Compiler Construction Lecture No.1
Menuこの授業は、WWW と以下のネットニュースを使います。
ura.ie.classes.compilerこの授業中の問題は、
Subject: Report on Compiler consturction Lecture Exercise 1.1などというSubjectのメールにして、kono@ie.u-ryukyu.ac.jp まで送ること。
〆切は来週までです。
コンパイラを書く
簡単なコンパイラを書いてみよう。そして、実際のCコンパイラのソースを読みながらC言語を理解する。Pentinum、PowerPC などのコードを出力するコンパイラをかけるようになろう。(ここまでは簡単) そして、世界最高速のコンパイラを作ろう。(もちろん、これは難しい)
インタプリタとは何か
いろいろな動作や仕様を記述する言語を作る。その言語に従った動作を実現するのがインタプリタである。Websterには、
inerret in-'ter-pret, -pet vb
1: to explain or tell the meaning of: present in understandable terms
とある。日本語では翻訳系などと呼ぶ人もいる。要するに、プログラム言語を実行するシステムがインタプリタである。
例えば、メモりに格納されているPentinumの機械語を実行するのはCPU だが、この場合はRISC CPUがインタプリタに相当する。このCPUは、簡単に言えば、以下のようなことを電子回路によって行っている。
- 一命令をメモりから取ってくる
- その命令で何をすればいいかを解読する
- その命令に必要なデータを取ってくる
- 計算をおこなう
- 結果をどこかにしまう
- 次に実行すべき命令の場所を決める
- 字句解析 単語に相当する部分を切りだす
- 構文解析 SVCなどの文の構造を作りあげる
簡単な言語ならば、構文解析と同時に実行することができる。しかし、同じインタプリタでも機械語の方が簡単に実行できるし、電子回路として実装できるので高速になる。また、プログラムは普通はループなどで同じ所を何回も実行するので、その度に、同じ文を解析するのは効率が悪い。
したがって、字句解析、構文解析を前もって行って、より実行が簡単な言語に変換するのが一般的である。現在ではどんなインタプリタでも、一度、内部コードに変換して実行している。内部コードを小さくするには1 byteを単位にするコード(byte code)を使うことも多い。しかし、CPUにより実行する場合は1 word(4 byte)を単位にするのが普通である。最近では、さらに8byte, 16byte単位で実行を行うVLIW(Very Long Instruction Word)というのもある。
コンパイラとは何か
プログラムを別な言語に変換するシステムをコンパイラと呼ぶ。コンパイルとは編集するという意味である。コンパイラは字句解析、構文解析に関してはインタプリタと同じだが、実行する代わりに、別な言語を生成する。生成自身は難しくない。難しいのは、特定の実行アーキテクチャを想定して、もっとも速く実行できるようなコードを生成することである。
コンパイラが生成する言語は、機械語やバイトコードである必要はない。他の高級言語でも良い。実際、C言語がこれだけ広まっているので、C言語を生成するコンパイラ言語が多数ある。例えば、
- TeXを記述しているWebはCに変換される
- LISPやPrologなどの高水準言語をCに変換する
構文解析や字句解析は、言語を簡単にすることによって、可能な限りさぼることができる。例えば、PostScript は後置記法 (Post fix notation) というのを使って構文解析を簡単にして、printer内部での実行を高速化している。LISPやforth、APL、BASICなども同じ発想で作られている。このような言語は、プログラム自身でプログラムを取り扱うのに向いており、その言語自身のコンパイラを書くのにもっとも適している。実際、インタプリタがあれば、構文解析や字句解析が既に存在しているので、コード生成のみが問題となる。Cなどの複雑な構文を持つ言語は、その点は最悪である。しかし、だからコンパイラを記述するには面白いともいえる。
コンパイラのターゲット
変換の対象はコンパイラのターゲットと呼ばれる。以下のようなターゲットが考えられる。- 実行するCPUの命令パターン (バイナリ)
- インタプリタの仮想コード (バイトコード)
- コンパイラの仮想コード (バイトコード)
- 他の言語 (JavaScript など)
- 他の言語のバイトコード
バイトコード/中間言語を用いる実行は、一つ一つの命令に複雑な機能を割り当てることができる。この複雑な機能を実現すること自身は難しくない。しかし、もし、その機能を機械語に落すとなると、それは簡単ではない。実際には、その機能を実現するライブラリを併用して実現することになる。高機能な言語のコンパイラを作る時には、この実行時ライブラリ(Runtime Library)の実現とその最適化が一番難しい。
Cなどは、言語の機能が機械語に対応しているので、コード生成は容易である。しかし、それを読みやすい形にしていることが構文解析を複雑にしている。
コンパイラとインタプリタの組み合わせ
コンパイラを作る時には、さまざまな方法がある。- まずインタプリタを機械語で作り、その上でコンパイラを作る。
- 作成したコンパイラで、コンパイラ自身をコンパイルする。
このような状況を記述する記法がある。 これは、インタプリタをコンパイラを表している。例えば、プリロセッサを持つコンパイラは以下のように記述される。
これは、インタプリタをコンパイラを表している。例えば、プリロセッサを持つコンパイラは以下のように記述される。 インタプリタを持つコンパイラを自分でコンパイルする。ここで M
は、Machine Language (機械語)を表している。機械語に変換すると、OSはCPUを使って、それを直接実行することができる。
インタプリタを持つコンパイラを自分でコンパイルする。ここで M
は、Machine Language (機械語)を表している。機械語に変換すると、OSはCPUを使って、それを直接実行することができる。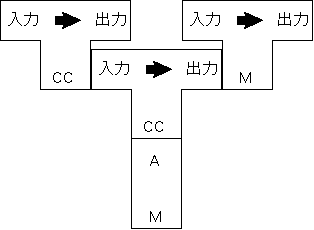
その言語自身が、その言語を実現するのに、どれくらい使われているかは、その言語を評価する一つの基準である。他の言語に依存する度合いが大きい言語は、優れているとはいいがたい。
問題1.1
LLVMのさまざまな出力 clang で、-S と、 -emit-llvm -S で、アセンブラと LLVM バイトコードの出力が得られることを確認せよ。