元のページ
ステージ2-3: モデルのパラメータ調整の演習 (estimator.set_params) (情報工学実験 3/4 : データマイニング班)
目次
想定環境
- OS: Mac OS X 10.8.x (10.7.x以降であれば同じ方法で問題無いはず)
- Python: 2.7.x
- Mercurial: 2.2
- Scikit-learn: 0.14.1 (sklearn.__version__)
- matplotlib: 1.3.0 (matplotlib.__version__)
- numpy: 1.9.0.dev (numpy.version)
- scipy: 0.14.0.dev (scipy.version)
データセットの用意
# データセット diabetes を3分割交差検定で用意
from sklearn import datasets
diabetes = datasets.load_diabetes()
data = diabetes.data
target = diabetes.target
from sklearn import cross_validation
import numpy as np
kfold = cross_validation.KFold(n=len(data), n_folds=3, shuffle=True)
# Ridge 線形回帰 (誤差関数にペナルティ項導入)
# パラメータ alpha の影響を観察してみる。
# 他のパラメータはデフォルト値のままで固定。
from sklearn import linear_model
regr = linear_model.Ridge()
alphas = np.logspace(-4, 0, 10)
scores = []
scores_std = []
for alpha in alphas:
regr.set_params(alpha=alpha)
this_score = cross_validation.cross_val_score(regr, data, target, cv=kfold, n_jobs=-1)
scores.append(np.mean(this_score))
scores_std.append(np.std(this_score))
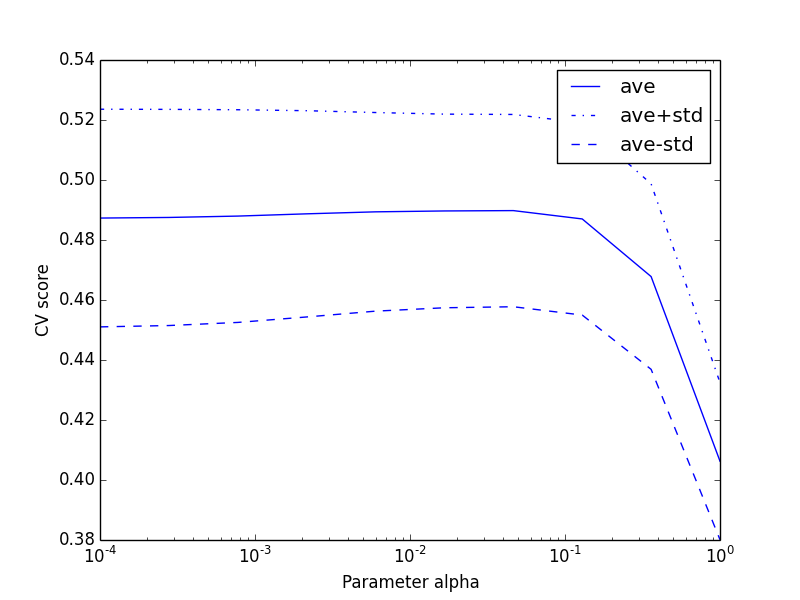
# alpha の影響をスコア(平均値+-標準偏差)で確認してみる。
# 横軸=alpha
# 縦軸=スコア
# pl.semilogx()
# 'b--'や'b-.'はプロット時の線スタイルの指定
# label='hoge' は凡例タイトルの指定
import pylab as pl
pl.figure()
pl.semilogx(alphas, scores, label='ave')
pl.semilogx(alphas, np.array(scores) + np.array(scores_std), 'b-.', label='ave+std')
pl.semilogx(alphas, np.array(scores) - np.array(scores_std), 'b--', label='ave-std')
pl.xlabel('Parameter alpha')
pl.ylabel('CV score')
pl.legend()
pl.show()
参考サイト一覧