
商用のRDBは、数十万から数百万。もにによってはそれ以上の値段 がするのが普通だ。しかし、今では、Personal Oracle のような製 品が一時代前のメインフレームRDBをうわまる能力を持っている。
そういうものを使う時には、マニュアルを読めば良い。だが、RDBの イメージを持っていなければ、きっと歯が立たない。ここでの授業では セコイSQLしか使えないけど、そういうRDBやSQLのイメージをちゃんと 持っていれば、どんなRDBでも使いこなせるはずだ。そう思って がまんして使って下さい。
機能の低いMini-SQLだが、一つ、それを補う方法がある。それは、 他のプログラミング言語からMini-SQLを呼び出すことである。
msql は、結局、簡易なインタフェースに過ぎない。これを使って できることは限られている。実際には、WWWに結果を表示したり、 きれいなレポートを提出したり、QBEのfront endを付けたり、 あるいは「すごい」GUIを付けて高く売ったりしたい。そのためにAPI が必要となる。
APIは通常は、OSごとの互換性はまったくない。なにも互換性のことを 考えずに、OSや、良く使われる言語を対象に設計されている。それは あるい意味ではアセンブラレベルで定義されている。
では、互換性はまったくないならAPIを使う意味はないのだろうか? いや、実際には、APIの背後には、Mini-SQLの実装モデルがあり、 それは、どの機械でも同一だということができる。実際、C言語に対する APIが定義されていれば、それはさまざまなOS上で実質的な互換性を 持つことができる。
例えば、Mini-SQL をCから使う手順は以下のようになる。
if ((sock = msqlConnect(host)) < 0)
{
fprintf(stderr,"ERROR : %s\n",msqlErrMsg);
exit(1);
}
if (msqlSelectDB(sock, database) < 0)
{
printf("ERROR : %s\n",msqlErrMsg);
exit(1);
}
これで、Mini-SQLのserver(msqld)と接続しデータベースを選択した。
これは、msql -h host test という操作に相当する。sock というのは
socket であり、server との接続を実現するUnixのnetwork interface
である。このsockが、いわば、serverそのものを表している。このserverに対して、SQLのqueryを出すには、q という変数にSQL文を 含む文字列を代入して以下のように呼び出す。
if (msqlQuery(sock,q) < 0)
{
printf("\n\nERROR : %s\n\n",msqlErrMsg);
return;
}
printf("\nQuery OK.\n\n");
この関数自身は質問が成功したかどうかを返すだけである。実際に値が
欲しければ(欲しいのが普通だが) 以下のようにして、値を返す準備を
する。
m_result *result;
result = msqlStoreResult();
if (!result)
{
printf("\n\n");
return;
}
printf("%d rows matched.\n\n",msqlNumRows(result));
これは、ファイルのオープンに相当する操作であり、これから値を読みだし
始めるためのハンドラを用意している。ハンドラはsockと同じようなものだ。
答の数は、msqlNumRows(result))によって、ハンドラから呼び出すことが
できる。
準備がすんだら、答を一レコードごとに呼び出す。その前に、フィールド名 を取ってこなくてはならない。
m_field *curField;
while((curField = msqlFetchField(result))) {
...
}
このループの中で、curField 構造体に値がセットされる。
typedef struct field_s {
char *name,
*table;
int type,
length,
flags;
} m_field;
このような構造体は、/usr/open/Minerva/include/msql.h に定義されている。
これらは、SQLでテーブルを作った時に決めた値を返しているだけある。そして、
一レコードを読みだす。
while ((cur = msqlFetchRow(result))) {
for(off=0;off < msqlNumFields(result);off++) {
printf("%s\n",cur[off]);
}
}
Mini-SQLでは、 msqlFetchRow(result))) は、1レコードを表す文字列の
配列が返ってくる。このあたりはいろいろで、文字列1つで返すものもあれば、
さらに一旦フィールドを読みだす準備をする場合もある。このようにして、すべてのフィールドを読み終ったら、
msqlFreeResult(result); msqlClose(sock);という形で、一時的に取られている答の領域を解放し、server との接続を 切れば良い。
このCのAPIを利用して、他のAPIも作ることができる。例えば、Perl
のAPIを使えば、WWWからMini-SQLをアクセスするようなことができる
はずである。
