VLSI 2012 FINAL TASK の TASK0
2013/01/08
琉球大学工学部情報工学科 和田 知久
[0] LEVEL0 TASK
レベル0タスクは、2つの複素数をメモリ上に用意し、その2つの乗算結果の複素数をメモリ上に出力する。
複素数sr + j*si で、sr、siはそれぞれ16ビットとし、srとsiを連接して32ビットとして、主記憶に記憶する。
sr, siは各16ビットであるが、以下のように小数点の位置があると仮定する。最上位ビットMSBは符号を表し、2の補数表現とする。
|
固定小数点フォーマット |
例1 |
例2 |
|
SXXX XX . XX XXXX XXXX |
0000 00 .10 0000 0000 = 0.5(10進数) |
1111 11. 10 0000 0000 = -0.5(10進数) |
*** 小数点の位置を当初から変更している 注意! 注意! ***
この動作をするアセンブラーコードをROM上に作成し、
プロセッサの機能として、32ビットどうしの乗算命令やシフト命令などを必要に応じて追加し、
RAM上に記憶した入力データに対して、プログラムを実行し、乗算結果をRAM上に出力する。
[2] LEVEL0 TASK の実現実習
(1) 新命令の導入
SRPシステムは32ビットのコンピュータであるが、複素数は実部srと虚部siはそれぞれ16ビットであり、srとsiを繋げた32ビットが一つの変数として取り扱われる。
したがって、以下のような“新命令 cmul複素乗算 cadd複素加算”を導入することにする。
表1 サポート命令
|
区分 |
命令 |
アセンブラ例 |
例の意味 |
備考 |
|
算術演算 |
add |
add R1,R2,R3 |
R1 <= R2 + R3 |
加算 |
|
subtract |
sub R1,R2,R3 |
R1 <= R2 - R3 |
減算 |
|
|
cmul |
cmul |
複素数R1 <=
複素数R2 * 複素数 R3 |
複素乗算 |
|
|
cadd |
cadd |
複素数R1 <=
複素数R2 + 複素数 R3 |
複素加算 |
|
|
論理演算 |
and |
and R1,R2,R3 |
R1 <= R2 and R3 |
各ビットごとにAND |
|
or |
or R1,R2,R3 |
R1 <= R2 or R3 |
各ビットごとにOR |
|
|
データ転送 |
load word |
lw R1, 100(R2) |
R1 <= メモリ[R2+100] |
メモリからレジスタへの転送 |
|
store word |
sw R1, 100(R2) |
メモリ[R2+100] <= R1 |
レジスタからメモリへの転送 |
|
|
条件分岐 |
branch on equal |
beq R1,R2,25 |
if (R1=R2) go to PC+4+25*4 |
等しい時にPC相対分岐 |
|
set on less than |
slt R1,R2,R3 |
if (R2<R3) R1<=1 else R1<=0 |
|
|
|
無条件ジャンプ |
jump |
j 2500 |
go to 2500*4 |
絶対アドレスジャンプ |
(2) 複素加算命令 cadd について
cadd は2つのレジスタ(上記表1ではR2, R3)を読みだして、複素数として加算を行う。実際の演算は以下のようになる。
R2の上位16ビット(実部sr)とR3の上位16ビット(実部sr)を加算し、R1の上位16ビット(実部sr)とする。
