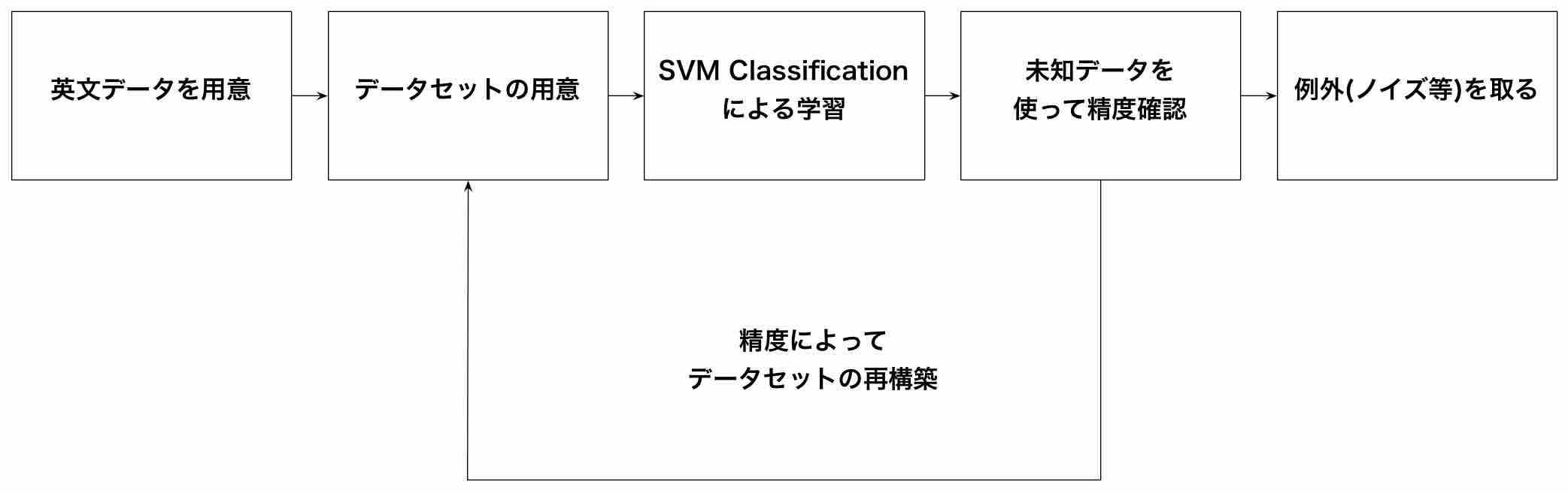
アプローチ方法
伊波 立樹 大井 翔
今回二つの特徴ベクトルを用いたデータセットを作成
タグの比率を特徴ベクトルとしてデータセットを作成
例 : “This is the pen”
| “This” | “is” | “the” | “pen” |
| “DT” | “VBZ” | “DT” | “NN” |
| 限定詞 | 動詞 | 限定詞 | 名詞 |
例 : “This is the pen”
| 形容詞 | 助動詞 | 名詞 | 代名詞 | 動詞 |
| 0 | 0 | 1/2 | 0 | 1/2 |
動詞の前後に注目し, データセットを作成
例 : “I would like you to tell her the truth.”
| “I” | “would” | “like” | “you” | “to” | “tell” | “her” | “the” | “truth” |
| “PRP” | “MD” | “VB” | “PRP” | “TO” | “VB” | “PRP$” | “DT” | “NN” |
| 代名詞 | 助動詞 | 動詞 | 代名詞 | TO | 動詞 | 代名詞 | 限定詞 | 名詞 |
例 : “I would like you to tell her the truth.”
| 前 | 前 | 前 | 前 | 後 | 後 | 後 | 後 |
| 形容詞 | 助動詞 | 名詞 | 代名詞 | 形容詞 | 助動詞 | 名詞 | 代名詞 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 2 |
| 文型 | 比率 | 正答率 |
| 第一文型 | 5/19 | 26% |
| 第二文型 | 7/10 | 70% |
| 第三文型 | 13/33 | 39% |
| 第四文型 | 2/10 | 20% |
| 第五文型 | 17/46 | 36% |
| 文型 | 比率 | 正答率 |
| 第一文型 | 19/19 | 100% |
| 第二文型 | 6/10 | 60% |
| 第三文型 | 2/33 | 6% |
| 第四文型 | 4/10 | 40% |
| 第五文型 | 30/46 | 65% |
| 文型 | 比率 | |
| 第一文型 | 22/33 | 67% |
| 第二文型 | 0/33 | 0% |
| 第三文型 | 2/33 | 6% |
| 第四文型 | 6/33 | 18% |
| 第五文型 | 3/33 | 9% |