ステージ2-5: 半教師あり学習の練習 (label_propagation.LabelSpreading) (情報工学実験 3 : データマイニング班)
目次- 想定環境
- データセットの用意
二重の同心円上にデータ(サンプル)を並べ、内側と外側の円上で最短距離にあるサンプル2点のみに教師信号を設定する。
- case 1: 2点にのみ教師データを用意し、残りを「ラベルが無いデータ」として半教師あり学習を適用してみる
- case 2: (平等な条件ではないが)教師あり学習(svm.SVC)でも試してみる
- case 3: (平等な条件ではないが)教師無し学習(cluster.KMeans)でも試してみる
想定環境
- OS: Mac OS X 10.8.x (10.7.x以降であれば同じ方法で問題無いはず)
- Python: 2.7.x
- Mercurial: 2.2
- Scikit-learn: 0.13.1 (sklearn.__version__)
- matplotlib: 1.3.x (matplotlib.__version__)
- numpy: 1.8.0 (numpy.version)
- scipy: 0.13.0 (scipy.version)
データセットの用意
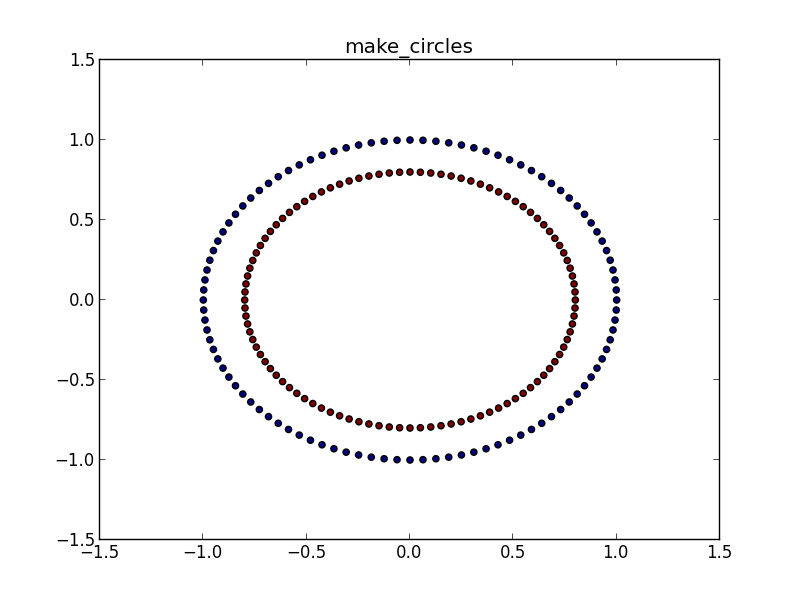
- make_circles(): 2次元空間に二重円上にサンプルを配置。ラベルは内側の円(label=-1)と外側の円(label=0)の2種類が設定される。
import numpy as np
from sklearn.datasets import make_circles
n_samples = 200
data, target0 = make_circles(n_samples=n_samples, shuffle=False)
# make_circles() がどういうデータを生成したのかを確認してみる。
# dataは2次元特徴ベクトル:
# targetは教師データ: 前半=0, 後半=1
import pylab as pl
pl.figure()
X = data[:,0]
Y = data[:,1]
labels = target0
pl.title("make_circles")
pl.scatter(X, Y, c=labels)
#pl.show()
pl.savefig("fig0_make_circles.svg")
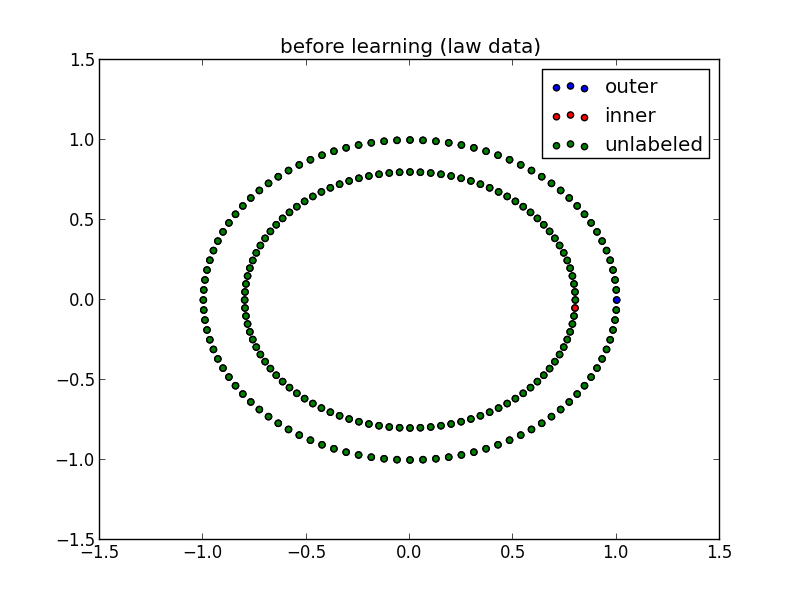
 # 半教師あり学習用にラベルを設定し直す。
# 教師データ2種:
# 内側と外側の円上で最短距離にあるサンプル2点のみに教師信号を与える。
# 外側の円(outer): label=0
# 内側の円(inner): label=1
# それ以外のデータは未知ラベルとして-1を設定
target1 = - np.ones(n_samples)
unlabeled = -1
outer = 1
inner = 2
target1[0] = outer
target1[-1] = inner
pl.figure(1)
pl.title("before learning (law data)")
pl.scatter(X[:,target1==outer], Y[:,target1==outer], c='b', label='outer')
pl.scatter(X[:,target1==inner], Y[:,target1==inner], c='r', label='inner')
pl.scatter(X[:,target1==unlabeled], Y[:,target1==unlabeled], c='g', label='unlabeled')
