学生実験2 : 探索アルゴリズムその2・ニューラルネットワーク
- 更新情報
- 進め方(前回と同じ)
- 内容と目標
- 実験の進め方
- 評価基準
- 課題と提出方法
- コンテンツ
- 1. ニューラルネットワークとは?
- 2. 動作確認実験: Level 1 (8点), Level 2 (14点)
- 3. 応用事例(文字認識): Level 3 (17+17+8+6=48点)
- 4. オプション課題例
- 5. 補足
- 6. レポート骨組み
- 参考文献・サイト
- 更新情報
-
- [2017-01-24] 調整中。
- [2017-01-24] 公開。
- 内容と目標
-
- 探索アルゴリズム1の目標に加えて、
- (グループ討論、計算機実験を通して探索や最適化のイメージを掴む。)
- 多数のシミュレーション結果を整合性の取れた形で保存・整理することができる。
- 計算機実験を通してシステム(人工ニューラルネット; ANN)の挙動を観察し、入出力特性を考察する能力を養う。
- 課題と提出方法
-
- オプションを除く全ての Level にトライし、レポートとしてまとめよ。なお、演習課題についてはレポートに書く必要はありません。口頭試問は希望するグループのみやります。
- 1グループ1レポート提出。
- メンバ(氏名・学籍番号)と担当内容を記載すること。
- 提出物は以下の2つです。それらを「groupX」というフォルダに準備し、規定の場所に提出(アップロード)してください。印刷する必要はありません。
- 提出物1: レポートファイル
補足:LaTeXで作成し、PDF化したもの。texファイル、図ファイル等全て含めること。
- 提出物2: プログラム等の関連ファイル一式
実験再現に必要なものは全て含めること。
- 提出物1: レポートファイル
- 提出(アップロード)の手順:3ステップあり。
[手順1] 上記2つを「shell:~tnal/2016-search2-xxx/」に rsync で提出してください。保存する際のディレクトリ名は「groupX」のようにグループ名を使用する事。
例えば、MacBook 上の ~/group1/ に提出物を保存しているならば、以下のように rsync する事で提出できます。 rsync 自体の説明は例えばここを参照してください。# 実施日によってアップロード先が異なります! # 月曜日のクラスは「2016-search2-mon」へ。 prompt> rsync -auvze ssh ~/group1/ \ e1557xx@shell:/net/home/teacher/tnal/2016-search2-mon/group1/ # 金曜日のクラスは「2016-search2-fri」へ。 prompt> rsync -auvze ssh ~/group1/ \ e1557xx@shell:/net/home/teacher/tnal/2016-search2-fri/group1/ # 注意: # ・スラッシュの有無で引数の意味が大きく異なります。 # ・アップロードはグループ代表者一人が行ってください。 # ・パーミッションの都合上、レポート修正した後の再アップロードも # 同じ代表者じゃないとアップロードできません。
[手順2] 提出後、提出報告をメールにて連絡ください。
メールの件名は「(search2/mon/group1)」のように、テーマ名(search2)、 曜日(monもしくはfri)」、グループ番号、を含めるようにしてください。
[手順3] メールと提出ファイル一式を確認次第リプライを返します。
- プログラムのソースをレポート中に含める場合には、必要十分に留めること。不必要に全ソースを掲載するのは×。
- レポート提出期限:月曜クラスは2/6(月)、金曜クラスは2/3(金)とする。(探索アルゴリズム1も同一日です)
提出期限を過ぎたら、原則的に、受け取りません。 期限内に仕上げる事も重要なタスクです。 ただし、一般社会でも通用する理由で遅れてしまう場合にはこの限りではありませんので、なるべく早く相談してください。
- (希望グループのみ)口頭試問期限:レポート提出時が望ましいが別日程にて行う場合には、レポート提出から1週間を目安に予約する事。
- 採点後、優秀なレポートを期間限定で公表します。
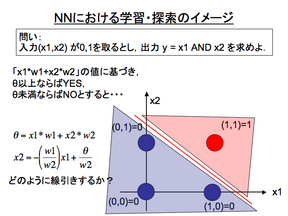
- 学習・探索のイメージ
-
単一のニューロン(単純パーセプトロン)のみで構成される2入力1出力の例を示す。
入力と出力は 0 or 1 を取るとした時、入力 x1, x2 の AND(論理積) を出力させるように学習させる事は、「w1, w2, θをどのように設定するのが最適か(最も適切に分類する線引きをするためのパラメータ値の組み合わせは何か)?」という探索問題として定式化することができる。
- 実験環境の準備
-
- 作業用ディレクトリの作成。ここでは「~/info2/」で作業することにします。
prompt> cd prompt> mkdir info2 prompt> cd info2
