学生実験2 : 探索アルゴリズムその1
- 更新情報
- 進め方
- コンテンツ
- 1. 探索とは?: Level 1.x (4+8点)
- 2. 連続関数の最適化: Level 2.x (6+8+8点)
- 3. 不連続関数(離散値における)の最適化: Level 3 (12点)
- 4. 目的関数や制約条件が設計されていない問題における探索: Level 4.x (8+12点)
- 5. レポート骨組み
- 6. FAQ
- 参考文献・サイト
- 更新情報
- 内容と目標
-
- 復習を兼ねて、実験1で学んだ技術(スクリプトプログラミング)の応用。
- 人工知能関連科目(人工知能、ニューラルネット、知能ロボット、実験3/4(進化計算、知能ロボット))へのイントロダクション。
- グループ討論、計算機実験を通して探索や最適化のイメージを掴むとともに、計算機実験を効率良く実施するために何を考慮すべきかを理解し、それを実現するための技術について検討する思考を養う。
- 関連技術に関するサーベイ(調査)と応用する技術を養う。
- 目的達成のための手段を提案・調査・検討し、複数代替案の中から適切なアプローチを選択する考察能力を育む。
- 実験の進め方
-
- グループ作業。
各課題についてグループ間で議論し、プログラミング、考察、文書作成等を共同作業で行う事。あるテーマについて議論し、意見をまとめ、行動し、その結果を考察・報告する一連の作業(See also PDCAサイクル)を実施する事も本実験の課題である。作業分担についてはこちらからは指定しないが、各自担当した箇所が分かるように明示する事。
注意: 上記における「担当」や「分担」は、レポート作成上の担当であって、実験担当ではない。全員が実験を実施した上で、レポートとして整理する担当のことである。例えば、AさんがLevel1のレポート作成を担当したとしても、BCDさんがLevel1をやらなくて良い訳ではなく、BCDを含めた全員がLevel1を実施する必要がある。その上で、AさんがLevel1に関するリーダーとなって結果や考察等を整理し、レポートとして書き上げるための役割である。
- 各レベル毎に、「解説→グループ活動(討論、実装、計算機実験、考察)→全体討論(報告会)」を行う。
- グループ作業。
- 評価基準
-
報告会では、主にプレゼンや質疑応答により「コミュニケーション能力と国際性、論理性」を中心に評価する。
レポートでは、指定した課題をこなしている(提出している)事を前提に基準点を設け、以下の項目に沿って加点・減点を行う。参考までに各レベルの点数を掲載することで難易度(求めるレポートの質・量)を示しているが、必須のレベル(オプションと書いてある箇所以外全て)は全てこなすこと。一部の課題をやらなかった場合には、該当レベル分の点数を減じるだけではなく、ペナルティとして-10点をカウントする。
口頭試問(レポート提出時もしくは後日実施)では、レポート概説や質疑応答により「コミュニケーション能力、論理性」を中心に(なるべく個別に)評価する。
レポートの基準点は63点、報告会と口頭試問の両方で10点、合計73点程度である。課題を無難にこなすだけではA(90点〜)にはならない。積極的にオプション課題や関連技術について取り組み、加点を勝ち取るように。
なお、探索アルゴリズム1と2のレポート2つ分の合計得点を200点満点として採点する。このため、例えば探索アルゴリズム1で130点分頑張り、探索アルゴリズム2は70点程度の時間で仕上げる、というように片方に注力するやり方であっても構わない。
加点 - 独自に行った関連課題に関する報告(積極性)。
- 実験中に示した手法ではなく、自力で探し出した異なる手法で問題を解決した場合(積極性・実践性・創造性)。
original/prevenience/traditional を問わないが、実験が主目的であるため可能な限り動かすよう努力すること。サンプルソースやツール等が動かない場合にはその原因究明についてレポートする事も一つの報告方法である。
- 手法の利点・欠点や限界等に関して自主的にトライした結果・考察が示されている場合(積極性・専門性)。
- レポートの見せ方に関する工夫や、グループ作業に伴う支援ツール等の利活用(コミュニケーション能力)。
- その他、本テーマに関連する実験的側面上「積極性・実践性・創造性・コミュニケーション能力」等の観点から評価できるもの。
減点 - 先行研究や事例、レポート、web等を参照しているにも関わらず、それらを参考文献として参照していない場合(一般倫理)。
- 論理的矛盾が見られる場合(論理性)。
