る方が悪いのであって、すべてはdefaultで見えている方が良いという考え方も存在する。実際には、見せるためには、分割したもの同士の情報のやり取りが必要なので、import, export や、public, privateなどのkeywordで情報のやり取りを制御するようにすることが多い。Cでは、extern と static がそれに相当する。C++では、publicとprivateを使う。
このような情報の制御と、ファイルの分割は本来は独立な問題である。しかし、Cではファイルの分割でしか module を定義できない。C++の場合には class がその役割を果たしている。
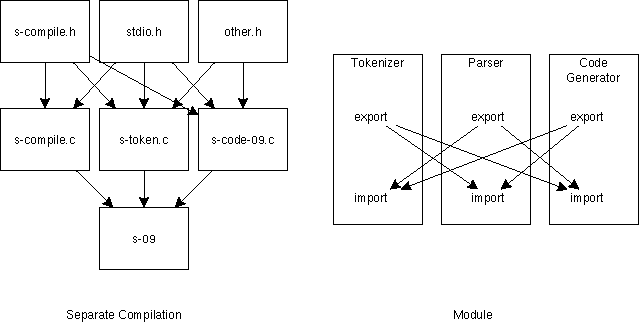
分割コンパイルでの変数の使い方
分割コンパイルする場合は、Cでは以下のようにすることが多い。- 大域変数と、大域関数は、すべて共通のheader file .h で extern 宣言する。
- マクロや定数は、大文字を使う。大域変数などには、小文字を使う。これらの定義も一つのheader file .h で行う。
- 大域変数の定義は、ただ一つの .c ファイルで行う。
- 各ファイルに局所的な変数と関数は、すべて、そのファイルでstatic 宣言する。
ただし、分割が進むと、大域関数とかを、すべてのファイルが使うとは限らない。その時には、.c ファイルに対応した、.h を用意して、使うものだけど、#include するということになる。この時に、#include の順序に依存したり、2度 include したりしないように注意する必要がある。
定数の設定には、#define ではなく、enum を使う場合もある。この方が、debugger が定数の表示を知ることができるので、debug しやすくなる。
コンパイラのデバッグ
コンパイラのデバッグは、通常のデバッグよりも複雑で、何回かの段階をへる必要がある。まず、コンパイラがちゃんと動作することを調べる
次に、コンパイラの出力が、ちゃんとコンパイルできることを調べる
そして、その出力が正しく動作していることを調べる
特にコンパイラ自身をコンパイルできることを調べる
自分自身でコンパイルしたコンパイラが、もともとあるコンパイラでコンパイルしたものと同じ出力を持つことを確認する。
もし、コンパイラの動作がおかしかったから?
どこで動作がおかしくなったかを調べる
この時に、gdb を使ったアセンブラのデバッグを行う
disassm disassember
b *0x23423 そのアドレスでbreak
stepi 一命令実行
nexti 同上
p $eax レジスタ %eax を表示
cont 実行を再開
cond 3 if lineno==300 lineno という変数が300になったら停止
ignore 3 100
そして、おかしなコードを生成しているコンパイラの部分を修正する
レジスタを使うコードの生成
今までの簡単なコンパイラでは、Register-Memory Architecture を使い、Register 1つと、Stackの先頭の演算に式をコンパイルしていた。ここでは、さらに、Load-Store Architecture を想定して、Register 上のでの演算にコンパイルして見よう。最近ではRegisterの数は32が多く、その中で自由に使えるものは10-20程度ある。通常の式であれば、スタックの深さは10以下であり、すべてRegister 上で計算できる。この部分を記述するのは簡単である。もっと難しいのは、複数の式でRegisterを共有する場合であり、この時には、共有する変数は非常に大量になる。これに対して適切なRegister割当をおこなうのがコンパイラの最適化として重要である。この割当の善し悪しは、関数呼出時の手間やCache(キャッシュ)の占有度に影響し、最終的にプログラム全体のPerformanceに影響する。この問題は、授業の後半で議論することにしよう。
さて、Registerを使った式の計算は、スタックに変数を取っておく代わりにRegisterに取っておくだけである。したがって、コンパイラを変更しないで、コード生成系のみを変更するようにしようRegister 割当をおこなう s-code-sparc.c を見てみよう。
emit_push() でスタックにaccumlatorの値をsaveする代わりに、新しくaccumlator として使う Register を割り当てれば良い。このために、get_register() という手続きを考える。
char *reg_name[] = {
"%g0","%g1","%g2","%g3","%g4","%g5","%g6","%g7",
"%i0","%i1","%i2","%i3","%i4","%i5","%i6","%i7",
"%l0","%l1","%l2","%l3","%l4","%l5","%l6","%l7",
"%o0","%o1","%o2","%o3","%o4","%o5","%o6","%o7"
};
#define O0RN 24
#define MAX_REGISTER 32
char regs[MAX_REGISTER];
char reg_stack[MAX_REGISTER];
int
get_register() {
int i;
for(i=0;i<MAX_REGISTER;i++) {
if (! regs[i]) {
regs[i]=1;
return i;
}
}
error("Expression too complex (register overflow)");
return -1;
}
regs[]という配列に、そのRegisterが使われているかどうかを示すflagをいれておく。get_register()では、最初のflagが空いているRegisterの番号を返す。もちろん、番号とassemblerの中でのRegister名との対応を示すものが必要なので、それは、reigster_name[]という配列を作っておく。このうちいくつかは、最初から使用不可(システムやarchitectureが使用している、例えば、SP, RTOC など)である。
どのRegisterをsaveに使ったかはコンパイラが自分で覚えてなくてはいけない。これにはスタックを使う。これは、ちょうど実行時のスタックをコンパイル時に部分計算していると考えることもできる。先に計算できる部分なわけである。accumlatorを表す Registerの番号を current_register としよう。
void
emit_push()
