Compiler Construction Lecture 1/29
Menu
先週の復習
Micro-C の全体構成左辺値と右辺値 left value and right value
ポインタや構造体が出て来ると、代入文も複雑になる。代入文は以下のような構造をしている。
left value = right value
s-compile.c では、left value は単純(英字一文字!)だったが、今度は配列の引数や構造体へのポインタなどを計算しなくては代入ができない。
これらは、最終的にはload/storeの機械語に落ちるはずである。つまり、どのアドレス(address)から、どれくらい(size)を loadして、どれくらいをstoreするのかを決めれば良い。
Micro-C では、i386の汎用Registerを使ってaddressを計算する。実際には、%ebxなどの3種類のポインタを使い分けている。
- %ebx -- 汎用のポインタ
- %ebp -- 局所変数を指し示すポインタ
- address -- 大域変数
- movl (%ebx),%eax ------ 任意のアドレスからのload
- movl %eax,count -------- count という大域変数へのstore
- movl -16(%ebp),%eax ------- 4番目の局所変数からのload
left valueもright valueもアドレスを計算するところまでは同じである。そこで、Micro-C では expr はアドレスまで中間木を生成し、必要な時にrvalue()という手続きにより値をloadする中間木を生成している。もちろん、定数などはアドレスを計算しなくても直接にloadされているので、rvalue() は何もしない。
ravlue() は短いが、それを理解するためには、Micro-C の中間木を理解しなくてはならない。
Micro-C の中間木
Micro-C での木を扱う手続きには奇妙な名前をした関数(function)が使われている。
2836 car(e)
2837 int e;
2838 { return heap[e];
2839 }
2840 cadr(e)
2841 int e;
2842 { return heap[e+1];
2843 }
2844 caddr(e)
2845 int e;
2846 { return heap[e+2];
2847 }
2848 cadddr(e)
2849 int e;
2850 { return heap[e+3];
2851 }
2852 list2(e1,e2)
2853 int e1,e2;
2854 {int e;
2855 e=getfree(2);
2856 heap[e]=e1;
2857 heap[e+1]=e2;
2858 return e;
2859 }
2860 list3(e1,e2,e3)
2861 int e1,e2,e3;
2862 {int e;
2863 e=getfree(3);
2864 heap[e]=e1;
2865 heap[e+1]=e2;
2866 heap[e+2]=e3;
2867 return e;
2868 }
2869 list4(e1,e2,e3,e4)
2870 int e1,e2,e3,e4;
2871 {int e;
2872 e=getfree(4);
2873 heap[e]=e1;
2874 heap[e+1]=e2;
2875 heap[e+2]=e3;
2876 heap[e+3]=e4;
2877 return e;
2878 }
2879 getfree(n)
2880 int n;
2881 {int e;
2882 switch (mode)
2883 {case GDECL: case GSDECL: case GUDECL: case GTDECL:
2884 e=gfree;
2885 gfree+=n;
2886 break;
2887 default:
2888 lfree-=n;
2889 e=lfree;
2890 }
2891 if(lfree<gfree) error(HPERR);
2892 return e;
2893 }
2894 rplacad(e,n)
2895 int e,n;
2896 { heap[e+1]=n;
2897 return e;
2898 }
これらの関数名は、LISPというLIST処理専門に設計されたプログラミング言語から来ている。しかし、Micro-CでのLISTは、やや簡略化された形で実装されている。本来は、list2()などは、配列ではなくLISTを返すべきだ。これは Micro-Cでは8bit CPUつまり、64kbyteのメモリ空間を想定しているので、LIST(2進木)を使うことによりメモリをより多く消費することを嫌ったのだと思われる。
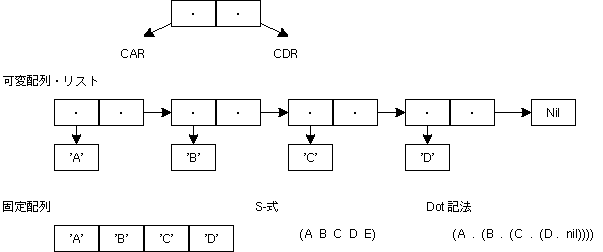
この(簡略化された)LIST(専門的にはcdr codingというのだが、そんなことはどうでもいいことなのだが...)の、最初の要素をcar()、次の要素をcadr()、次の次の要素をcaddr() という。(最近のLISPでは、first(), second(), third() を使うのが普通なようだ) 木には葉(leaf)と幹(node)があるのだが、car()の値によって、それらを区別している。cadr()とかの内容はcar()によって異なる。これはかなり複雑だが、実際には、car()の値によって処理を変えれば良いだけだ。
どのような中間木のノードがあるかは、list2 などをgrepしてみれば簡単にわかる。(が、かなりあるので、ここでは省略する) Micro-C では、変数の型も木で表している。したがって、式を表す木と型を表す木の二つの木を扱うことになる。型は常にtype という変数に入っている。この二種類の木は、違う構造をしているので気をつけて扱わなくてはならない。
問題1 以下のCのstatementに対応するMicro-Cの中間木と生成されるi386のコードについて考察せよ。ただし、以下のint *a; という型を仮定する。
- *a = 1;
- a = &a[3];
- *a = *(a + a[3] + 2);
- a = *( &a + 3);
問題2 &a = (int *)3; というのは、Micro-C ではエラーになる。なぜ、エラーなのかを説明せよ。