学生実験2 : 探索アルゴリズムその1
- 更新情報
- 進め方
- コンテンツ
- 1. 最適化とは?: Level 1.x (7+10+10点)
- 1.1. 前提1: コンピュータと人間の違い(Level 1.1)
- 1.2. 前提2: モデルとその良さの評価方法(Level 1.2, 1.3)
- 2. 最急降下法による最適化: Level 2.x (13+13+17点)
- 3. レポート骨組み
- 4. FAQ
- 1. 最適化とは?: Level 1.x (7+10+10点)
- 参考文献・サイト
進め方
- 内容と目標
-
- 前置き1: 復習を兼ねて、実験1で学んだ技術(スクリプトプログラミング)の応用。
- 前置き2: 人工知能関連科目(人工知能、ニューラルネット、知能ロボット、実験3/4(データマイニング班))へのイントロダクション。
- グループ討論、計算機実験を通して最適化のイメージを掴む。
- モデルを立案し、その評価方法について検討することができる。
- 計算機実験を通して最急降下法の動作を理解し、そのメリット・デメリットを示すことができる。
- 実験の進め方
-
- グループ作業。
各課題についてグループ間で議論し、プログラミング、考察、文書作成等を共同作業で行う事。あるテーマについて議論し、意見をまとめ、やるべき行動を設定&実行し、その結果を考察・報告する一連の作業(See also PDCAサイクル)を実施する事も本実験の課題である。作業分担についてはこちらからは指定しないが、各自担当した箇所が分かるように明示する事。
注意: 上記における「担当」や「分担」は、レポート作成上の担当であって、実験担当ではない。全員が実験を実施した上で、レポートとして整理する担当のことである。例えば、AさんがLevel 1のレポート作成を担当したとしても、BCDさんがLevel 1をやらなくて良い訳ではなく、BCDを含めた全員がLevel 1を実施する必要がある。その上で、AさんがLevel 1に関するリーダーとなって結果や考察等を整理し、レポートとして書き上げるための役割である。
- 各レベル毎に、「解説→グループ活動(討論/実装/計算機実験/考察)→全体討論(報告会)」を行う。
- グループ作業。
- 評価基準
-
報告会では、主にプレゼンや質疑応答により「コミュニケーション能力、論理性」を中心に評価する。
レポートでは、指定した課題をこなしている(提出している)事を前提に基準点を設け、以下の項目に沿って加点・減点を行う。参考までに各レベルの点数を掲載することで難易度(求めるレポートの質・量)を示しているが、必須のレベル(オプションと書いてある箇所以外全て)は全てこなすこと。一部の課題をやらなかった場合には、該当レベル分の点数を減じるだけではなく、ペナルティとして10点更に減じる。
口頭試問(レポート提出時もしくは後日実施)では、レポート概説や質疑応答により「コミュニケーション能力、論理性」を中心に(なるべく個別に)評価する。
レポートの基準点は70点、報告会と口頭試問の両方で10点、合計80点程度である。課題を無難にこなすだけではA(90点〜)にはならない。積極的にオプション課題や関連技術について取り組み、加点を勝ち取るように。
なお、探索アルゴリズム1と2のレポート2つ分の合計得点を200点満点として採点する。このため、例えば探索アルゴリズム1で130点分頑張り、探索アルゴリズム2は70点程度の時間(最低限の努力)で仕上げる、というように片方に注力するやり方であっても構わない。
加点 - 独自に行った関連課題に関する報告(積極性)。
- 実験中に示した手法ではなく、自力で探し出した異なる手法で問題を解決した場合(積極性・実践性・創造性)。
original/prevenience/traditional を問わないが、実験が主目的であるため可能な限り動かすよう努力すること。サンプルソースやツール等が動かない場合にはその原因究明についてレポートする事も一つの報告方法である。
- 手法の利点・欠点や限界等に関して自主的にトライした結果・考察が示されている場合(積極性・専門性)。
- レポートの見せ方に関する工夫や、グループ作業に伴う支援ツール等の利活用(コミュニケーション能力)。
- その他、本テーマに関連する実験的側面上「積極性・実践性・創造性・コミュニケーション能力」等の観点から評価できるもの。
減点 - 先行研究や事例、レポート、web等を参照しているにも関わらず、それらを参考文献として参照していない場合(一般倫理)。
- 論理的矛盾が見られる場合(論理性)。
- 結果を示さずに考察のみを記載してたり、結果に対する考察に整合性が見られない場合(コミュニケーション能力)。
- タイプミスや可読性の欠如(特に、図が読めないレポート多し!)、数式等記号の印字ミス、提出期限の遅れ等、多方面に関して大きな誤りではない場合。
