Small Risc Processor (SRP)�@������
2008/9/13�@ver 1.0�쐬
2012/12/24 ver2.0 �쐬
������w�H�w�����H�w�ȁ@�a�c�@�m�v
[�O]�@�͂��߂�
��{�ۑ�͂������X�̖��߂����s�ł���}�C�N���v���Z�b�T�ł��B�����A�����̃v���O�����������ł��Ȃ��Ɩʔ����Ȃ��̂ŁA���l���傫���̏��ŕ��בւ���\�[�e�B���O�i�ڍׂɂ̓o�u���\�[�g�j�����s�ł�����x�̖��߂��܂�ł��܂��B���������āA�����v���O���������for���[�v�������ł���悤�ɁA������JUMP���߂ƁA�����t��JUMP�iBRANCH�j���߂��܂�ł��܂��B
�ȉ��ɁA�}�C�N���v���Z�b�T���悭�m��Ȃ��l�ł��v�ł���悤�ɁA���J�ɃA�[�L�e�N�`����������܂��̂ŁA�}�C�N���v���Z�b�T�Ƃ������t�����ꂸ�ɁA���킵�Ē��������Ǝv���܂��B
[�P]�@Small RISC Processor SRP �A�[�L�e�N�`��
�}�P��Small RISC Processor SRP �A�[�L�e�N�`���������܂��B���͍����SRP�A�L�e�N�`���̓I���W�i���Ȃ��̂ł͂Ȃ��A�W�����E�w�l�V�[�ƃf�C�r�b�h�E�p�^�[�\���̗L���Ȑ}���gCOMPUTER ORGANIZATION & DESIGN: the hardware / software�@interface�h�œo�ꂷ��RISC�R���s���[�^�̖��߂��X�ɍ팸�������̂ƂȂ��Ă��܂��B�܂��A���H�w�Ȃ̍u�`�@�u�v�Z�@�A�[�L�e�N�`���v�Ƃ��������̂ł��B�@���������āA���Ȃ葽���̕��X���������Ƃ̂���|�s�����[�ȍ\�����Ǝv���܂��B
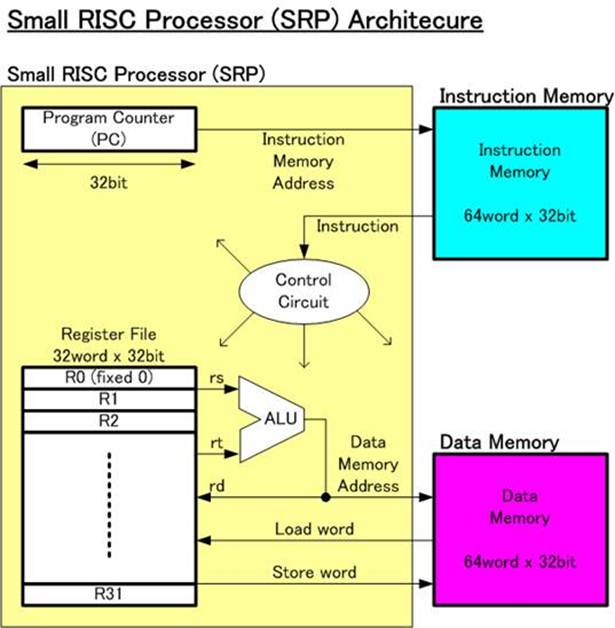
�}�P�F�@Small RISC Processor SRP �A�[�L�e�N�`��
�}�P��SRP�{�̂ƁA�Q�̃���������\������Ă��܂��B�������A�R���s���[�^�삳����ɂ́A���߂ƃf�[�^���K�v�ł��̂ŁA�����ł͖��߂�~���閽�߃������iInstruction Memory�j�A�f�[�^��~����f�[�^�������iData Memory�j���Q�̓Ɨ������������ō\�����Ă��܂��B���̗��R�́A���̕����������̎g�������P��������A�v���Z�b�T�̐v���P���ɂȂ邩��ł��B
��قǂ̃v���O�����̐����ŁA���炩�ɂȂ�̂ł����A���߃������ɂ�32�r�b�g�i�����ł̓��[�h�ƌĂԁj�̑傫���̖��߂������~�����Ă��܂��B�}�C�N���v���Z�b�T���̖��߃������ɒ~����ꂽ���߂��ЂƂ��ǂݏo���A����32�r�b�g���߂��������Z�����s���܂��B���̓�������ɐ������܂��B
�@ �u���߃t�F�b�`�v�F�}�C�N���v���Z�b�T�ɂ̓v���O�����J�E���^�[�iPC�j�Ƃ����J�E���g�@�\������܂��B����PC�̒l�͖��߃������̃A�h���X�M���ɑΉ����Ă���A���̃A�h���X�������ꏊ�̖��߂�ǂ݂����܂��B
�A �u���߃f�R�[�h�v�F��L�@�œǂ݂����ꂽ���߂̓��e�ɏ]���āA�K�v�ȓ�������邽�߂ɖ��߂̉�ǂ����{���A�K�v�Ȑ�����s���܂��B�}�P�ł�control circuit�̎d���ƂȂ�܂��B