R2の下位16ビット(実部si)とR3の下位16ビット(実部si)を加算し、R1の下位16ビット(実部si)とする。
(3) 複素乗算命令 cmulについて
cmul は2つのレジスタ(上記表1ではR2, R3)を読みだして、複素数として乗算を行う。実際の演算は以下のようになる。
R2の上位16ビット(実部sr) = sr2
R2の下位16ビット(実部si) = si2
R3の上位16ビット(実部sr) = sr3
R3の下位16ビット(実部si) = si3
とすると、複素乗算は以下のような計算になる。
(sr2 + j*si2)*(sr3 + j*si3) = (sr2*sr3 – si2*si3) + j * (sr2*si3 + si2*sr3)
したがって、
R1の上位16ビット(実部sr) = (sr2*sr3 – si2*si3)
R1の下位16ビット(実部si) = (sr2*si3 + si2*sr3)
となる。したがって、4つの実数乗算と2つの加減算で、1つの複素乗算が実現できる。
(4) 実習乗算について
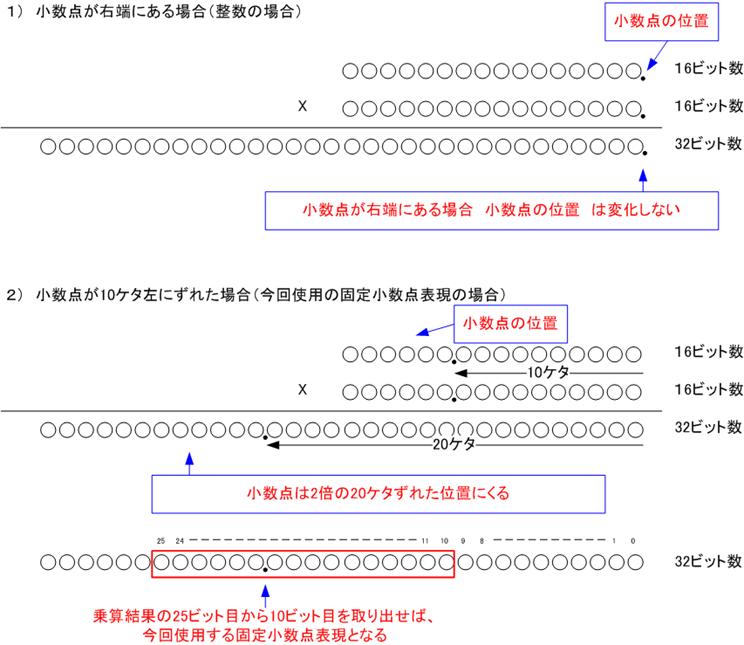
ここでは、以下に示す16ビット数の乗算を行う。
|
固定小数点フォーマット |
例1 |
例2 |
|
SXXX XX . XX XXXX XXXX |
0000 00 .10 0000 0000 = 0.5(10進数) |
1111 11. 10 0000 0000 = -0.5(10進数) |
*** 小数点の位置を当初から変更している 注意! 注意! ***
通常16ビット数と16ビット数を乗算するとその結果は32ビットとなる。
(5)以下Xilinxでの実習内容
(5−1) ISEを立ち上げ、SRP_LED_BLINK01プロジェクト等をコピーして、SRP_TASK0プロジェクトを作成し、そのプロジェクトをOPEN PROJECTする。
(5−2) 2命令追加のため、OPEN でalu_pkg.vhdを拓いて、以下の赤字の追加を行い、保存を行う。
(省略)
constant
FN_SLT : std_logic_vector
(5 downto 0)
:= "101001";
-- NEW INSTRUCTION
constant FN_CMUL : std_logic_vector (5 downto
0) := "110000";
constant FN_CADD : std_logic_vector (5 downto
0) := "110001";
--
registers
constant
R0 : std_logic_vector (4 downto
0) := "00000";
(省略)
(5−3) ROMコードの中身を以下のように修正する。
(省略)
constant ROM : MemVecArr :=
(0 => OP_ALU &
R0 & R0 & R0 & "00000" &
FN_ADD, -- NO operation
1 => OP_LW & R0 & R2 & "0000000100000000", -- LW R2,
256(R0)
2 => OP_LW & R0 & R3 & "0000000100000100", -- LW R3,
260(R0)
3 => OP_LW & R0 & R4 & "0000000100001000", -- LW R4,
264(R0)
4 => OP_ALU &
R2 & R3 & R1 & "00000" & FN_CMUL,