- 提出遅延に関しては減点ではなく「原則として受け付けません」。
何らかの理由で間に合わない場合にはホウレンソウ(報告/連絡/相談)。 相応の理由がある場合には可能な範囲で事前に連絡相談してください。 事情に応じて後日でも構いませんが、なるべく早く報告してください。一般社会の常識です。
- 課題と提出方法
-
- オプションを除く全ての Level にトライし、レポートとしてまとめよ。後日、レポートに関する簡単な口頭試問を行うので、口頭試問の期日に関して別紙/メールにて予約をする事。口頭試問の実施期限は、目安として1月中旬(遅くて1月中)とする。早めでも構いませんが、遅くなるのはできるだけ避けること。
- 1グループ1レポート提出&口頭試問。
- メンバ(氏名・学籍番号)と担当内容を記載すること。
- 提出物は以下の2つです。それらを「groupX」というフォルダに準備し、規定の場所に提出(アップロード)してください。印刷する必要はありません。
- 提出物1: レポートファイル
補足:LaTeXで作成し、PDF化したもの。texファイル, 図ファイル等全て含めること。
- 提出物2: 図やプログラム等の関連ファイル一式
補足:実験再現に必要なものは全て含めること。
- 提出物1: レポートファイル
- 提出(アップロード)の手順:3ステップあり。
[手順1] 上記2つを下記の通り rsync で提出してください。追加・修正提出する際にはパーミッションの都合で「始めにrsyncした人」がやる必要があります。保存する際のディレクトリ名は「groupX」のようにグループ名を使用する事。
例えば、MacBook 上の ~/group1/ に提出物を保存しているならば、以下のように rsync する事で提出できます。 rsync 自体の説明は例えばここを参照してください。# 実施日によってアップロード先が異なります! # 月曜日のクラスは「2016-search1-mon」へ。 prompt> rsync -auvze ssh ~/group1/ \ e1557xx@shell.ie.u-ryukyu.ac.jp:/net/home/teacher/tnal/2016-search1-mon/group1/ # 金曜日のクラスは「2016-search1-fri」へ。 prompt> rsync -auvze ssh ~/group1/ \ e1557xx@shell.ie.u-ryukyu.ac.jp:/net/home/teacher/tnal/2016-search1-fri/group1/ # 注意: # ・上記の例ではコマンドが長いためバックスラッシュ「\」で区切り、 # 2行に分割して書いています。 # ・スラッシュの有無で引数の意味が大きく異なります。 # ・アップロードはグループ代表者一人が行ってください。 # パーミッションの都合上、レポート修正した後の再アップロードも # 同じ代表者じゃないとアップロードできません。
[手順2] 提出後、提出報告をメールにて連絡ください。
メールの件名は「(search1/mon/group1)」のように、テーマ名(search1)、曜日(monもしくはfri)、グループ番号」を含めるようにしてください。
[手順3] メールと提出ファイル一式を確認次第リプライを返します。
- プログラムのコードや実験結果をレポート中に含める場合には、必要十分に留めること。不必要に全ソースを掲載するのは×。
- レポート提出期限:月曜クラスは2/6(月)、金曜クラスは2/3(金)とする。(探索アルゴリズム2も同一日です)
提出期限を過ぎたら、原則的に、受け取りません。 期限内に仕上げる事も重要なタスクです。ただし、一般社会でも通用する理由で遅れてしまう場合にはこの限りではありません。同様に、延長希望等のリクエストも適宜相談次第で受け付けますので、なるべく早く相談してください。
- 口頭試問期限:レポート提出から1週間の期間(遅くとも1月中)を目安に、グループメンバ全員一緒に口頭試問を受けること。口頭試問の実施日は、空き時間目安ページ(後でURLを掲載します)を参考の上、レポート提出メールを送る際にでも希望日を連絡して下さい。
- 採点後、優秀なレポートを期間限定で公表します。
1. 最適化とは?
1.1. 前提1: コンピュータと人間の違い
(最適化が何なのかを考える前に・・・) コンピュータを利用して効率良く問題解決したい。そもそも効率良く問題解決する必要が無いならばコンピュータを利用する必要性はない。効率にもいろんな側面が考えられるが、ここでは特に制約を設けないものとする。
- Level 1.1 : コンピュータと人間の違いを述べよ (6点)
- コンピュータが人間より得意とするモノは何だろうか?逆に、人間より不得手のモノは?
