Operating System Lecture 1/22
Menu
先週の復習 -- Unix の同期機構
- select
- 時間の計算
- 時間の待ち合わせ
- client/server
計算練習
以下の計算をせよ。表記はCと同じものを使うこと
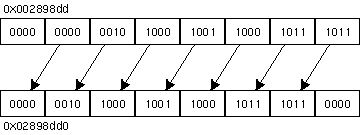
- 0x002898dd を4つ左にシフトした結果を16進数で表せ
- 2^32 を10進数と8進数と16進数と2進数で表せ
- 0x123 を16倍した数を16進数で表せ
- 0x7AF を256で割ったあまりを8進数で表せ
- 0x7AF を4つ左にシフトした結果を16進数で表せ
- 2kbyte とは10進数でいくつか
Memory Management
コンピュータにはメモりがつきものである。このメモリは、どのように使われているのだろうか? メモリは、- malloc()
- free()
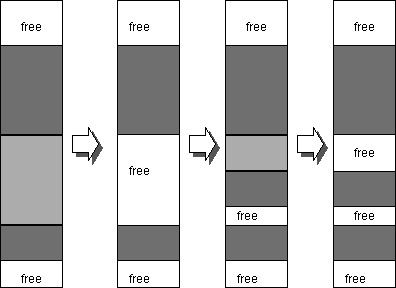 この状況は最悪、メモリの有効利用度(Memory Utilization)を50%程度にまでさげてしまうことが知られている。
この状況は最悪、メモリの有効利用度(Memory Utilization)を50%程度にまでさげてしまうことが知られている。
アドレス変換
メモリは、OS下の複数のプロセス、ユーザから要求されている。この時に、個々のプロセスでは、あたかも自分一人がCPUとmemoryを専用している下のように見えた方が良い。これは仮想プロセッサと呼ばれるものであった。仮想プロセッサのメモリと実際のメモリを結びつけるには、アドレス変換(Address Translation)という技術を用いる。 この時に、flagmentation を防ぐために、実際のメモリ(Physical memory)は、前もって細分化されて、それの不連続(non-contiguous)な集合が、プロセスのメモリ(Virtual Memory)上での連続なメモリに対応するようになっている。
この時に、flagmentation を防ぐために、実際のメモリ(Physical memory)は、前もって細分化されて、それの不連続(non-contiguous)な集合が、プロセスのメモリ(Virtual Memory)上での連続なメモリに対応するようになっている。
論理メモり空間(Logical Address) を物理メモり空間(Physical Address)に変換するメカニズムがアドレス変換である。これにより、メモリの割り当て、返却によるメモリ使用の細分化(fragmentation)を防ぐことができるだけでなく、複数のプロセスに対して、一つの物理メモリを、あたかも自分の固有のアドレス空間(Memory Spcace)であるかのように割り当てることができる。変換の単位は、frame (or page ) と呼ばれる。普通は、512byte - 4096byte 程度である。32bit CPU の場合、メモリのアドレスは、0x00000000 から0xffffffff の16進数で表すことができる。Page size ごとに frame 番号が振られていて、メモリのアドレスは、frame 番号と、frame の中のoffset で表される。例えば、Page size = 0x10000 ならば、0x80000500 のアドレスのframe番号は 0x8000 で、offset は 0x0500 となる。(0x80000500 = 0x8000 x page size + offset )
![]()
問1
Page size = 4096 の時に、メモリアドレス 0x01234321 の frame 番号と、offset を16進数で計算せよ。0xfffffecc はどうか?

問2
0x01234321 と 0xfffffecc に対応するアドレス変換テーブル(page entry table)の offset はいくつか? それぞれに対応するpage のアドレス変換テーブルの内容は、それぞれ0x1344と、0x1233 であった。それぞれのアドレスはどのように物理アドレスに変換されるか。
アドレス変換用のメモリ
ただし、この表も、64bit/32bit のメモリ空間に対しては、かなり大きくなってしまう。
問3
frame size を4kbyte とした時に、32bit memory spaceで必要なpage table の大きさを求めよ。64bit ではどうか? 7Gbyte (Enterprise 3000のメモリのフル実装)ではどうか? 一つのpage table entry の大きさは32bitの時に16byte、64bitの時に32byteとする。
Multi level page-table scheme
ただし、このテーブルが全部必要なわけではない。論理アドレス4Gのプロセスでも実際に使われるのは1M程度なのが普通である。そこで、この変換を2重3重にしてテーブルそのものを必要な部分だけ割り当てるようにする。また、この多重変換により、ページテーブル自身を仮想記憶上に置くことができるので、変換テーブルが大きくなっても実メモリを圧迫しなくなる。
問4
32bit address に対して、2重の変換を行った時に、frame size 2kbyte, p1 のbit幅8とする時に、p2 のbit 幅はいくつか?