�B �u���Z�ƃf�[�^�������A�N�Z�X�v�F��L���߂̉�nj��ʂɏ]���āA���W�X�^�t�@�C������K�v�Ȓl��ǂ݂����AALU�ɂĉ��Z���܂��B�K�v����A�f�[�^�������ɑ��ăA�N�Z�X���s���A�f�[�^�������Ƀf�[�^���������݁A�������͓ǂݏo�����s���܂��B
�C �u���C�g�o�b�N�v�F�Ō�ɁA�B�ł̉��Z���ʂ�A�f�[�^����������ǂ݂������l�����W�X�^�t�@�C���ɏ������݂܂��B�����āA�v���O�����J�E���^�[�iPC�j�̎��̃T�C�N���̒l��p�ӂ��܂��B
��L�@����C�̓���łЂƂ̖��߂����s����A�J��Ԃ����Ƃő����̖��߂����s���邱�Ƃ��ł��܂��B
[�Q]�@�T�|�[�g����
�ȉ��\�P�ɂX�̃T�|�[�g���߂������܂��B�Z�p���Z�A�_�����Z�A�f�[�^�]���A��������A�����������5��ނɋ敪����Ă��܂��B
R1,R2�̂悤�ȋL���̓��W�X�^�t�@�C���̃A�h���X�������Ă��܂��BRn�ł̓A�h���X��n�ł��BSRP�ł�32�r�b�g���W�X�^��32���ڂ��Ă���AR0����R31�����݂��܂��B
�m���ӁnSRP�ł̒ʏ��RISC�R���s���[�^�ɏ]���āAR0�͓��ʂȃ��W�X�^�łƂ��Ă���A�������݂͂��邱�Ƃ��ł����A���ALL0�̒l��ێ����Ă��܂��BALL0���Ȃ킿�A�O�́A�v���O�����ł悭�����鐔�l�ł���̂ŁA���W�X�^�t�@�C����0�Ԓn�����̓��ʂȐ��l�Ƃ��Ďg�p���Ă��܂��B
�\�P�@�T�|�[�g����
|
�敪 |
���� |
�A�Z���u���� |
��̈Ӗ� |
���l |
|
�Z�p���Z |
add |
add R1,R2,R3 |
R1 <= R2 + R3 |
���Z |
|
subtract |
sub R1,R2,R3 |
R1 <= R2 - R3 |
���Z |
|
|
�_�����Z |
and |
and R1,R2,R3 |
R1 <= R2 and R3 |
�e�r�b�g���Ƃɂ`�m�c |
|
or |
or R1,R2,R3 |
R1 <= R2 or R3 |
�e�r�b�g���Ƃɂn�q |
|
|
�f�[�^�]�� |
load word |
lw R1, 100(R2) |
R1 <= ������[R2+100] |
���������烌�W�X�^�ւ̓]�� |
|
store word |
sw R1, 100(R2) |
������[R2+100] <= R1 |
���W�X�^���烁�����ւ̓]�� |
|
|
�������� |
branch on equal |
beq R1,R2,25 |
if (R1=R2) go to PC+4+25*4 |
����������PC������ |
|
set on less than |
slt R1,R2,R3 |
if (R2<R3) R1<=1 else R1<=0 |
�@ |
|
|
�������W�����v |
jump |
j 2500 |
go to 2500*4 |
��A�h���X�W�����v |
�\�P�ŁAR1<=R2+R3 �Ƃ����悤�ȕ\�L������܂����A���W�X�^�t�@�C���̃A�h���X2�Ԓn�ɕێ�����Ă���l�ƃA�h���X3�Ԓn�ɕێ�����Ă���l��ALU�ɂĉ��Z���s���A�A�h���X�P�Ԃɏ����߂��Ƃ������Ƃ��Ӗ����Ă��܂��B