- リポジトリのクローンを作成。
下記コマンド中の「e1557xx」は各自のアカウント名に変更すること。
prompt> hg clone ssh://e1557xx@shell.ie.u-ryukyu.ac.jp//net/home/hg/teacher/tnal/nn prompt> cd nn prompt> ls
- 正常にクローンを作成できていれば、~/info2/nn 以下に3つのディレクトリ".hg"(Mercurial管理用)、"bp_mo"(Level 1, 2用), "nn_num"(Level 3用) が作成されているはずです。("nn_char_ja"は使いません)
- 「Could not resolve hostname shell(shellという名前のホスト名を探しきれない)」というエラーが出る場合には、「システム環境設定->ネットワーク->利用している接続デバイス->詳細->DNS->検索ドメイン」に「ie.u-ryukyu.ac.jp」を追加してから再度試してみてください。
- hg でダウンロードできない人はここのリポジトリからダウンロードしてください。
- 作業用ディレクトリの作成。ここでは「~/info2/」で作業することにします。
- Level 1: 線形分離可。 (8点)
-
実験内容
ソースのあるディレクトリ(~/info2/nn/bp_mo/)に移動し、以下の実験(演習課題、Level 1)を実施せよ。
- 演習課題: サンプルソース(bp_mo.c)は「OR問題」を設定している。この問題においてシード値を変更して適当回数実行し、大抵の場合簡単に解けている事を確認せよ。
コメント:初期重みを設定している乱数シード値を 1000,2000,...,10000 と変更し、実行し、重みが変わったとしても数100回程度の学習で誤差がほぼゼロになる事を確認する。なお、通常はシード値は適宜自由に変更して実行するが、今回の実験に限ってはシード値を「1000,2000,3000,4000,5000,6000,7000,8000,9000,10000」の10パターンとして指定する。(Level2,3で共通の指定です)
使い方について: prompt> gcc bp_mo.c -lm prompt> ./a.out $random_seed # 実行時の引数「$random_seed」は前述の10パターンを試すこと。 シミュレーションの終了条件について: ・FINISH 1: 学習回数(ITERATIONS=100000)を越えたとき。 ・FINISH 2: 誤差が最少誤差(MIN_ERR=0.0001)より小さくなったとき。
- Level 1: 「OR問題」を学習させた際の学習の推移(iteration vs error)をグラフ化し、そのグラフ化手順と共に示せ。なお、グラフの横軸は学習回数、縦軸は誤差とする。
コメント:学習結果をグラフ化する際には、(a)シード値を変更して得られた10回分の学習結果(10本の学習曲線)と、(b)10回分の学習結果を平均した結果(1本の平均学習曲線)、の2つのグラフを作成すること。shell/perl等のスクリプト言語/表計算ソフト/gnuplot等を利用すると楽になるでしょう。ソースファイルそのものを改変するのもOK。
- 演習課題: サンプルソース(bp_mo.c)は「OR問題」を設定している。この問題においてシード値を変更して適当回数実行し、大抵の場合簡単に解けている事を確認せよ。
- Level 2: 線形分離不可 (14点)
-
実験内容
bp_mo.c をコピーして bp_mo_exor.c を作成し、以下の演習課題と Level 2 を実施せよ。
- 演習課題: bp_mo_exor.c を編集して「ExOR問題」へ変更し、シード値を変更して複数回実行せよ。OR問題と異なり、そのままでは学習が適切に収束しない事を確認せよ。
- Level 2: 「ExOR問題」をうまく学習する為に、以下に示す各パラメータを変更して実験せよ。最も効率良く学習が収束するパラメータの組み合わせについて検討せよ。また、そのパラメータを用いた際の学習曲線(10試行平均値)を描け。
- 「最も効率良く学習が収束する」とは「指定した10パターンのシード値を与えて学習させた際、誤差がほぼゼロとなる(=誤差がほぼ0に収束する)までに要した試行回数(iteration数)の平均値が最も低い」こととする。
- 下記3パラメータは「bp_mo.c(bp_mo_exor.c)」上部にて#defineとして宣言されている。
パラメータ 変更目安 学習係数 ETA 0以上〜2.0未満の実数 慣性項 ALPHA 0以上〜1.0未満の実数 中間層のユニット数 HIDDEN 1以上の自然数 注記:レポートには、(1)求めたパラメータ、(2)そのパラメータを用いた際の学習回数(10回分+平均値)、(3)そのパラメータを用いた際の平均学習曲線、の3点を示すこと。コメント:「最も効率良く学習が収束するパラメータの組み合わせ」を探し出すには、どのように実験を進めれば良いだろうか?