この変換はhardware にとっても重いので、このpage entry をcache するという技術が使われる。これを、TLB (Traslation lookup
buffer) という。最近では、プロセスごとにTLBを持つTagged TLBという機能も使われている。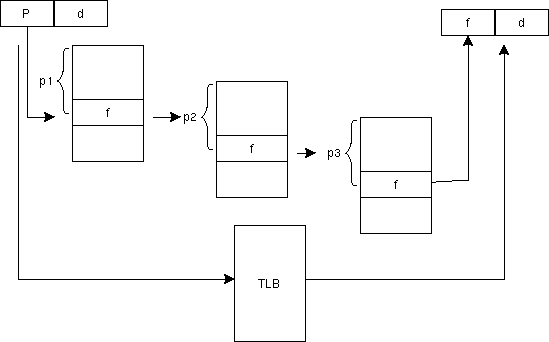
問5
Pagesize 4096 byte の時、0x05543344 と 0xffeed013 に対応するアドレス変換テーブル(page entry table)の offset はいくつか? それぞれに対応するpage のアドレス変換テーブルの内容は、それぞれ0x1004と、0x5233 であった。それぞれのアドレスはどのように物理アドレスに変換されるか。
Segmentation
もし、CPUが16bitデータしか扱う能力がない時に、32bitアドレスを扱いたい時にはどうすればよいだろうか? 80x86 architecture などでは、segmentation という技術が使われている。これは、CPUから出力されるアドレスをCPUのアドレスレジスタだけでなく、Segment Register との組で表すものである。通常は単なるshift + 加算で処理が行われる。Paging を行う場合は、Segment RegisterにはPage Entry Table そのものを使っても良い。この場合は、Segment Register の数値にはさまざまな意味が与えられる。
16it CPU 8086 では、Segment register は4つ(CS,DS,ES,SS)あり、アドレスを指示できるアドレスレジスタは6つである(BX,SI,DI,BP,SP,IP)。それぞれ16bit幅であり、Segment register は 4bit shiftされてアドレスレジスタに加算される。CS:IP で CS segemnet を使って、segment の中で IP のoffset を持つアドレスを指示することになる。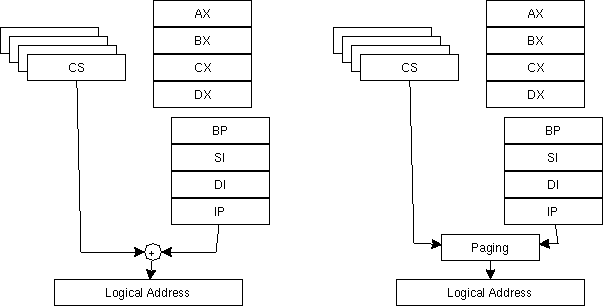
問6
8086 で表すことのできる最大のメモリ空間の大きさはいくつか? CS の内容は、0x1234, IP の内容は、0x0ffe であった。CS:IP で表される論理アドレスはいくつか?(80186 という 8086 をちょっとだけ改良したCPU が、ワンダースワンというゲーム機で使われている)
問7
Segmentation に対して、一つのレジスタでアドレスを指示する方法をLinear address (線形アドレス)という。Paging をおこなうシステムにおいて、Segmentation と Linear address の優劣を比較して論ぜよ。(ヒント: アドレス空間が大きい時、小さい時を比較しよう。プログラムのしやすはどうか? システムプログラムはどちらが書きやすいか? 効率は? )
仮想記憶 Virtual Memory
メモリはいくらあっても足りないものだが、そのメモリはいつも使われているわけではない。一方、メモリと磁気ディスクのような大容量外部記憶を比較すると、常に外部記憶の方が安価である。そこで、paging されたメモリの一部を磁気ディスクに移すという方法が考えられる。これは、メモリ上にはないメモリ空間を作ることになる。これを仮想記憶(Virtual Memory)という。必要に応じて、ディスクの内容をメモリにコピーしたり、メモリの内容をディスクに書き出すことにより、仮想的にメモリを実現する。もちろん、これをファイル操作などによりアプリケーションレベルで実現することもできる。これは、overlay などと呼ばれ、MSDOS 2.x, 3.x などでは良く使われていた。また、Intel 8086 のようなアドレス空間よりも大きなメモリを実装するシステムの場合、Window と呼ばれる部分に、他のメモリをマップすることも行われていた。これは、Extendene Memory Management (EMM) と呼ばれ、MSDOS のもっとも汚いAPIの一つとなった。このようなことをすると、OSで共通に実装するべき部分をアプリケーションで繰り返し実装する必要があり、しかも、この部分はかなり複雑なので、バグを呼びやすい。32bit CPUでは、将来的にこのようなWindowサポートが必要になる可能性はあるが、64bit CPUでは、その心配はないと思われる。64bit OSは既に実用レベルにあるが、広く広まるには、まだ数年は時間がかかると思われる。
ディスク上には、 仮想メモリの内容をとって置く場所を確保する必要がある。これをSwap領域という。Swap 領域は、特別なDisk