-- CMUL R1, R2, R3
5 => OP_SW & R0 & R1 & "0000000100001100", -- SW R1,
268(R0)
6 => OP_ALU &
R1 & R4 & R1 & "00000" & FN_CADD,
-- CADD R1, R1, R4
7 => OP_SW & R0 & R1 & "0000000100010000", -- SW R1,
272(R0)
8 => OP_ALU &
R0 & R0 & R0 & "00000" &
FN_ADD, -- NO operation
others => OP_ALU & R0
& R0 & R0 & "00000" & FN_ADD); -- NO operation
(省略)
プログラムとしては、256番地、260番地、264番地からそれぞれ32ビット数(複素数)をR2, R3, R4レジスタにロードし、複素乗算し、その結果のR1を268番地へストアし、その後R1にR4を複素加算し、その結果のR1を272番地へストアしている。
(5−4) RAMの内容を以下のように修正する。
(省略)
signal RAM : MemVecArr :=
(0 =>
"0000010000000000" & "1111100000000000", -- 1-2j
1 =>
"1111100000000000" & "0000110000000000", -- -2+3j
2 =>
"0000010000000000" & "0000010000000000", -- 1+1j
3 => conv_std_logic_vector ( 0, 32),
4 => conv_std_logic_vector ( 0, 32),
others => conv_std_logic_vector ( 0, 32) );
(省略)
RAMの最初の番地(256番地)に、複素数(1-2j)を、260番地に複素数(-2+3j)を、264番地に複素数(1+1j)を、置いている。
(5−5) プロセッサMINIPROCのALU部分を以下のように修正する。赤字の部分が追加である。
(省略)
--------------------
-- ALU
-------------------
ALU_RESULT: process(opcode,
regout1, regout2, sgnexd, func)
-- TSUIKA
variable sr1 : std_logic_vector(15 downto 0);
variable si1 : std_logic_vector(15 downto 0);
variable sr2 : std_logic_vector(15 downto 0);
variable si2 : std_logic_vector(15 downto 0);
variable sr3 : std_logic_vector(15 downto 0);
variable si3 : std_logic_vector(15 downto 0);
variable tmp1 : std_logic_vector(31
downto 0);
variable tmp2 : std_logic_vector(31
downto 0);
variable tmp3 : std_logic_vector(31
downto 0);
variable tmp4 : std_logic_vector(31
downto 0);
begin
if (opcode