- 結果を示さずに考察のみを記載してたり、結果に対する考察に整合性が見られない場合(コミュニケーション能力)。
- タイプミスや可読性の欠如(特に、図が読めないレポート多し!)、数式等記号の印字ミス、提出期限の遅れ等、多方面に関して大きな誤りではない場合。
- 提出遅延に関しては減点ではなく「原則として受け付けません」。
何らかの理由で間に合わない場合にはホウレンソウ(報告/連絡/相談)。 相応の理由がある場合には可能な範囲で事前に連絡相談してください。 事情に応じて後日でも構いませんが、なるべく早く報告してください。一般社会の常識です。
- 課題と提出方法
-
- オプションを除く全ての Level にトライし、レポートとしてまとめよ。その際(もしくは後日)、レポートに関する簡単な口頭試問を行うので、口頭試問の期日に関して別紙/メールにて予約をする事。口頭試問の実施日期限は、目安としてレポート提出日+1週間程度。早めでも構いませんが、遅くなるのはできるだけ避けること。
- 1グループ1レポート提出&口頭試問。
- メンバ(氏名・学籍番号)と担当内容を記載すること。
- 提出物は以下の2つです。それらを「groupX」というフォルダに準備し、規定の場所に提出(アップロード)してください。印刷する必要はありません。
- 提出物1: レポートファイル
補足:LaTeXで作成し、PDF化したもの。
- 提出物2: 図やプログラム等の関連ファイル一式を圧縮したもの
補足:tar.gz で圧縮する事。
- 提出物1: レポートファイル
- 提出(アップロード)の手順:3ステップあり。
[手順1] 上記2つを「shell:~tnal/2012-search1-xxx/(xxxは下記参照)」に rsync で提出してください。保存する際のディレクトリ名は「groupX」のようにグループ名を使用する事。
例えば、MacBook 上の ~/group1/ に提出物を保存しているならば、以下のように rsync する事で提出できます。 rsync 自体の説明は例えばここを参照してください。# 実施日によってアップロード先が異なります! # 月曜日のクラスは「2012-search1-mon」へ。 prompt> rsync -auvze ssh ~/group1/ \ e1157xx@shell:/net/home/teacher/tnal/2012-search1-mon/group1/ # 金曜日のクラスは「2012-search1-fri」へ。 prompt> rsync -auvze ssh ~/group1/ \ e1157xx@shell:/net/home/teacher/tnal/2012-search1-fri/group1/ # 注意: # ・上記の例ではコマンドが長いためバックスラッシュ「/」で区切り、 # 2行に分割して書いています。 # ・スラッシュの有無で引数の意味が大きく異なります。 # ・アップロードはグループ代表者一人が行ってください。 # パーミッションの都合上、レポート修正した後の再アップロードも # 同じ代表者じゃないとアップロードできません。
[手順2] 提出後、提出報告をメールにて連絡ください。
メールの件名は「(search1/mon/group1)」のように、テーマ名(search1)、 曜日(monもしくはfri)」、グループ番号、を含めるようにしてください。
[手順3] メールと提出ファイル一式を確認次第リプライを返します。
- プログラムのコードや実験結果をレポート中に含める場合には、必要十分に留めること。不必要に全ソースを掲載するのは×。
- レポート提出期限:予備日(レポート作成日)に設定していますが、月曜クラスは
1/14(月)1/17(木)、金曜クラスは1/18(金)とする。(探索アルゴリズム2も同一日です)提出期限を過ぎたら、原則的に、受け取りません。 期限内に仕上げる事も重要なタスクです。 ただし、一般社会でも通用する理由で遅れてしまう場合にはこの限りではありませんので、なるべく早く相談してください。
- 口頭試問期限:レポート提出から1週間の期間を目安に、グループメンバ全員一緒に、705室にて口頭試問を受けること。口頭試問の実施日は、空き時間目安ページ(後でURLを掲載します)を参考の上、レポート提出メールを送る際に希望日を連絡て下さい。
- 採点後、優秀なレポートを期間限定で公表します。
- Level 1.1 : コンピュータと人間の違いを述べよ (4点)
-
コンピュータが人間より得意とするモノは何だろうか?逆に、人間より不得手のモノは?