- (オプション)どうやれば効率良く最適な組み合わせを探すことができるか?可能な限り人の手間を省いて自動化する方法を検討し、実験せよ。
- Level 3: 文字認識サンプル (17+17+8+6=48点)
-
実験内容
ソースのあるディレクトリ(~/info2/nn/nn_num/)に移動し、以下の実験(演習課題、Level 3.1 〜 3.4)を実施せよ。
動かし方は 0README_ja.txt を参照。 3パラメータは「nn_num/src/parameter.h」で#define定義されています。
- 演習課題: サンプルソースを動かし、『零、一、二、三、四、五、六、七、八、九』の文字を認識するように重みを学習させよ。本プログラムでは、学習用には data.kanji/{learn0.txt ... learn9.txt} を用いているが、類似した文字 eva1-1.txt, eva1-2.txt を適切に『一』として認識するか、確認せよ。
- step 1: プログラムの動かし方は 0README_ja.txt を参照。
- step 2: 「漢字認識」用の学習データを読み込ませるためには、parameter.h内の3カ所を編集する必要がある。
- (1) SIZE_Xを17に変更すること。
- (2) SIZE_Yを19に変更すること。
- (3) PROBLEMを"problem_list.kanji.txt"に変更すること。
- その他: 「一定試行回数(1000回)」を変更したいなら「ITERATIONS」を変更すること。
- step 3: コンパイル方法。
make コマンド1発でコンパイルできるはずです。エラーがでる場合には編集箇所がおかしい可能性あり。自分で解決できない場合にはTA or 教員に確認してください。
- step 4: シミュレーションの実行。
実行方法は下記2通りを用意している。
- (1) ./nn_num シード値
実行ファイル(./nn_num)に直接シード値を指定して実行する方法。
- (2) ./run_nn.bash シード値
指定したシード値を元にした探索挙動(iteration vs error)をグラフ生成するスクリプト。
- 補足: (1),(2)どちらの方法でもプログラム内部でインタラクティブに動かす必要があります。毎回手動でやるのが面倒な場合にはリダイレクトを利用して手間を省略することも可能です。
===== USAGE ===== learn: nn> l check: nn> c evaluation: nn> e after that, input filename defined test-pattern ================= 指定した試行回数分,学習させるには「l」. 学習事例に対する学習度合いを確認するには「c」. 未知事例に対する適応度合いを確認するには「e」を入力後, ファイル名を促すプロンプトが出力されますので,未知事例を 保存したファイル名を入力してください.
- 学習収束後、「data.kanji/eva1-1.txt」で認識テストをする際には、「e」を入力後、「data.kanji/eva1-1.txt」として相対パスでテストデータが記入されているファイルを指定する必要があります。
- 「e」コマンドで認識テストを行う際、パスやファイル名が不適切な場合にはプログラムが異常終了しますので、(ファイルチェック等はしていません)注意してください。
- (1) ./nn_num シード値
- Level3.1: 文字認識サンプルにおいて、Level 2 と同様にパラメータを調整し、学習後の誤差が最も早く収束する(=学習に向いているパラメータの)組み合わせを検討せよ。また、そのパラメータを用いた際の学習に要した回数(10回分+平均値)を示すと共に、学習曲線(10試行平均値のみ)を描け。
注記:レポートでは、(1)最適パラメータを発見するためのアプローチ、(2)求めたパラメータ、(3)そのパラメータを用いた際の学習回数(10回分+平均値)、(4)そのパラメータを用いた際の平均学習曲線、の4点を示すこと。コメント:指定したシード値10パターンによる収束度合いが最速のグループには、ボーナスポイントとして基準点がAになるように「加点+20」を与えます!