Load word���߂̓f�[�^����������32�r�b�g�̃f�[�^�����W�X�^�t�@�C���ɓ]�����閽�߂ł��B�\�̗�ł���glw R1, 100(R2)�h�́A���W�X�^�t�@�C���̃A�h���X2�Ԃɕێ�����Ă���l�Ɩ��ߒ��Ɏw�肳�ꂽ100�Ƃ��������l�̉��Z��ALU�ɂčs���A���̌��ʂ��f�[�^�������̃A�h���X�l�Ƃ��ăf�[�^����������l��ǂ݂����܂��B�����āA���̒l�����W�X�^�t�@�C���̃A�h���X�P�Ԃɏ����߂��Ƃ����Ӗ��ł��B
�t�ɁA�gsw R1, 100(R2)�h�Ŏ������Store word���߂́A���W�X�^�t�@�C���̃A�h���X�P�Ԃ���l��ǂ݂����A���W�X�^�t�@�C���̃A�h���X2�Ԃɕێ�����Ă���l�Ɩ��ߒ��Ɏw�肳�ꂽ100�Ƃ��������l�̉��Z��ALU�ɂčs���A���̌��ʂ��f�[�^�������̃A�h���X�l�Ƃ��ăf�[�^�������ɒl���������݂܂��B���߂̈Ⴂ�͍ŏ���sw��lw�������ł����A�f�[�^�̓]�������͋t�����ł��B
���ɁAbranch on equal�ł����A����̓��W�X�^�t�@�C�����̂Q�̒l���������ǂ�����r���āi���Z���Ă��̓������O���ǂ����j�A�����ł���A������s���܂��B
��ɐ������܂������A�v���O�����J�E���^PC�����߃��������̎��s���閽�߂̃A�h���X�Ԓn�������܂��B�ʏ핪�Ȃ��ꍇ�ɁA���������̎��Ԓn�ɂ��閽�߂����s����܂��B��قǁA�}�Ő������܂����A�R���s���[�^�ł͈�ʓI�ɁA8�r�b�g�P�ʁi�o�C�g�P�ʁj�̃A�h���X���t�����Ă��܂��B�����ł́A���߂��f�[�^��32�r�b�g��z�肵�Ă��܂��̂ŁA4�A�h���X�Ԓn���łЂƂ̖��߂������̓f�[�^���L������Ă��܂��B���������āA���̖��߂̔Ԓn�͌��ݎ��s���̖��߂̃A�h���X�{�S�ƂȂ�܂��B
���āAbranch on equal�̐����ɖ߂�܂����A�h beq R1,R2,25�h�ł�R1���W�X�^��R2���W�X�^�̒l���r���܂��B�����ł���A���̖��߂̃A�h���X�i�����PC+4�j�l��ύX���܂��B���̗�ł͖��ߒ��ɂQ�T�Ƃ�������������܂����A����͂Q�T��̖��߂ɕ���Ƃ����Ӗ��ł��i���̐��l�����̏ꍇ�͖߂邱�ƂɂȂ�j�B����̓A�h���X���v�Z����ƁAPC+4+25*4�ƂȂ�܂��B1���߂̑傫����4�A�h���X���ł��̂ŁA4�{���K�v�Ȃ킯�ł��B
�h slt R1,R2,R3�h��set on less than�Ƃ������߂ŁAR2�̒l��R3�̒l�ł���AR1�̒l���g�P�h�ɃZ�b�g���A�����łȂ���g�O�h�Ƀ��Z�b�g������̂ł��Bset on less than��branch on equa�������܂��g���Α��ʂȏ����������ł��܂��B
�Ō�ɖ���������(jump)���߂�������܂��B��قǂ̏�������ł́APC+4�̒l�ɑ��Ēl�����Z�i���̐��̉��Z���z��j���Ă��܂������A�hj 2500�h�̓������ł̐�ΓI�ȃA�h���X��0�Ԓn����݂āA2500�ڂ̖��߂ւ̕���������Ă��܂��B��قǂ��������܂������A�������̃A�h���X�̓o�C�g�P�ʁi�o�C�g�A�h���V���O�j��z�肵�Ă��܂��̂ŁA���ۂ̃������̃A�h���X�l�ł�4�{��2500*4=10000�Ԓn�ւ̖�������JUMP�Ƃ������ƂɂȂ�܂��B
[�R]�@�������A�h���b�V���O