注記:レポートでは、各々2つ以上を列挙して説明する事。
- 探索: 指定された探索範囲内から目的物を探し出す事。
- 探索範囲: 探し出す情報源(解空間)。制約条件等によっては一部分のみが探索範囲となることもある。
- 目的物: ユーザが望むモノ。
- 目的関数: 目的物が最適値となるように設計された関数。目的物以外のものについては、目的物との合致具合(≒近さ)に応じたスコアを返すことが多い。(例: 「最適な仕様とは何か」「そもそも何をもって最適であると判断するか」)
- 制約条件: 目的物を探し出す際の条件。探索範囲に直接影響があるものだけではなく、時間的制約等の間接的な条件もありえる。
- 探索アルゴリズム: 探索のための手続きや方法。
- 探索システム: 指定された解空間・制約条件内において、指定のアルゴリズムを用いて目的物を探し出すシステム。必ず入力・内部モデル・出力を伴ったものとなる。
- Level 1.2 : 具体事例を挙げ、「探索」という観点から考察せよ (8点)
-
システムが実世界または仮想世界で作業をする問題(具体事例)を1つ挙げ、「データの集まりから条件に合うものを見つけ出す」ような事例について、探索という観点から考察せよ。該当システムに「**機能が追加されるとより便利になる。この機能を実現するには・・・」といった提案形式でも構わない。
具体事例の例
ここでいう具体事例とは、 例えば、ルンバのように「どのように自走するか、どのように掃除するか」を内蔵しているロボット(の機能)や、 レスキューロボットのように人間と共同作業を効果的に行うために「環境をどのようにセンサリングし、その値(状況)に応じてどの行動を実行するのが最適か」に関する検討でも構わない。 また、必ずしもロボットのような体を有するシステムである必要はなく、 コンピュータチェスのように「ある盤面において有効な手は何か」を決定する手法でも、 Google等の検索エンジン・広告、 Amazonのお勧め商品・Amazonおまかせリンク(TM)、 はてなやYouTubeの検索(タグ機能)、 エスエス製薬のカゼミルプラス(TLから風邪話題度をチェック) のように、電子媒体を情報源とするものでも構わない。
レポートには以下の項目を含めること。- 探索対象に対して・・・
- 解空間の説明:例えば、探索対象やその範囲等に関する定義や説明、この問題ならではの特徴等。
- 探索目的(目的物)の説明。
- 探索方法の説明(or提案)。
- オプション: 上記3点をまとめたシステム全体の概略図。e.g., ポンチ絵
- 参考にした文献/Webサイト等があれば、必ず示す(参考文献として列挙し、参照する)こと。
- 探索対象に対して・・・
- Level 1.x: 問題解決(オプション)
-
人間と全く同じことができるのであればただのマンパワーとして考えれば良いが、コンピュータはそうではない。 では、コンピュータに取って都合の良い解決方法があるのだろうか?
そもそも人間の行っている問題解決とは? どうすればそれを工学的に実現できるか?
- Level 2 : 連続関数における探索手法を検討し、最適性と効率性について考察せよ。
-
Level 2.1 〜 2.3 に示した関数について、最急降下法により最小値を求めるプログラムを作成し、計算機実験により評価し、結果を示した上で考察せよ。
なお、最適解を求める(発見する)にあたり、出発点となる解はランダムに選ばれるものとする。
実装時のヒント
- 微分値を利用する際、目的関数 f(x) を微分した関数 f'(x) はプログラマが設定して良い。(任意の関数 f(x) を微分出来るように実装する必要は無い)
- 微分値が正の値の場合、最適解(最小値)は相対的にどの位置にあるか?同様に、負の値を取る場合にはどの位置にあるかを考えて実装せよ。言い換えると、「現在地 xi の微分値を求め、その値に応じて x 軸のどの方向へ探索するかを決定する必要がある。
- 微分値を基に x を移動させる幅を決定する際、「xnext = x -α*f'(x)」とせよ。学習係数αは 0 より大きい実数とし、この値を変更する事でどのように探索が行われるかを観察せよ。
- x の探索範囲は「-10 <= x <= 10」とする。
- サンプルソース:search1-sample.tar.gz
ランダムな初期位置の決定、指定した回数分探索を行う、定義域内を外れたら終了、の3点は実装済。詳細はソース内の 0README_ja.txt や、上記の「実装時のヒント」を参照。
f(x), f'(x) 及び x の移動方法を実装し、実験せよ。
注記:レポートには下記4点を含めて報告すること。
- [Level2.1~2.3共通] 探索の手続き、フローチャート。
2.1~2.3で共通している報告事項はまとめて報告すること(同じ報告を繰り返す必要はありません)。
- プログラムソース(スクリプトを含む)。
レポート内には変更個所のみを記載した上で、ソース全体はアップロード提出すること。
- 実行結果。
無駄に全てを示す必要はなく、第三者が読んでも理解できる程度に、必要十分に示すこと。
- 考察。
特に「学習係数が探索挙動に及ぼす影響」として「得られた解の質」と「効率性」について考察すること。 (どう検証したら良いだろうか?)