- Level3.2: Level 3.1 のパラメータ調整を通してどのような傾向が見られたのか、実験結果を数例示すと共に、パラメータと収束能力の関連性について考察せよ。
注記:レポートでは、(1)パラメータが収束能力へ与える影響を観察する方法(実験計画)、(2)その計画に基づいた結果、(3)結果を観察することで分かること(考察)、の3点を示すこと。
- Level3.3: 各自で任意の評価用データを複数作成し、学習時のデータとの違いが少ないほど認識率が高い事を示せ。
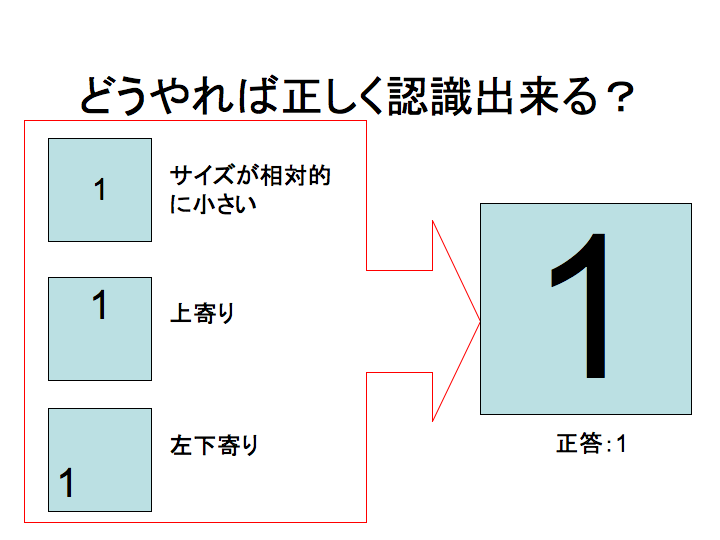
- Level3.4: 下図のように入力されたデータが想定していた入力と比べてサイズが異なったり、位置がずれている等、文字の一部が欠けている以外にも多様な要因によるデータ(情報)の劣化が考えられる。認識率を高めるにはどのような点を工夫すれば良いか?どのような方法でも構わないので、検討せよ。

- 演習課題: サンプルソースを動かし、『零、一、二、三、四、五、六、七、八、九』の文字を認識するように重みを学習させよ。本プログラムでは、学習用には data.kanji/{learn0.txt ... learn9.txt} を用いているが、類似した文字 eva1-1.txt, eva1-2.txt を適切に『一』として認識するか、確認せよ。
- Level X: オプション課題例
-
- Level3関連
- Level 3.1, 3.2 における複数シミュレーションを効率良く行い、集計するスクリプト作成やプログラム修正等。
- Level 3.4 にて検討した事項の実装。
- 「文字認識サンプル」を画像ファイルの読み込みに対応させる(簡易バージョンでも良いし、画像ファイル or 疑似画像ファイルを読「サンプルプログラムの読み込みフォーマット」に変換するプログラムの作成でも良い。)。
- 「文字認識サンプル」におけるパラメータのチューニングを効率良く行うための工夫。
- 「文字認識サンプル」を利用した他のアプリケーションへの適用(利用しにくい場合にはゼロから書き直しても ok)。
- Level3関連
- Level X: 補足
-
実験の内容・進め方に関するコメント等
- 今後の為に参考にしたいので、情報工学実験2・探索アルゴリズム1〜2で扱った内容、実験の進め方等について意見があれば書いてください(当然、どのような意見であってもレポートの評価を下げる事はしません。)。「授業評価アンケート」の際に書いてもらっても構いません。参考までに、今回の実験では以下の点を考慮した内容のつもりで実施しました。
- 扱った内容:探索アルゴリズムの考え方、NN。
- 中心課題:
(1)計算機実験を実施するにあたっての考え方、特に、実験計画・実験・結果収集・結果解析・レポート作成までの一連の作業をするにあたって考慮すべき点の発見と、対処方法の検討。
(2)(1)の実験を効率良く実施する為に検討すべき項目の調査と、それを解決する手段に関する検討。
(3)パラメータ・チューニングの必要性やそれらを効率的に実現する為の前処理・後処理のためのテキスト処理や自動化に関する考え方、
(4)(主題ではないですが)サンプル・ソフトウェアの利用を通した、システム設計面における外部設計指針、マニュアル整備等の必要性確認。
- 進め方
(1)「解説→グループ討論/実施→全体討論」という形式を取り、他の人/グループが同じテーマを与えられた時にどのような事を考え、アイデアを整理し、どのように発表するのかについて、学生全員が実験時間中に把握出来るように心がけた。