% ls /usr/open/Minerva/msqldb/test test.dat* アカウント.key* データベース工学.dat* test.def* アカウント.stk* データベース工学.def* test.key* アンケート.dat* データベース工学.key* test.stk* アンケート.def* データベース工学.stk* test2.dat* アンケート.key* 学生.dat* test2.def* アンケート.stk* 学生.def* test2.key* ソフトウェア工学.dat* 学生.key* test2.stk* ソフトウェア工学.def* 学生.stk* アカウント.dat* ソフトウェア工学.key* アカウント.def* ソフトウェア工学.stk*このようにMini-SQLでは、ソフトウェア工学のrelationを4つのファイルに 分けて格納している。
実際のMini-SQLでは、表のほとんどはメモリ上にキャッシュされる。 現在のデータベースの実装は、教科書に乗っているB-Treeなどよりも、 ハッシュインデックス、データを入れたファイル、そして、メモリ上の キャシュという構成であることが多い。Disk上の構成をいくら工夫しても メモリ上のキャッシュにはかなわないからである。
このような構成は特にClinet / Server形式で有効である。これとは、 別にディスク上の実体をただ一つとして、その上に複数のデータベース マネージャーを置く方法もあるが、少し時代遅れだろう。その場合は ディスクを経由して、複数のマネージャーの同期をとらなければならない。 例えば、Unixのメールは、そのような方法を取っている。しかし、popper を 使えば、Clinet / Server 形式でメールを読み書きすることもできる。
さらに応答性能を上げたい場合には、メモリ上のキャッシュを共有した Multi-Thread (メモリを共有した平行プロセス) を複数走らせる方法が ある。現在のデータベースはこれが主流だと考えられる。一つは、これだと 安く実装できるからである。しかし、このようなメモリあるいはディスクを 共有する方法では以下のような平行制御の問題に注意して実装をおこなう 必要がある。
一方、キャッシュには常に「消えてしまう」という欠点がある。もし、 データベースの信頼性が重要ならば、ディスク上のデータとデータベース は常に一致してほしい。しかし、その要求と高速なアクセスとを両立 させるのは難しい。 一つの方法は、ディスクを複数並べて、その上に プロセッサを対応させる方法である。ディスクが別にある場合はRAID (Rapid Array of Inexpensive Disks)と呼ばれ、ディスクとプロセッサの 組がネットワークでつながれているような場合は、Shared Nothing などと呼ばれる。
データベースはものすごい速度で進歩しており、コンピュータアーキテクチャ の進歩に応じて変化している。これらの変化に敏感でいよう。
[操作A]
select count from test
where name='kono'
[操作B]
ここでcountを1増やす。例えば、256
[操作C]
insert into test ( name, count)
values ( 'kono', 256)
こういうものをCのAPIなどを使って書くのは簡単だ。これを複数のユーザ
が同時に行うと困ったことが起きる。実際、
count は 256 [操作A] by User A [操作A] by User B [操作B] by User A [操作B] by User B [操作C] by User A [操作C] by User B count は ?これは、明らかにAやBが予期していた結果とは異なる。
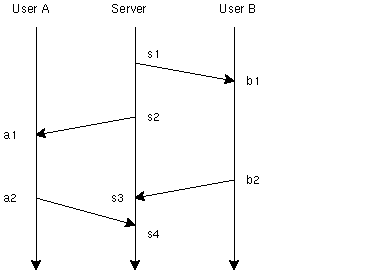
直列可能性が成立していれば、データベースはトランザクションの 変更の積み重ねとなる。これは、トランザクションの持っている データの関連からデータベース全体の関連ができていることを意味する。 これをデータベースの無矛盾性(Consistency)という。ある条件の もとでConsistencyとSerializabilityは同値であることが証明されている。
これは、a1a2,b1b2 の二つのトランザクションが、s1→ s2の順序に依存する b1b2→ a1a2 という順序と、s2→ s3 によって生じる a1a2→ b1b2 という順序が矛盾していることから生じている。
前の人の 値を上書きしているという単純なことだが、このように依存関係の矢印 を書くことによって、より矛盾が明快になる。また、機械的に矛盾を 見つける手順を提供することもできる。あたり前のことを明確にすることが コンピュータサイエンスでは重要なことが多い。
これを防ぐためにはいくつか方法がある。
後者の方法は良く使われるが、二つの問題がある。
lockの単位としては以下のようなものが考えられる。
Dead lockを避けるには、一つはリソースかトランザクションに順 序を付け、順序にそってlock をかけていく方法がある。そうすれ ば、最初にもっとも順序の大きいリソースを確保したものが必ず処 理を行うとすれば良い。この時には、相手のlockを解除しなければ ならない場合もある。
また、単にlockをかけただけでは直列可能性は保証されない。この ために良く使われるのは、2相lockというものである。これは、ま ず、必要なリソースに順番にlockをかけ、操作が終わったら順にlock をはずすというものである。lockをかけたりはずしたりすると、途 中で割り込まれたりするので気まずいのだ。
もう一つlive lockというのがある。一つのリソースのlockが取れなかった時に 普通は、しばらくあけて、もう一度lockをかけにいく。この時に、二つの トランザクションが両方で同じことをしていることがありえる。これは 例えば、二人で相手の家に同時に電話をかけることによって実現することが できる。
live lockは避けられないものであるが、実装の工夫によってある程度
緩和できる。その意味で深刻度は低い。しかしdead lockは必ず起きる
ものなので、なんらかの方策を用意しなければならない。