必要に応じて適切な図表を作成し、理解しやすい考察となるようにすること。
- Level 2.0 : y = x (例題)
-
例題のためレポートには不要です。

- Level 2.1 : y = x2 (6点)
-

- 「傾きが0となる点」から最適解(最小値となる解)を求めた方が早い例。
- Level 2.2 : y = x^2 + exp(x) (8点)
-
.svg)
- Level 2.2 のように「傾きが0となる点」を求めることができるなら求めた方が早い。Level2.3のケースでは求めることができるだろうか?
- Level 2.3 : y = x*cos(x) (8点)
-
.svg)
- ランダムな解からスタートするため、Level 2.4 のような多峰の関数においては必ずしも最適解を発見できるとは限らない。このような場合、どのようにしたら最適解を獲得しやすくなるだろうか?
- Level 2.x: オプション
-
- 結果の集計・解析ツール(言語は問わない)の作成と利活用。ソースにはコメントを付けること。
- 最急降下法以外の手法を実装する場合には、手法名・概要を説明した上で結果・考察を示す事。オリジナルの手法ならば詳細に説明する事。
- Level 3 : 不連続関数における探索手法を検討し、その探索挙動について考察せよ。 (12点)
-
コメント
- 実装は必須ではないが、加点対象とする。
- 一般的に、組み合わせ最適化問題は探索空間が広すぎるため、「必ず最適解を発見する」という保証は出来ない。今回は、何らかの点で全探索よりも性能が良い事を示せる手法であればOKとする。
- Level 3 は要素数の増加に伴い問題空間が指数関数的に増加する。このような問題を組み合わせ最適化問題と呼ぶ。組み合わせ最適化問題の場合には、問題空間があまりにも広大すぎるために「可能な限り無駄な探索を省く事で探索領域を狭め、効率良く良質な解を探し出す」事を目指す必要がある。
- 問題空間の特徴(解を構成する要素の増加に伴う問題空間サイズの増加具合を図示すること)。
- 探索の手続き、フローチャート。
- 提案手法の利点・欠点。
- Level 3 : ナップサック問題 (12点)
-
概要: 複数の品物(それぞれの品物は、重さと値段が事なる)が与えられた時、重さがナップサックに入る最大重量以内でなるべく合計の値段が最大になるような品物の組み合わせを求めよ。
目的関数: ナップサックに入れた荷物の総価値。
制約条件: (1)最大重量MAXを越えないこと。(2)同じ荷物は一つしか入れられないこと。
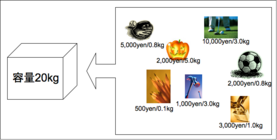
- 品物の数が3個の時、解 x は 001(1つ目をナップサックに入れる)、011(1つ目と2つ目をナップサックに入れる)という表現で表すことができる。すなわち、同じ荷物を複数回ナップサックに入れることは考慮しない。
- 品物の数が3個の時の問題空間サイズは?4個の時は?N個の時は?
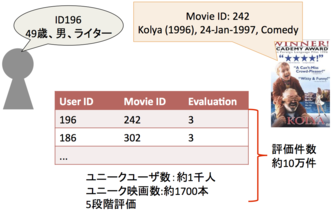
- Level 4 : MovieLensデータセットを例に、ユーザに対して映画を推薦するための目的関数や制約条件について検討せよ。 (8+12点)
-
MovieLensデータセットとは、情報推薦における推薦精度の良さを評価するために用いられる一つのベンチマーク的なデータである。例えばMovieLens 100k Data Setでは「943人ユーザが1682本の映画について評価した10万件分のデータ」が収められている。具体的には「ユーザID196番は映画242番について5段階評価で3と評価した」といったデータが10万件分揃っている。
MovieLensデータセットに含まれるデータいろいろあるが、ここでは以下の情報が分かっているとしよう。冒頭の「u.data」等はデータセットに含まれているファイル名である。
- u.data: 10万件分の評価値(ユーザID, 映画ID, 5段階評価値)。
- u.user: ユーザ情報(ユーザID, 年齢, 性別, 職)。
- u.genre: 映画のジャンル情報(不明を含めて19ジャンル)。なお、ジャンルは複数を取りうる。
- u.item: 映画情報(映画ID, タイトル, リリース年, URL, ジャンル)。
ストーリー
具体的にファイルの中身を見る必要はないが、上記情報があるという前提で「映画の推薦」により売り上げやレンタル数の向上を狙いたい。デタラメな映画を推薦すると逆効果となり顧客離れを引き起こす可能性が高いため、ユーザが好むであろう映画を推測し、推薦したい。
ユーザが好むであろう映画を推測するため、ユーザの映画に対する評価履歴を利用して、そのユーザがどのような映画に対して高評価もしくは低評価しているかを嗜好モデルとして構築したとしよう。例えば、「ee_i = f(m_i)」のように「映画(m_i)を引数として与えると、その映画に対する推定評価値(ee_i)を出力する」ような関数f(m_i)(=嗜好モデル)を構築したとする。
以上を踏まえた上で以下の項目2点について検討せよ。
- [ Level 4.1: 設計したユーザ嗜好モデルの評価方法 ] 構築した「嗜好モデルf(m_i)」が目的にどのぐらい適したモデルとなっているかを評価したい。(1)評価方法を示し、(2)その方法で評価したい理由を説明せよ。
(視点例) できるだけユーザの高評価を外さないように推定できると高得点となるようにするには?