�܂��}�Q�ɃR���s���[�^�ł͈�ʓI�ł���o�C�g�P�ʂł̃A�h���b�V���O�������܂��B
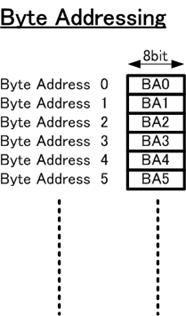
�}�Q�@�o�C�g�A�h���b�V���O
�}�̉E�̎l�p��8�r�b�g�̋L���u���b�N���Ӗ����Ă���A������o�C�g�f�[�^�ɑΉ����܂��BSRP�ł̓o�C�g�A�h���X��p���Ă��܂��̂ŁA1�o�C�g�i�ނ��ƂɁA�A�h���X�l���P�㏸���܂��B
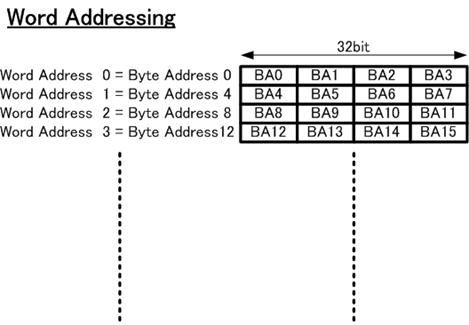
�}�R�@���[�h�A�h���b�V���O
�{�ۑ�ň������߂̃T�C�Y�͂S�o�C�g�i�R�Q�r�b�g�j��z�肵�Ă��܂��̂ŁA�}�Q�Ɏ����悤�ɉ������̂S�̃u���b�N����̖��߂̋L���P�ʂƂȂ�܂��B���������āA���߂𐔂���ɂ̓��[�h�A�h���V���O���֗��ł��B���̃��[�h�A�h���X�̒l���S�{����ƁA�S�o�C�g�u���b�N�̍��[�o�C�g�̃A�h���X�ƂȂ�܂��B
�}�P�Ɏ�����SRP�A�[�L�e�N�`���ł͂Q�̊O��������������܂����A�����̃������͂R�Q�r�b�g�P�ʂŃA�h���X���U���Ă���A���������A�N�Z�X����ꍇ�ɂ̓��[�h�A�h���X�ւ̕ύX���K�v�ł��B
[�S]�@���߃t�H�[�}�b�g
���āA����܂ł̘b�łЂƂ̖��߂͂R�Q�r�b�g�ł��邱�Ƃ͗����ς݂ł���Ǝv���܂��B�܂��A���߂ɂ͎Z�p���Z�A�_�����Z�A����ȂǐF�X�Ȏ�ނ����邱�Ƃ��������܂����B�܂����ꂾ���łȂ��A���߂ɂ̓��W�X�^�t�@�C���̃A�h���X��A�������̃A�h���X�̈ꕔ�������K�v������܂��B
�ʏ�͏�L�ŏq�ׂ������̈Ӗ����������߂ɁA�R�Q�r�b�g�����Ďg�p���܂��B���̕������ꂽ�������t�B�[���h�ƌ����܂��B���̂悤�ȃr�b�g�ł̖��߂̕\�����A�Z���u���[�\���������́A�@�B��\���ƌ����܂��B�ȉ��\�Q��p���Ė��߂̋@�B��\����������܂��B
�\�Q�@���߃t�H�[�}�b�g�i�e�t�B�[���h�̒l��10�i���Ŏ����Ă���B�j
|
���� |
�t�H�[�}�b�g�� |
�� |
���l |
|||||
|
6�r�b�g |
5�r�b�g |
5�r�b�g |
5�r�b�g |
5�r�b�g |
6�r�b�g |
|||
|
add |
�q�`�� |
0 |
2 |
3 |
1 |
0 |
32 |
add R1, R2, R3 |
|
sub |
0 |
2 |
3 |
1 |
0 |
34 |
sub R1, R2, R3 |
|
|
and |
0 |
2 |
3 |
1 |
0 |
36 |
and R1, R2, R3 |
|
|
or |
0 |
2 |
3 |
1 |
0 |
37 |
or R1, R2, R3 |
|
|
slt |
0 |
2 |
3 |
1 |
0 |
42 |
slt R1, R2, R3 |
|
|
lw |
�h�`�� |
35 |
2 |
1 |
100 |
lw R1, 100(R2) |
||
|
sw |
43 |
2 |
1 |
100 |
sw R1, 100(R2) |
|||
|
beq |
4 |
1 |
2 |
25 |
beq R1, R2, 25 |
|||
|
j |
�i�`�� |
2 |
2500 |
j 2500 |
||||
