元のページ
ステージ2-4: クラスタリング、3次元グラフ描画演習 (cluster.KMeans, cluster.Ward + Axes3D) (情報工学実験 3/4 : データマイニング班)
目次
想定環境
- OS: Mac OS X 10.8.x (10.7.x以降であれば同じ方法で問題無いはず)
- Python: 2.7.x
- Mercurial: 2.2
- Scikit-learn: 0.14.1 (sklearn.__version__)
- matplotlib: 1.3.0 (matplotlib.__version__)
- numpy: 1.9.0.dev (numpy.version)
- scipy: 0.14.0.dev (scipy.version)
クラスタリングし、結果を簡易観察する (cluster.KMeans)
from sklearn import datasets
iris = datasets.load_iris()
data = iris.data
target = iris.target
# K-means(k=3)でクラスタリングしてみる。
# クラスタリング結果(ラベル付与結果)は estimator.labels_ に保存される。
# 簡易評価として target との違いを目視チェック。
# list[start:end:step]
from sklearn import cluster
k_means = cluster.KMeans(n_clusters=3)
k_means.fit(data)
print k_means.labels_[::10]
print target[::10]
# fit する度に labels_ の結果は変わりうる。
# labels_とtargetの出力を比較した結果はどう解釈できる?
特徴ベクトルの要素において相関の高い上位3件を選択し、3次元グラフ描画してみる (Axes3D)
# data <-> target の関係を可視化してみる。
# dataは4次元のデータセット。
# 相関が高い上位3次元をxyz座標とし、target3種(0,1,2)を色で区別する。
import numpy as np
np.corrcoef(data[:,0], target)
np.corrcoef(data[:,1], target)
np.corrcoef(data[:,2], target)
np.corrcoef(data[:,3], target)
# -> 相関が高いのはdataの0番目, 2番目, 3番目。
# data3次元 <-> taregt(正解データ) での3次元グラフ化
import pylab as pl
from mpl_toolkits.mplot3d import Axes3D
fig = pl.figure(1)
# Axes3D
# X,Y,Z座標毎にデータをリストで用意し、
# cで色を指定。
ax = Axes3D(fig)
X = data[:,0]
Y = data[:,2]
Z = data[:,3]
labels = target
ax.scatter(X, Y, Z, c=labels)
ax.set_xlabel("sepal length")
ax.set_ylabel("petal length")
ax.set_zlabel("petal width")
#pl.show()
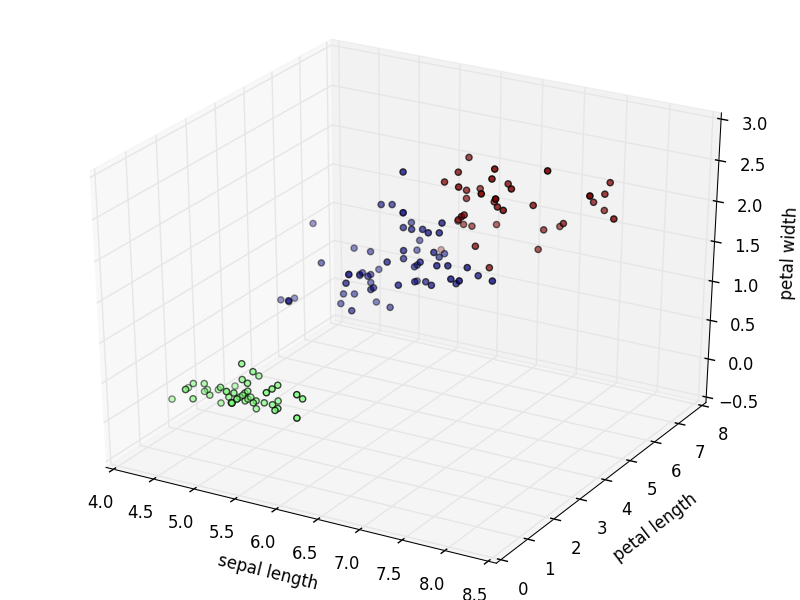
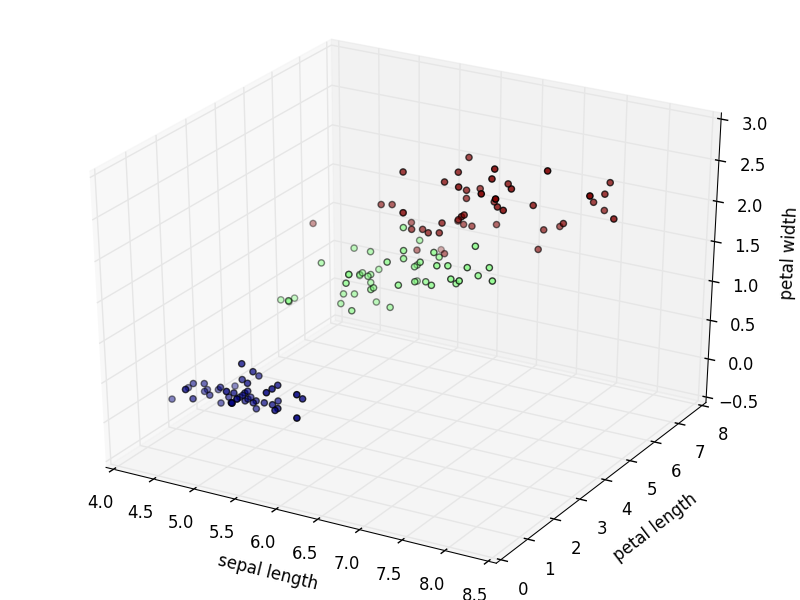 # クラスタリング結果を描画
fig = pl.figure(2)
# Axes3D
ax = Axes3D(fig)
X = data[:,0]
Y = data[:,2]
Z = data[:,3]
labels = k_means.labels_
ax.scatter(X, Y, Z, c=labels.astype(np.float))
ax.set_xlabel("sepal length")
ax.set_ylabel("petal length")
ax.set_zlabel("petal width")
pl.show()
# クラスタリング結果を描画
fig = pl.figure(2)
# Axes3D
ax = Axes3D(fig)
X = data[:,0]
Y = data[:,2]
Z = data[:,3]
labels = k_means.labels_
ax.scatter(X, Y, Z, c=labels.astype(np.float))
ax.set_xlabel("sepal length")
ax.set_ylabel("petal length")
ax.set_zlabel("petal width")
pl.show()
階層型クラスタリング(Ward法)の例
from sklearn import datasets, cluster
import numpy as np
iris = datasets.load_iris()
data = iris.data
target = iris.target
# Ward(n_clusters=3)でクラスタリングしてみる。
# クラスタリング結果(ラベル付与結果)は estimator.labels_ に保存される。
# 簡易評価として target との違いを目視チェック。
ward = cluster.Ward(n_clusters=3)
ward.fit(data)
print ward.labels_[::10]
print target[::10]
参考サイト一覧