(2)「共同作業(グループ制)」とする事で、個人レベルでの理解度の底上げに努めた。これは、解説の段階で理解度の早い学生は他の人へ教示する事でそのスキルとより理解度が深まる上に、理解度が不十分であった学生は同環境にいる学生の視点からの教示により理解しやすくなる事を期待して実施した。
(3)(2)の間接的な効果として、自分の意見を第三者へ伝えるコミュニケーション能力・レポート作成技術の向上が挙げられます。
- 今後、実施を検討している以下の項目に関する、賛成/反対等の意見。
(1)レポートの開示。取りあえず、今回の分については採点後、評価の高いレポートについて了承を得てから開示の有無を決定するつもりです。
(2)最急降下法、NN、(GA)以外のアルゴリズムを用いた実験(「アルゴリズムとデータ構造」等、他の講義で出てくるアルゴリズムを利用した実験等)。
- やって欲しかった内容、その他に関する意見。
- 今後の為に参考にしたいので、情報工学実験2・探索アルゴリズム1〜2で扱った内容、実験の進め方等について意見があれば書いてください(当然、どのような意見であってもレポートの評価を下げる事はしません。)。「授業評価アンケート」の際に書いてもらっても構いません。参考までに、今回の実験では以下の点を考慮した内容のつもりで実施しました。
- ダウンロード: reportskel-search2.tgz
- 骨組みをコンパイルして生成できるPDFファイル: search2-utf8.pdf
- コンパイル方法
prompt> make
- 参考文献・サイト
-
- スクリプト等、実験環境関連
- google keywords: perl, ruby, gnuplot
- 実験1: Shell script と gnuplot の参考文献・サイト
- Gnuplot入門
- Mercurial 関連
- Mercurialとは(学科システム利用の手引)
- ニューラルネット関連
- google keywords: ニューラルネットワーク
- Neural Networks and Deep Learning by Michael Nielsen.
- 関連書籍(入門書としてベター。専門書ではないので、詳細を勉強したい場合には別途発掘しましょう)
- その他
- スクリプト等、実験環境関連
進め方
1. ニューラルネットワークとは?
人の脳を情報処理モデルとして単純化したシステムで、ニューロンと呼ばれる脳細胞を結合したネットワークの総称がニューラルネットワークである。 様々なモデルがあるが、目標の一つは「人間の脳そのものの処理をコンピュータで表現する事で、それまでコンピュータが不得手としていた/解けない問題を解決する」ことである。
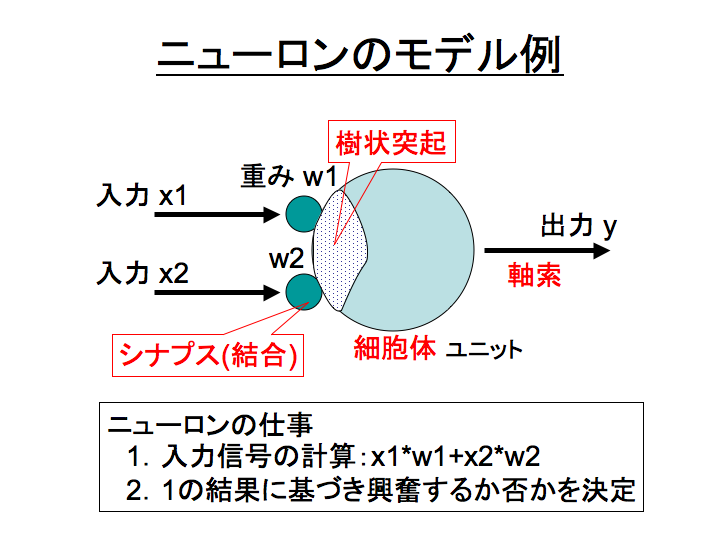
各ニューロンは、入力信号 xi に重要度(重み) wi を掛け合わせた値の総和を算出し、その値に応じて自身が興奮(発火)するか否かを決定するシンプルな機械として定義される。

2. 動作確認実験
3. 応用事例(文字認識)
4. オプション課題例
5. 補足
6. レポート骨組み
レポート作成を分担して進めやすくするために、レポートの骨組みを用意しました。具体的には、input コマンドを用いて複数ファイルを読み込んで、一つのレポートを生成するようにしてあります。分類はあくまでも例ですので、分け方を変更してもらっても構いません。