�܂��A�R�Q�r�b�g��\�Q�̂悤�ɕ������܂����A���̑O�ɂX�̖��߂��R�̌`���ɕ��ނ��Ă��܂��BR�`���̓��W�X�^�A�h���X���R�����K�v�̂��閽�ߗp�̌`���ŁAadd, sub, and, or, slt�����̌`����p���܂��B���W�X�^�͂O�Ԃ���R�P�Ԃ̂R�Q��ނ�����̂ŁA�T�r�b�g��p���ă��W�X�^�̃A�h���X�������Ă��܂��B�܂��AR�`���ł͍��[�̂U�r�b�g�����ׂĂO�ł���A���ꂪR�`���ł��邱�Ƃ������Ă��܂��Badd, sub, and, or, slt�̋�ʂ͉E�[�̂U�r�b�g�̒l�ŋ�ʂ���Ă��܂��B�܂��A�E����Q�߂̂T�r�b�g�t�B�[���h�͗p�����Ă��܂���B
����I�`���ł����A����̓��W�X�^�A�h���X���Q�ƁA���l�i�Q�̕␔�\����p���āA���������͂O�������͕��̐��������j�������Ă��܂��B���l�͂Ȃ�ׂ��傫�Ȑ��l���������Ƃ��ł�������ǂ��̂ł����A�g�[�^���R�Q�r�b�g�̐����ŁA���l�͂P�U�r�b�g�ł��B�Q�̕␔�\����p���Ă��܂��̂ŁA�\�R���\���\�Ȑ��l�͈̔͂ƂȂ�܂��B
�\�R�@�P�U�r�b�g�i�Q�̕␔�j�̕\���͈�
|
|
�Q�i���i�Q�̕␔�\���j |
�P�O�i�� |
|
�ő�l |
0111 1111 1111 1111 |
32767 |
|
0 |
0000 0000 0000 0000 |
0 |
|
�ŏ��l |
1000 0000 0000 0000 |
-32768 |
���̂P�U�r�b�g�t�B�[���h��lw, sw�ł̓f�[�^�������A�h���X�̌v�Z�i�o�C�g�P�ʁj�ɗp�����Ă���Abeq�ł͖��߃��[�h�̕��������Ă��܂��i���[�h�P�ʁj�B
�Ō��J�`���ł����AJ�`���Ń��W�X�^�A�h���X�������K�v���Ȃ��̂ŁA�Q�U�r�b�g�̐��l���p�����Ă��܂��B���̐��l���S�{����ƁA��������A�h���X�ƂȂ�̂ŁA���̐���\������K�v�͂Ȃ��A�����Ȃ����Ő��܂��͂O���\���͈͂ł��B
���l�ɁA�\�P�ɑΉ����閽�߂̗Ⴊ����A�\�Q�Ɏ��ۂ̃t�B�[���h�̒l�i�P�O�i���\���j������A�@�B��i�\�Q�j�ł̃t�B�[���h�̏������قȂ邱�Ƃɒ��ӂ��K�v�ł��B
�e�t�B�[���h�ɂ͖��O������A�����\�S�Ɏ����B
�@�\�S�@�t�B�[���h��
|
�t�H�[�}�b�g�� |
6�r�b�g |
5�r�b�g |
5�r�b�g |
5�r�b�g |
5�r�b�g |
6�r�b�g |
���l |
|
�q�`�� |
op |
���� |
rt |
rd |
- |
func |
�@ |
|
�h�`�� |
op |
rs |
rt |
offset |
�@ |
||
|
�i�`�� |
op |
address |
�@ |
||||
op�t�B�[���h��func�t�B�[���h��������w�肵�Ă���Brs�̓\�[�X���W�X�^�Art���ʏ�̓\�[�X���W�X�^�Ard�̓f�X�e�B�l�[�V�������W�X�^�ƌĂԁB
[�T]�@����ROM�ƃf�[�^RAM�̃T�C�Y�Ɋւ���
�}�P�łQ�̃����������������A����̉ۑ�ł͗^����ꂽ�v���O���������s���邱�Ƃ�z�肵�A�ȉ��̐}�S�Ɏ����������\����z�肷��B
����ROM�͂U�S���[�hX�R�Q�r�b�g�\���ł���A�Q�T�U�o�C�g�̑傫�������B�O�Ԓn���Q�T�T�Ԓn�̃A�h���X�𖽗�ROM�Ɋ��蓖�Ă�B
�f�[�^RAM���������U�S���[�hX�R�Q�r�b�g�\���ł���A�Q�T�U�o�C�g�̑傫�������B�Q�T�U�Ԓn���T�P�P�Ԓn�̃A�h���X�����蓖�Ă�B