領域を取る場合もあるし、普通のファイルとして実現する場合もある。ファイルシステム上の空き領域をSwapに用いる場合もある。さらに、Network を経由してSwapしてもよい。この場合も、NFS経由でSwapする方式と、直接、ネットワーク経由でディスクにアクセスする方法(remote disk)の2種類が存在する。
Page fault
技術的には、Page Entry Table に、そこが実際にメモリが割り当てられているかどうかを示すbitを付けるだけでよい。もし、CPUがメモリの割り当てられていないPage Entry Tableをアクセスすると、CPUは割り込みを発生する。これを page fault という。その割り込みにより、OS がそのPageを実際のメモリに割り当て、ディスクから内容を複写する。これをPage in, Swap in という。この時に、CPU は割り込みを起こした命令を正確に再実行する必要がある。メモリで使う確率が少ないものをディスクに追い出すことをSwap out またはPage outという。
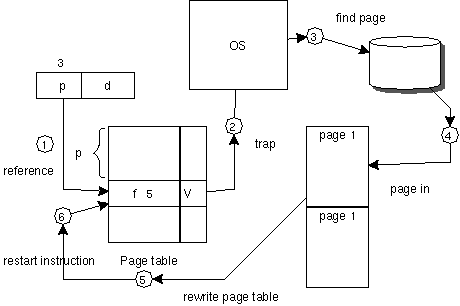
実際のpage fault では、命令の再実行を正確に行う必要がある。これはCPUがサポートする必要がある。(意外に複雑なことになる)例えば、68000 は再実行を正確に行うことができず、68010という別なCPUを開発するはめになった。page fault の処理の最中に、もう一度 page fault が起こると、これは致命的なことになる。これを double page fault という。
Perfomance of Demand Paging
問8
平均page-falut処理時間が25m sec, memory access 100n sec の時に、page fault rate が、1% の時の effective access time を求めよ。page fault rate が、0.001% の時の effective access time を求めよ。性能低下を20%以下にするためには、page fault rate はいくらでなければならないか。
effective access time = (1-p) x (memory access time) + p x (page fault time)
Page Replacement
page-replacement する時に、どのpageを書きだせば良いのだろうか? これを決めるアルゴリズムはいくつか知られている。
- FIFO
- Optimal
- LRU (Counters, Stack)
Unix では、pageout あるいは、swapper と呼ばれるプロセスが、使われていないメモリをディスクに追い出している。
仮想記憶の制御

仮想記憶はメモリとSwap領域を接続する。つまり、メモリとディスク上のファイルに対応があることになる。メモリをアクセスすることとファイルにアクセスすることは、ここでは同一になる。
Unixでは、mmap ( memory map )というシステムコールによって、仮想記憶を制御することができる。この機構は、共有メモリを実現したり、ファイルとメモリの対応を実現したりすることができる。これらの機能は、Mach OS により最初に実現されて、Sun OS そして、BSD/OS などにも使われるようになった。
メモリに書き込みがない場合には、そのSwap領域は書きだす必要がない。mmap の場合は、書き込みを行った時にはメモリの内容をファイルに書きだすことになる。これをcopy-on-writeという。
リアルタイム処理などでは、プログラムやデータが仮想記憶に追い出されてしまうと、致命的な処理時間の遅延が生じる。そこで、メモリの特定領域を実メモリに固定する方法が使われる。これは、メモリのpin down (ピン止め)と呼ばれる。Sun OSやBSD/OS では、mlock/munlock によりpin downすることが可能である。
問9 : 共有メモリを実現するmmap
mmap_test.c は、共有 メモリを使用するmmapの例である。man mmap を参考にしながら、このプログラムの動作を説明せよ。プログラムを変更し、リアルタイムで、共有された情報が変化することを確認せよ。
問10 : mmap によるコピー
mmap_copy.c は、mmap を使ったファイルコピーである。 通常のread/write とどのように動作が異なるかを説明せよ。また、実際に動作させて、cp との時間を測定してみよ。
time cp a b
などとすることにより、時間を測定することができる。一回目ののコピーと二回目のコピーの時間差についても考察せよ。また、コピー先を削除した場合はどうか? (時間差がはっきり分かるように、大きめのファイルをコピーする必要がある。