(視点例) ユーザが評価していないジャンルの映画を高評価として推定できると高得点となるようにするには?
- [ Level 4.2: 嗜好モデルの構築方法 ] Level4.1で検討した評価方法において高得点をとれることを期待できる「嗜好モデルf(m_i)」について検討せよ。レポートには、(1)嗜好モデルの説明に加え、(2)そのモデルの利点および欠点について述べよ。
(視点例) ユーザが高評価とした映画を同じように高評価と推定するには?
- ダウンロード: reportskel-search1.tgz
- 骨組みをコンパイルして生成できるPDFファイル: search1-utf8.pdf
- コンパイル方法
prompt> make
- Level1編
- Q: Level1.2の具体事例として「hogehoge(何かしらの新機能)」を提案したら何でも良いのですか?
- A: 「探索」という観点で考察できるならOK。
- Level2編
- Q: 実験中のグループ活動で何をやって良いのか分からない。
- A: サンプルプログラムは「最急降下法で y=x における最小値を探索する」ように書かれています。そこで、まずはLevel2.1なり問題を選択して、その問題を解くようにプログラムを修正する必要があります。
[step1] プログラムの修正
まずはLevel2.1, 2.2, 2.3どれでも良いので一つ選択し、選択した関数におけるy=f(x)とy'=df(x)に書き換えて動作するようにしましょう。適切に動いているかは「xとyの関係」だけで判断できるはずです。
[step2] パラメータを変更して動作観察
想定した関数上で探索が進んでいることを確認したら、alphaやseedを変更して探索動作がどのように変わるかを観察しましょう。どちらを変更するかは「何を観察したいか」で選ぶことになります。alphaは「探索点の移動幅を調整するパラメータ」です。seedは「初期探索点を選ぶためのパラメータ」です。移動幅を大きくした時に探索点の移動がどのように変わるかを観察したいのならalphaを選択(変更)するべきでしょう。出発点を変えたときにどのように探索動作が変わるかを観察したいならseedを選択(変更)するべきでしょう。いきなり複数のパラメータを変更してしまうと、どちらのパラメータがどのように影響しているかを観察することが難しくなるため、一般的には「一つのパラメータの影響」を観察している最中は他のパラメータを固定しておき、観察対象のパラメータだけを少しずつずつ変更していき、傾向を探ることになるでしょう。今回は「最適性」と「効率性」という視点で考察できるように実験計画を練ってみてください。
- Level3編
- Q: 「Level 3 : (中略) (12点)」と2カ所に書かれているが、どちらをやれば良い?
- A: 紛らわしくて申し訳ありません。2つで一つの課題です。ナップサック問題を対象として「問題空間の特徴、探索の手続き、利点・欠点」を検討してください。
- Q: Level3は12点+12点の24点?
- A: 前述の通り2つで1つの課題で、合計12点です。
- Q: 「(準)最適解」とは?
- A: 真の最適解ではないが、それに準じる程度には許容できる質の高い解です。近似解とも呼びます。Level3の「組み合わせ最適化問題」では真の最適解を見つけること自体が困難なため、近似解を求める手法を検討することが多いです。
- Q: 「探索の手続き」における「手続き」とは?
- A: 探索して目的物を探しだすための手順のことです。
- Level4編
- Q: Level4.1と4.2は何が違う?