�T�P�Q�Ԓn�ȏ�̃A�h���X�͕s�g�p�Ƃ���B
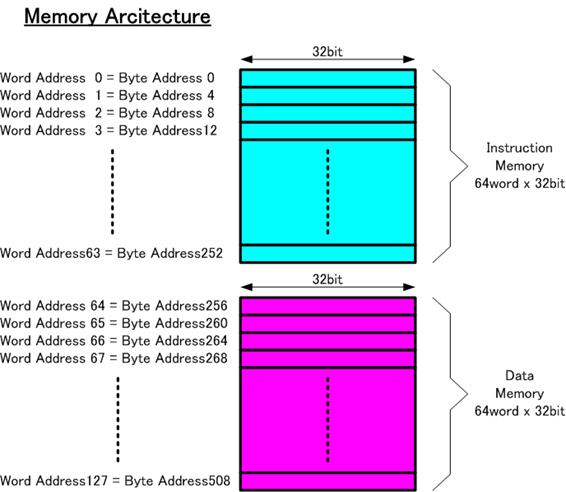
�}�S�@�������A�[�L�e�N�`��
[�U]�@�T�|�[�gVHDL�R�[�h
���Ƃ��āA��LSRP�v���Z�b�T��HDL�ɂĎ������A�W���[�h�i���[�h���S�o�C�g�j�̃\�[�e�B���O�i�o�u���\�[�g�j�����s���܂��B
�o�u���\�[�g�v���O����������������ROM�Ə����f�[�^���i�[���ꂽ�f�[�^RAM��VHDL���f�����ȉ��ɗ^���܂��B
Reset_b�M�����O->1�ɉ������ꂽ��A�v���O�����J�E���^�FPC=0�Ԓn�Ƃ��āA���s���J�n���܂��B
DRAM�̃f�[�^�����j�^�[���A�ȉ��̂悤�ȃV�~�����[�V�����g�`���m�F�ł���̓o�u���\�[�g���ł��Ă��܂��B
�g�p�p�b�P�[�W�@
����ROM�@
�f�[�^RAM�@
MPU�@
�e�X�g�x���`
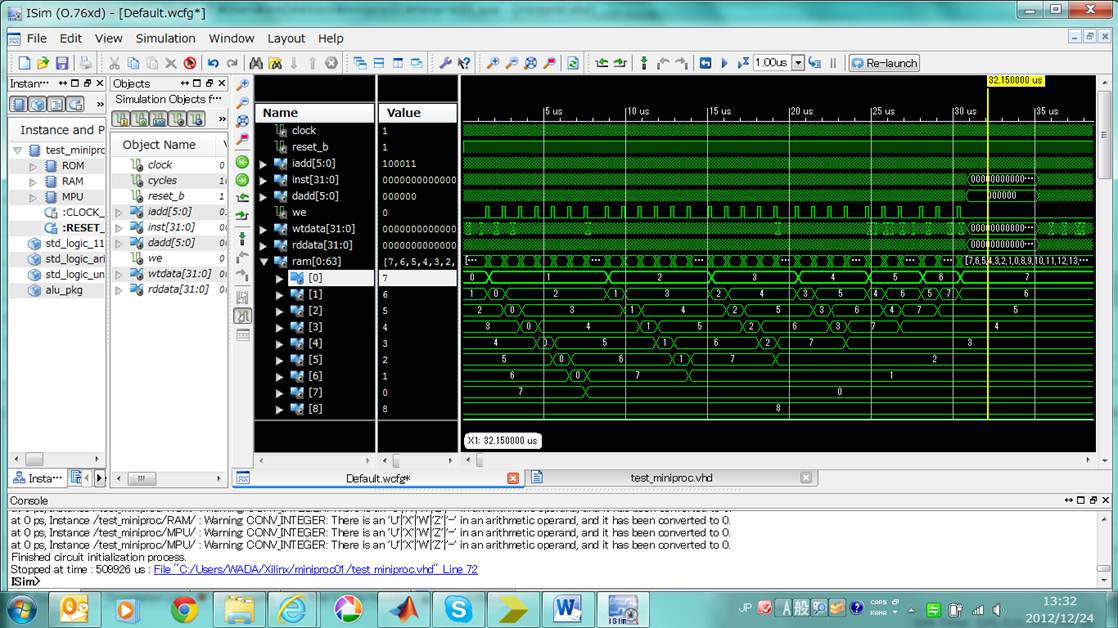
�}�T�@�o�u���\�[�g���s�g�`��
[�V]�@�o�u���\�[�g�v���O����
�o�u���\�[�g�ł͂Q�T�U�Ԓn����n�܂�W���[�h�̃A���C�ɑ��Ēl�̑傫�����l�����ʂ̃A�h���X����\�[�g����B�A���C�̐擪�Ԓn�͂R�W�S�Ԓn�̃��[�h�ɋL������Ă���B�A���C�̑傫���̓o�C�g��P�ʂƂ��ĂR�W�W�Ԓn�ɋL������Ă���B�����ł͂W���S���R�Q�ł���B���[�h�̑傫�����o�C�g�P�ʂƂ���A�S�ł��肱�ꂪ�R�X�Q�Ԓn�ɋL������Ă���B
�\�T�@�f�[�^RAM�̓��e
|
�@ |
�@ |
�f�[�^RAM |
�@ |
�\�[�g��̓��e |
||||||
|
�o�C�g�A�h���X |
dram��Add���� |
�O�O |
�O�P |
�P�O |
�P�P |
�@ |
�O�O |
�O�P |
�P�O |
�P�P |
|
256 |
0 |
0 |
-> |
7 |
||||||
|
260 |
1 |
1 |
-> |
6 |
||||||
|
264 |
2 |
2 |
-> |
5 |
||||||
|
268 |
3 |
3 |
-> |
4 |
||||||
|
272 |
4 |
4 |
-> |
3 |
||||||
|
276 |
5 |
5 |
-> |
2 |
||||||
|
280 |
6 |
6 |
-> |
1 |
||||||
|
284 |
7 |
7 |
-> |
0 |
||||||
|
�@ |
�@ |
... |
�@ |
�@ |
||||||
|
384 |
32 |
256 |
�@ |
256 |
||||||
|
388 |
33 |
32 |
�@ |
32 |
||||||
|
392 |
34 |
4 |
�@ |
4 |
||||||
|
�@ |
�@ |
... |
�@ |
�@ |
||||||
�\�U�@����ROM�̓��e�i�o�u���\�[�g�̃v���O�����j
|
�@ |
�@ |
����ROM�̓��e |
�@ |
|||
|
�o�C�g�A�h���X |
irom��Add���� |
�O�O |
�O�P |
�P�O |
�P�P |
���� |
|
0 |
0 |
NOP |
�@ |
|||
|
4 |
1 |
NOP |
�@ |
|||
|
8 |
2 |
LW R1, 388(R0) |
R1 <= 32 |
|||
|
12 |
3 |
LW R2, 384(R0) |
R2 <= 256, �擪�Ԓn |
|||
|
16 |
4 |
LW R3, 392(R0) |
R3 <= 4 |
|||
|
20 |
5 |
ADD R5, R1, R2 |