{
reg_stack[reg_sp++] = current_register;
lrn = reg_name[current_register];
current_register = get_register();
crn = reg_name[current_register];
}
ここで、lrn は last regster name, crn は current register name につもりである。どうせ、すぐ使うのだから、ここで代入しておこう。emit_load, emit_store,
emit_value は、current_register に値をいれるだけなので、以下のように簡単に書くことができる。
void
emit_value(d)
int d;
{
if(-4096 < d && d < 4096) {
printf("\tmov %d,%s\n",d,crn);
} else {
printf("\tsethi %%hi(%d),%s\n",d,crn);
printf("\tor %s,%%lo(%d),%s\n",crn,d,crn);
}
}
void
emit_push()
{
reg_stack[reg_sp++] = current_register;
lrn = reg_name[current_register];
current_register = get_register();
crn = reg_name[current_register];
}
void
emit_load(assign)
int assign;
{
printf("\tsethi %%hi(_variable+%d),%%g2\n",assign*4);
printf("\tld [%%g2+%%lo(_variable+%d)],%s\n",assign*4,crn);
}
void
emit_store(assign)
int assign;
{
printf("\tsethi %%hi(_variable+%d),%%g2\n",assign*4);
printf("\tst %s,[%%g2+%%lo(_variable+%d)]\n",crn,assign*4);
}
実際の計算を行うところでは、stackを一つ下げることをおこなう必要がある。ここではRegister-Register演算をおこない、入らなくなったRegisterの regs[] に 0 を入れれば良い。これは pop_register()という手続きにしよう。
void
emit_calc(op)
int op;
{
char *orn;
orn = pop_register();
if(op==O_MUL) {
printf("\tmov %s,%%o1\n",lrn);
printf("\tcall .umul,0\n");
printf("\tmov %s,%%o0\n",orn);
printf("\tmov %%o0,%s\n",crn);
} else if(op==O_DIV) {
printf("\tmov %s,%%o0\n",lrn);
printf("\tcall .div,0\n");
printf("\tmov %s,%%o1\n",orn);
printf("\tmov %%o0,%s\n",crn);
} else if(op==O_DIV_R) {
printf("\tmov %s,%%o0\n",orn);
printf("\tcall .div,0\n");
printf("\tmov %s,%%o1\n",lrn);
printf("\tmov %%o0,%s\n",crn);
} else if(op==O_SUB) {
printf("\t%s %s,%s,%s\n", opcode[op], lrn, orn, crn);
} else {
printf("\t%s %s,%s,%s\n", opcode[op], orn, lrn, crn);
}
}
char *
pop_register() {
int i,j;
j = current_register;
i = reg_stack[--reg_sp];
lrn = reg_name[i];
regs[j]=0;
current_register = i;
crn = reg_name[i];
return reg_name[j];
}
ここでは、スタックを使う場合のように、最後の結果が最初のRegisterになるように工夫している。
これにより、スタック上での演算よりも確実に高速なコードを出すことができる。しかし、単純にレジスタを使うだけでは十分ではない。例えば、
0+(1+(2+(3+(4+(5+(6+(7+8)))))))-(0+(1+(2+(3+(4+(5+(6+(7+8))))))))
のような場合は、レジスタをかなり多く必要とする。である。しかし、これを
0+1+2+3+4+5+6+7+8-(0+1+2+3+4+5+6+7+8)
と書き換えるとReisterは一つしか使わないで済む。もちろん、中間木を使ってコンパイル時に定数計算をしてしまえば、もっと簡単になるが、ここでは簡単のために、それはおこなっていない。
このような書き換えは簡単だと思うかも知れないが、実際には同等な式への変換は無数にあり、もっともRegisterが少なくなるような式の変形は自明ではない。このような変形を行うためには中間木への変換が必ず必要となる。このような式の変換に付いても後で議論することにしよう。
i386のレジスタ割り当て
i386 の場合は、レジスタは極めて少ない。また、割算の場合は、特定のレジスタでしか計算をすることができない。したがって、レジスタとスタックを混在させたコンパイルが必要になる。また割算の場合は、特定のレジスタに移動させる必要がある。
s-code-intel-r.c は、そのようなコンパイラの例である。
問
0+(1+(2+3))-(0+(1+(2+3))) の式の計算を上のcompiler によりi386の命令に変換した結果を記述せよ。0+1+2+3-0+1+2+3 の場合はどうなるか?また、生成されるコードの間違いを指摘し、コンパイラのバグを見つけ、修正せよ。
問
s-code-intel-r.c を使った、s-intel について、論理演算 &,| を拡張して見よう。余裕があれば他の拡張にも挑戦して見よう。- 中間木を使い、a+(b+c) -> (a+b)+c のような変形をサポートする
- 配列をサポートする
- Cの3項演算子 (cond)?(true):(false)
- Pointer演算