pl.legend()
#pl.show()
pl.savefig("fig1_lawdata.svg")
# 半教師あり学習用にラベルを設定し直す。
# 教師データ2種:
# 内側と外側の円上で最短距離にあるサンプル2点のみに教師信号を与える。
# 外側の円(outer): label=0
# 内側の円(inner): label=1
# それ以外のデータは未知ラベルとして-1を設定
target1 = - np.ones(n_samples)
unlabeled = -1
outer = 1
inner = 2
target1[0] = outer
target1[-1] = inner
pl.figure(1)
pl.title("before learning (law data)")
pl.scatter(X[:,target1==outer], Y[:,target1==outer], c='b', label='outer')
pl.scatter(X[:,target1==inner], Y[:,target1==inner], c='r', label='inner')
pl.scatter(X[:,target1==unlabeled], Y[:,target1==unlabeled], c='g', label='unlabeled')
pl.legend()
#pl.show()
pl.savefig("fig1_lawdata.svg")


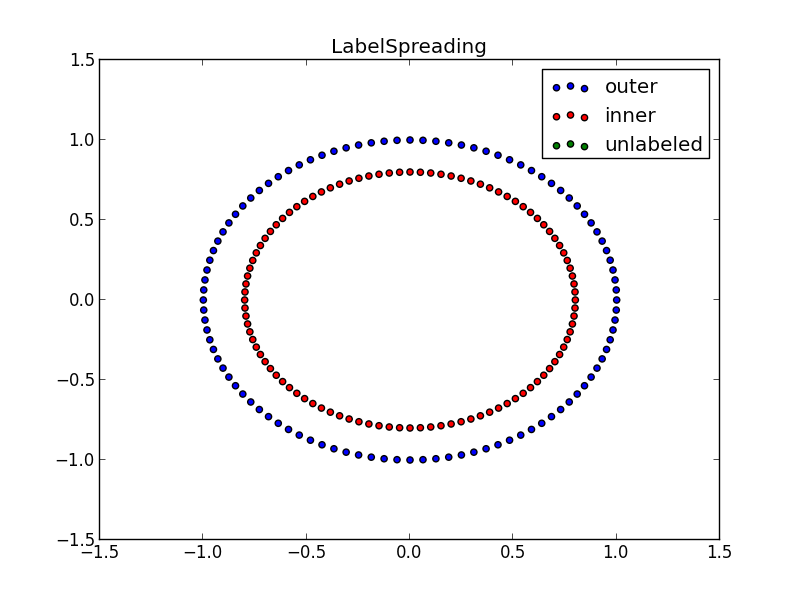
2点にのみ教師データを用意し、残りを「ラベルが無いデータ」として半教師あり学習を適用してみる
- label_propagation.LabelSpreading: 半教師あり学習の一種。
# 半教師あり学習(label_propagetion.LabelSpreading)を実行。
# unlabeled がどうなったかを確認。
from sklearn.semi_supervised import label_propagation
label_spread = label_propagation.LabelSpreading(kernel='knn', alpha=1.0)
label_spread.fit(data, target1)
output_labels = label_spread.transduction_
pl.figure(2)
pl.title("LabelSpreading")
pl.scatter(X[:,output_labels==outer], Y[:,output_labels==outer], c='b', label='outer')
pl.scatter(X[:,output_labels==inner], Y[:,output_labels==inner], c='r', label='inner')
pl.scatter(X[:,output_labels==unlabeled], Y[:,output_labels==unlabeled], c='g', label='unlabeled')
pl.legend()
#pl.show()
pl.savefig("fig2_LabelSpreading.svg")

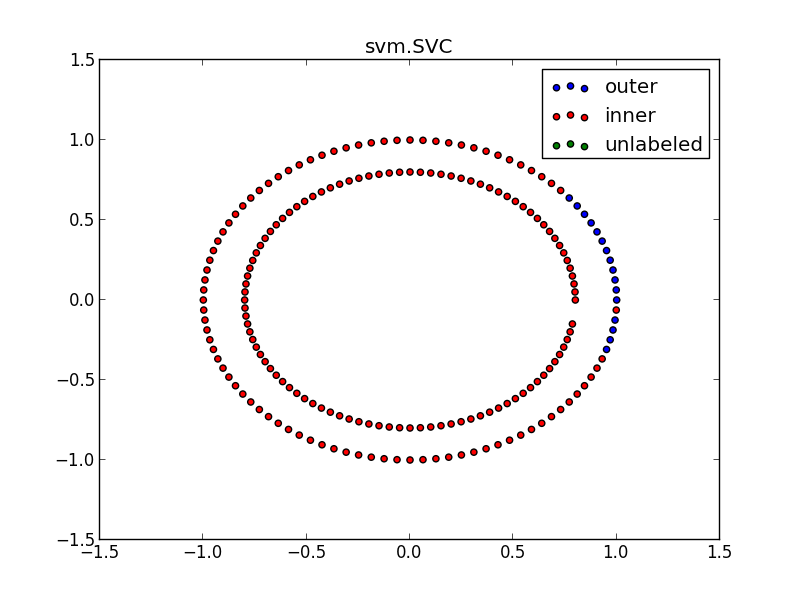
(平等な条件ではないが)教師あり学習(svm.SVC)でも試してみる
# 類似条件(2点のみ教師データあり)で教師あり学習(svm.SVC)を試してみる。
# 教師あり学習の場合には「教師データが無いデータ」は学習時に提示できない。
# その状況で学習したモデルを使って、unlabeled がどうなるかを確認。
def filter(data, target, label):