R5 <= 288, �ŏI�Ԓn�̎� |
|||
|
24 |
6 |
SUB R5, R5, R3 |
R5 <= R5 - 4 = 284, �ŏI�Ԓn |
|||
|
28 |
7 |
ADD R6, R2, R0 |
R6 <= R2 = 256�@�]���AR0�͂O�Œ� |
|||
|
32 |
8 |
ADD R7, R6, R0 |
R7 <= R6�A��r����f�[�^�P�̃A�h���X |
|||
|
36 |
9 |
ADD R8, R7, R3 |
R8 <= R7 + 4�A��r����f�[�^�Q�̃A�h���X |
|||
|
40 |
10 |
LW R10, 0(R7) |
R10 <= ��r����f�[�^�P |
|||
|
44 |
11 |
LW R11, 0(R8) |
R11 <= ��r����f�[�^�Q |
|||
|
48 |
12 |
SLT R9, R10, R11 |
R10 < R11�Ȃ�R9 <= 1�A�Ⴄ�Ȃ�R9 <=0 |
|||
|
52 |
13 |
BEQ R9, R0, +2 |
R9���O�Ȃ��PC=PC+4+2*4=64�֕��� |
|||
|
56 |
14 |
SW R10, 0(R8) |
��r�f�[�^�P���X���b�v��������� |
|||
|
60 |
15 |
SW R11, 0(R7) |
��r�f�[�^�Q���X���b�v��������� |
|||
|
64 |
16 |
ADD R7, R7, R3 |
R7 <= R7 +4, �A���C�C���f�b�N�X��i�߂� |
|||
|
68 |
17 |
BEQ R7, R5, +1 |
�C���f�b�N�X���ŏI�A�h���X�Ȃ�LOOP�P���� |
|||
|
72 |
18 |
J 9 |
�X�Ԓn�փW�����v�ALOOP1 |
|||
|
76 |
19 |
SUB R5, R5, R3 |
R5 <= R5 - 4, �ŏI�Ԓn��������B�����ɍŏ��l������B |
|||
|
80 |
20 |
BEQ R5, R2, +1 |
�ŏI�Ԓn���擪�Ԓn�ƈ�v�����LOOP2����B |
|||
|
84 |
21 |
J 8 |
�W�Ԓn�փW�����v�ALOOP2 |
|||
|
88 |
22 |
NOP |
�@ |
|||
[�W]�@�f�[�^RAM�̓���
�f�[�^RAM�̓f�[�^�̓ǂݏo���Ɋւ��ẮA�A�h���X���͐M���U�r�b�g�ɑ��āA�R�Q�r�b�g�f�[�^���o�͂���g�ݍ�����H�ł���B
�������݂ɑ��ẮAClock���̗͂������G�b�W��WE�M�����f�P�f�̎��ɏ������݂��s����B
�ڍׂ̓���g�`���ȉ��Ɏ����B
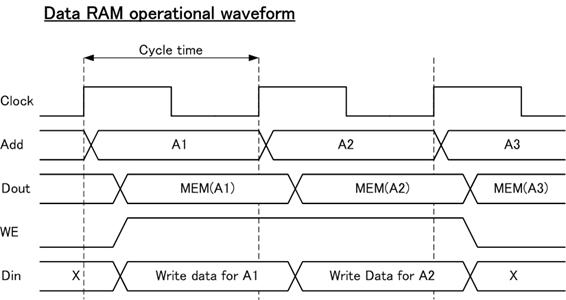
�}�U�@�f�[�^RAM����g�`
[�X]�@SRP�ڍ\��
SRP�̐v�A�[�L�e�N�`���̓T�^�I�ȗ���������B�P���߂��P�N���b�N�T�C�N�����ƂɎ��������ł���B
����ROM�̓��[�h�A�h���X����͂����ƁA���߂��ǂ݂������ROM��z�肵�Ă���BSRP�����̃��W�X�^�t�@�C����ra1, ra2�͂Q�̓ǂݏo���p�A�h���X�M���ł���A���̃A�h���X�ɏ]���āAdo1, do2�Ƀ��W�X�^�̒l�����ꂼ��ǂ݂������Bwa�͏������݃A�h���X�M���ł���A�������ރf�[�^��din�ɗ^������BwriteRF=1�ŁAClock�̗����オ��G�b�W�Ńf�[�^�����W�X�^�t�@�C���ɏ������܂��B
���W�X�^�t�@�C���ւ̃f�[�^�̏������݂��K�v�Ȗ��߂�add, sub, and, or, lw, slt�ł���B�\�V�ɂ܂Ƃ߂�B
�\�V�@���W�X�^�t�@�C���ւ̃f�[�^�̏������݂��K�v�Ȗ��߂Ɠǂݏo���f�[�^��
|
�敪 |
���� |
���W�X�^�t�@�C���ւ̃f�[�^�̏����߂� |
���W�X�^�t�@�C�����ǂ݂����l |
|
�Z�p���Z |
add |
�P |
�Q |
|
subtract |
�P |
�Q |
|
|
�_�����Z |
and |
�P |
�Q |
|
or |
�P |
�Q |
|
|
�f�[�^�]�� |
load word |
�P |
�P |
|
store word |
�O |
�Q |
|
|
�������� |
branch on equal |
�O |
�Q |
|
set on less than |
�P |
�Q |
|
|
�������W�����v |
jump |
�O |
�O |
ALU��add, sub, and, or�̉��Z�T�|�[�g���A���̉��Z����(result)���O�ł��邩�ǂ����ׂ�t���O(zero)���v�Z����Bslt���߂ł́AALU�͌��Z�����s���Azero�t���O�ׂ邱�ƂŁA�����\�ł���B
�f�[�^RAM�ւ̏������݂��K�v�Ȗ��߂�sw���߂ł���A�f�[�^RAM�̓ǂݏo�����K�v�Ȗ��߂�lw�ł���B
SRP�Ł��}�[�N��Clock���͂��Ӗ����Ă���B�N���b�N�̗������G�b�W�ŏ������݂��������鏇����H�ł���A���}�[�N�̂Ȃ����̉�H�͂��ׂđg������H�ō\���ł���B
�h���h�̓r�b�g�A���A�h�{�h�͉��Z��A�hMUX�h�̓}���`�v���N�T�A�hSE�h�͕�����ۑ������r�b�g����16�r�b�g����32�r�b�g�ւ̊g����H�ł���B�ȉ��A�\8�Ɋg���̗�������B16�r�b�g�\���ł�MSB�r�b�g��16���ɉ����Ύ����ł���B
�\�W�@������ۑ������r�b�g����16�r�b�g����32�r�b�g�ւ̊g���̗�
|
|
16�r�b�g�i�Q�̕␔�\���j |
32�r�b�g�i�Q�̕␔�\���j |
|
�ő�l |
0111 1111 1111 1111 |
0000 0000 0000 0000 0111 1111 1111 1111 |
|
0 |
0000 0000 0000 0000 |
0000 0000 0000 0000 0000 0000 0000 0000 |
|
�ŏ��l |
1000 0000 0000 0000 |
1111 1111 1111 1111 1000 0000 0000 0000 |
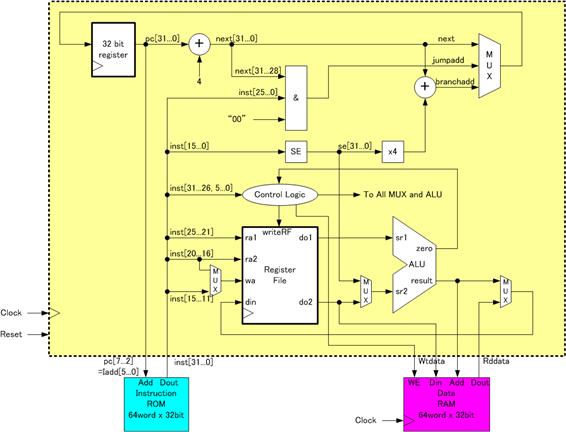
�}�V�@SRP�\����
�}�V�̉E��̂R����MUX�͕���Ɋւ�����̂ł���B�R���͂̈�ԏオ�I�������ꍇ�͒ʏ�̕��Ȃ��ꍇ�ł���Apc�l�͂S���C���N�������g���Ă���B�R���͂̒����͖���������ɑΉ����Ă���B���̑O���́g���h�̓r�b�g�̐ڑ��ł���A���L�Ɂh00�h��A�ڂ��邱�Ƃɂ��A�S�{���������Ă���B�܂��A��ʂ̃r�b�g�̕s�����S�r�b�g�͂��Ƃ�PC�̏�ʃr�b�g���R�s�[���Ă���B�R���͂̈�ԉ��́A�����t�������������iTAKEN�j�ꍇ�ł���BPC+4+offset*4�̌v�Z�ɂȂ��Ă���B
�}�W�ɁA�R�Q�Ԓn�A�R�U�Ԓn�A�S�O�Ԓn�����s���̓���g�`�������B�����̒l�ɂ��AIadd����������A����Inst������ROM�����o����Ă���B���߂̊e�t�B�[���h�̒l���Ara1, ra2, wa����������Ă��邱�Ƃ��킩��B
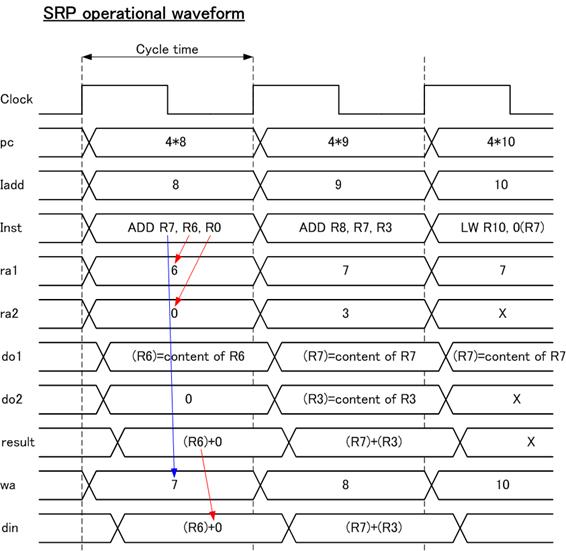
�}�W�@SRP����g�`�}