- A: Level4.1では「モデルの良さをどう評価するか(評価方法)」。Level4.2では「4.1で高評価となるようなモデルの構築方法、推薦手法」を問うています。自由度が高い(制約が少ない)こともあり、「評価方法」の説明で「**という推薦ができたものを高く評価したい」というように「評価方法と推薦手法が密接に結びつく」ことがあり得ます。逆に言うとそうじゃないこともあり得るのですが、今回のレポートとしては「Level4.1では評価方法という観点」、「Level4.2では推薦手法という観点」から筋が通るように説明がされていれば、同一になってしまっても構いません。
- Q: Level4.1の「評価方法」の意味が分からない
- A: 例えば、Level2では与えられた関数における最小値を求めることが目的でした。探索範囲は-10<=x<=10です。この範囲内における任意のxは解候補です。例えば「x=0.1」というのは一つの解候補ですが、これはどのぐらい「目的関数に適合しているか」が分からないと、解の良さ(質)を判断することができません。Level2.1ではその「解の良さ」を測る指標(=目的関数)として「y=x^2」が与えられています。この目的関数にx=0.1を代入すると「y=0.01」が得られます。つまり、「目的関数y=x^2」は「解候補xの良さ」を評価しています。
Level4に話を戻すと、映画を推薦するためのモデル f(m_i) をどうやって評価するかを検討する必要があります。「1週間そのモデルで推薦を試してみて購買やレンタル数の改善度合いで評価する」みたいなのも一例になり得るでしょう。いろんな推薦手法が考えられますが、その手法がどのぐらい適切なのかを確認(評価)するためには指標が必要です。その指標を考えて欲しい、評価方法を考えて欲しいというのがLevel4.1の趣旨になります。 - 参考文献・サイト
-
- 口頭試問調整用の記事
- 情報工学実験2/探索アルゴリズム1の口頭試問日調整(後でURLを書き直します)
- スクリプト等、実験環境関連
- google keywords: perl, ruby, gnuplot
- 実験1: Shell script と gnuplot の参考文献・サイト
- Gnuplot入門
- 探索関連
- google keywords: 探索、最適化、連続関数、微分、不連続関数、近似解法
- AI リンク集@人工知能学会
- 人工知能のやさしい説明「What's AI」@人工知能学会
- 非線形計画法@電気電子工学科・半場先生
- MovieLens
- MovieLens Data Sets(GroupLens Research)
- 集合知プログラミング 2章 その11 MovieLensのデータを使った推薦をしてみる
- UML
- その他
- 口頭試問調整用の記事
進め方
1. 探索とは?
1.1. 前提1: コンピュータと人間の違い
(探索が何なのかを考える前に・・・) コンピュータを利用して効率良く問題解決したい。 特に、ここでは AI で対象とする問題を解決するための一般的枠組みについて検討する。
1.2. 前提2: 探索問題の定義
2. 連続関数の最適化
コンピュータで解決するには?
どれだけ計算資源を割り当てることができるのか、どれだけ時間資源を割くことができるのかといったコストの観点を捨て去ることはできないが、理想的には、無駄無く適切な解を求めたい。
問題意識: 効率良く最適解(目的物)を探し出すにはどうしたら良いだろうか?
Level2.xでは、解空間が連続値であり、目的関数や制約条件が数式として定義されているという前提で「最適値を効率良く求める」ことについて理解を深めていこう。
3. 不連続関数(離散値における)の最適化
Level 3 に示した問題は解空間が離散値で構成されており、直接的には微分を求めるアプローチを適用することができない。Level2との違いは「解空間が離散値」という点のみであり、目的関数や制約条件はLevel2同様に数式として定義されている。このため、「任意の解」を選択したのならその解の良さ(目的関数による評価値)や、制約条件を満足しているかどうかは算出可能である。
上記の点を踏まえ、解空間(x軸)全てを調べることなく、一部分を調べることで質の良い(準)最適解を効率良く求めるにはどうすれば良いか、検討せよ。
4. 目的関数や制約条件が設計されていない問題における探索
Level2, Level3では目的関数や制約条件が設計済みであり、検討対象は解空間における最適解(や準最適解)の探索手法だけで良かった。一方、より具体的な例として、Amazonや楽天のようなオンラインショップにおいて「(例えば)ユーザが興味を持つような商品を推薦」する際には、目的関数や制約条件自体の設計から取り組む必要がある。
Level4では、MovieLensデータセットを例に、目的関数や制約条件から検討してみよう。