u'''labelで指定されたtarget値を持つdataのみを抽出。
ここでは教師データを付与したtarget[0], target[-1]に該当するdata[0], data[1]
のみを切り出せば十分なので手動でやっても良いが、汎用性のある関数として記述した例。
'''
filtered_list = []
samples = data[target==label].tolist()
for sample in samples:
filtered_list.append(sample)
return filtered_list
# 教師データを付与した2点のみで学習用データセット(data2, target2)を構築。
# 残りの未ラベルデータでテスト用データセット(data2_test)を構築。
data2 = filter(data, target1, inner) + filter(data, target1, outer)
target2 = filter(target1, target1, inner) + filter(target1, target1, outer)
data2_test = filter(data, target1, unlabeled)
from sklearn import svm
clf = svm.SVC(gamma=0.001, C=100.)
clf.fit(data2, target2)
output_labels2 = clf.predict(data2_test)
pl.figure(3)
pl.title("svm.SVC")
pl.scatter(X[:,output_labels2==outer], Y[:,output_labels2==outer], c='b', label='outer')
pl.scatter(X[:,output_labels2==inner], Y[:,output_labels2==inner], c='r', label='inner')
pl.scatter(X[:,output_labels2==unlabeled], Y[:,output_labels2==unlabeled], c='g', label='unlabeled')
pl.legend()
#pl.show()
pl.savefig("fig3_SVC.svg")
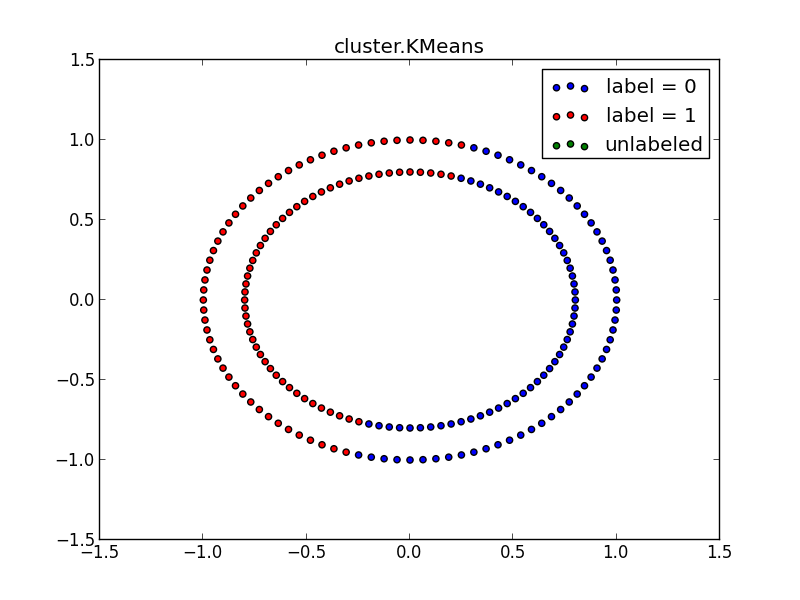
(平等な条件ではないが)教師無し学習(cluster.KMeans)でも試してみる
# 教師なし学習(cluster.KMeans)を試してみる。
from sklearn import cluster
k_means = cluster.KMeans(n_clusters=2)
k_means.fit(data)
output_labels3 = k_means.labels_
pl.figure(4)
pl.title("cluster.KMeans")
pl.scatter(X[:,output_labels3==0], Y[:,output_labels3==0], c='b', label='label = 0')
pl.scatter(X[:,output_labels3==1], Y[:,output_labels3==1], c='r', label='label = 1')
pl.scatter(X[:,output_labels3==unlabeled], Y[:,output_labels3==unlabeled], c='g', label='unlabeled')
pl.legend()
#pl.show()
pl.savefig("fig4_KMeans.svg")