問11 : mmap の改良
このプログラムをfjに公開したところ、以下のようなコメントをもらった。コメントにしたがってプログラムを改良し、時間を測定して見よ。
In article <199809030356.MAA10105@srapc459.sra.co.jp>, Makoto Ishisone writes:
> mmap だけを使うのではなくて、mmap と write の組合せで使わないと意味が
> ないと思います。書き出しも mmap を使っちゃうと、せっかく read を使わな
> いことでメモリコピーを節約したのに、結局自分で memcpy することになっちゃ
> いますから。
>
> mmap+write だと、極端な話 /dev/null にコピーする場合、ほとんど何もしな
> いに等しいのですごく速くなります。それに意味があるかどうかは別として。
>
> 添削してみたバージョンをつけておきます。mmap+write に変えた以外に、
> ・open() の結果のチェックが間違っていたので修正
> ・mmap() の結果のチェックに MAP_FAILED を使うように修正
> ・exit() の値が逆 (正常終了なら 0、異常終了なら 1 にすべき)
> だったので修正
> ・その他エラーメッセージの表示方法を好みにあわせて変更
> してあります。FreeBSD で確かめましたが、BSD/OS だと修正が必要かも。
> -- ishisone@sra.co.jp
In article <snm4suo6psa.fsf@ludwig.spp.hpc.fujitsu.co.jp>, HASHIMOTO, Tsuyoshi writes:
> copy 元のファイルを mmap した領域を,単純に copy 先ファイルに write(2)
> (以下,この方法を (A) として言及)する方が,速いと思います.i.e.
> write(to,from_mmap,size);
> 正確なところは,profiler など(時刻表示 option つきの system call trace
> コマンドとかもあれば使えそう)で所要時間を測定したり,OS の system
> call の実装/仕様を確認しないと分かりませんが,BSD/OS は使っていないし,
> 実装も知らないので,他の UNIX のいくつかからの類推で考えて見た限りでは,
> > http://rananim.ie.u-ryukyu.ac.jp/~kono/os/98-06-26/mmap_copy.c
> のコードは,例えば次のような原因で,read/write を使っている cp や前述
> の方法 (A) よりも,遅くなると思います.
>
> (1) mmap(2) + write(2) などの方が OS 内で disk I/O を最適化しやすそう.
> - OS からみて,memcpy(to_mmap,from_mmap,size) での pagefault のたび
> に通知されるより,system call で一度に教えてもらえる点でも有利かも.
>
> (2) ファイルの大きさによっては page out が起こりやすくなるかも知れない.
> - user 空間に copy 元と copy 先の2つの buffer があることになるので.
>
> (3) memcpy の CPU 時間消費で,実行優先度が下がってしまうかも知れない.
> - read(2) や write(2) の発行で sleep 状態になると実行優先度が上がる
> かも知れない.
>
> (4) msync(to_mmap,size) が disk に書き終るまで待つなら,書き込み処理は,
> write(2) + fsync(2) (ないし,O_SYNC 指定で open した場合の write(2))
> 相当の動作をすると考えられるため,単なる write(2) より所要時間が大き
> くなるのでは.
> --
> 橋本 剛 (HASHIMOTO, Tsuyoshi)
> Replied: Thu, 03 Sep 1998 13:05:43 +0900
> Replied: Makoto Ishisone <ishisone@sra.co.jp>
宿題
今日できなかった残りの問題を問5まで、以下のサブジェクトでE-Mailで、kono@ie.u-ryukyu.ac.jp まで来週までに提出すること。
Subject: Lecture on Operating System Lecture 1/22
課題
TCP/IPに関する課題 を行うこと。 レポートはメールで
Subject: Practice Operating System Lecture 1/22
というように、課題を出した日付をサブジェクトに入れたメールで提出して下さい。