= OP_ALU) then
if (func
= FN_ADD) then alu_rst <= regout1 + regout2;
elsif (func = FN_SUB) then alu_rst <= regout1 - regout2;
elsif (func = FN_AND) then alu_rst <= regout1 and regout2;
elsif (func = FN_OR ) then alu_rst <= regout1 or regout2;
elsif (func = FN_CADD) then
sr1 := regout1(31 downto
16);
si1 := regout1(15 downto
0);
sr2 := regout2(31 downto
16);
si2 := regout2(15 downto
0);
alu_rst <=
(sr1 + sr2) & (si1 + si2);
elsif (func = FN_CMUL) then
sr1 := regout1(31 downto
16);
si1 := regout1(15 downto
0);
sr2 := regout2(31 downto
16);
si2 := regout2(15 downto
0);
tmp1 := signed(sr1) * signed(sr2);
tmp2 := signed(si1) * signed(si2);
tmp3 := signed(sr1) * signed(si2);
tmp4 := signed(sr2) * signed(si1);
sr3 := tmp1(25 downto
10) - tmp2(25 downto 10);
si3 := tmp3(25 downto
10) + tmp4(25 downto 10);
alu_rst <=
sr3 & si3;
else -- SLT
if ( regout1 < regout2 ) then alu_rst <= conv_std_logic_vector
( 1, 32);
else
alu_rst <= conv_std_logic_vector
( 0, 32);
end if;
end
if;
elsif ((opcode = OP_LW) or (opcode =
OP_SW) ) then
alu_rst
<= regout1 + sgnexd;
elsif (opcode = OP_BEQ) then alu_rst
<= regout1 - regout2;
else
alu_rst
<= (others => '0');
end if;
end process ALU_RESULT;
ALU_ZEROFLAG: process(alu_rst) begin
if (alu_rst
= conv_std_logic_vector ( 0, 32) ) then alu_zero <= '1';
else
alu_zero <= '0';
end if;
end process ALU_ZEROFLAG;
(省略)
(5−6) シミュレーションを実行すると、以下のようになる。DRAMの中をモニターしている。
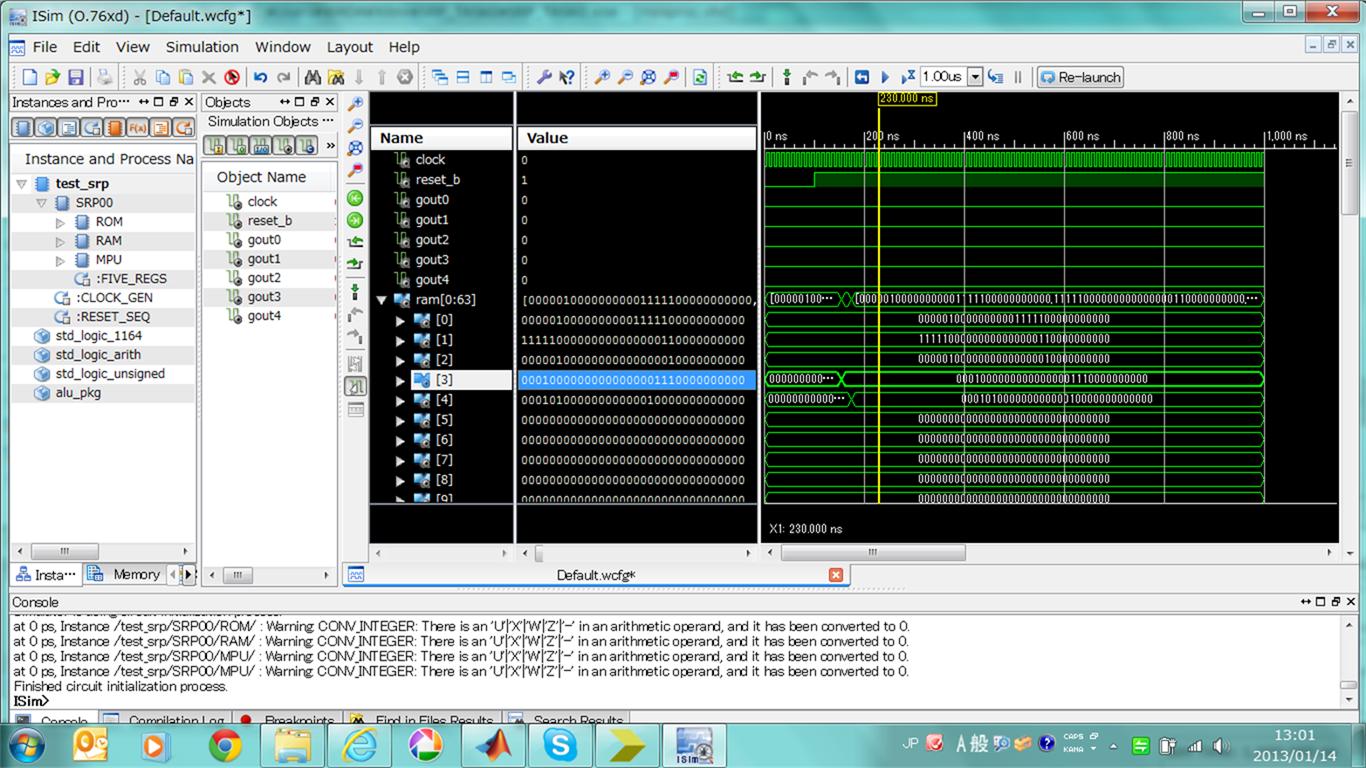
ram(0)の中身は、1-2j
ram(1)の中身は、-2+3j
ram(2)の中身は、1+1j
であり、
プロセッサでの計算結果が
ram(3)、ram(4)にある。それぞれ、4+7j、と 5+8j となっている。
以上