1.2. 前提2: モデルとその良さの評価方法
様々な所で目にする「モデル」という用語には多種多様な意味がある。以下の「情報工学科学習教育目標」で述べる所のモデル化、もしくはモデルとは何を意味するのだろうか。デジタル大辞泉におけるどれに相当するのか例を交えて考えてみよう。
[課題解決能力と創造性] 情報工学の理論及び技術を総合的に活用し、与えられた制約下で創意工夫により課題を解決する。(情報工学科学習教育目標より転載。)
- G-1: 問題を分析し、モデル化を行い、課題を適切に設定する。
- G-2: 与えられた制約の下で、修得した知識と技術を総合して課題を解決するとともに、解決法を適切な評価尺度で評価する。
- G-3: 課題解決において創意工夫を行う。
モデル【model】(goo辞書(出典:デジタル大辞泉)より転載。)
- 1 模範・手本または標準となるもの。また、今後の範とするために試みられたもの。「緑化―地区」「―スクール」
- 2 模型。また、展示用の見本。「プラスチック―」
- 3 ある事象について、諸要素とそれら相互の関係を定式化して表したもの。「計量経済―」
- 4 美術家・写真家が制作の対象とする人や物。「ヌード―」
- 5 小説・戯曲などの題材となった実在の人や事件。「―小説」
- 6 「ファッションモデル」の略。
- 7 機械・自動車などの型式 (かたしき) 。型。「ニュー―」
- Level 1.2 : 住宅価格を推定するモデルを検討せよ (8点)
-
Housing Data Setでは、1978年におけるボストン郊外の住宅街について506サンプル分の平均データが集められている。各サンプルは「CRIM(犯罪率)、ZN(住宅街の比率)、RM(平均部屋数)」など13種類の属性データと、MEDV(平均価格)からなる合計14個の数値が付与されている。
下図はRMを横軸に、MEDVを縦軸に取り、実際のサンプルを紫の点でプロットしており、多くのデータは平均部屋数に比例した価格(右上がりの傾向)になっているように見える。この散布図を参考に、MEDVをRMから推定するためのモデルについて検討せよ。
注記:レポートでは、(1)モデルが何を入力をして受け取り、(2)受け取った入力をどう処理するのか、(3)そのモデルは何を出力するのか、の3点を含めて記述すること。
- Level 1.3 : モデルの良さを評価する方法について検討せよ。(9点)
-
目的意識: Level 1.2 で緑の線で書いたモデル「MEDV = 5*RM」は当てずっぽうで描いたものだが、どのぐらい適切に表現されているだろうか? 言い換えると、「適切さ」を計るための指標について検討せよ。なお、この指標は機械的に演算可能な物とする。
注記:レポートでは、(1)評価に用いる情報源を明示した上で、(2)評価手順を述べ、(3)その評価を用いてどう「適切さ」を計るのか、の3点を含めて記述すること。
[(3)の適切さの測り方についての補足]
例えば (1)+(2) を用いて「30」という値が出たとしよう。この値はどのような意味を持つだろうか?100点満点中30点という値なのか?特に上限はないけど高いほうが良いのか?それとも0に近いほど良い値なのか?etc. 算出した値をどう読めばよいのかを説明しよう。
1.3 まとめ
コンピュータは人間と比べると高速で飽きることなく同じ処理を繰り返しつづけられるが、計算資源が無限にある訳ではない。最適解が求まるに越したことは無いが、モデル化対象となる現象自体が時々刻々と変化するため最適解が求まるのに要する時間が長過ぎると「発見できた頃には使い物にならない」こともある。様々な理由で「良質の解(近似解)ならば十分満足できる」等、近似解を低コストで求めたいというニーズが往々にしてある。最適化におけるこのようなニーズに応える手法の一つである最急降下法を動かし、その近似解の質とコストの良し悪しについて観察してみよう。
2. 最急降下法によるモデルの最適化
Level 1.2, 1.3 で検討してきた「適切なモデル」を設計するための代表的な手法の一つに「最小二乗法」がある。しかし最小二乗法では、モデルに含まれるパラメータの数やサンプル数が増えすぎると計算リソースやコストが追いつかなくなってしまう(その問題がなければ最小二乗法で十分なケースが多い)。そこで、ここではより現実的な解法の一つである「最急降下法」を用いた最適化について考えてみよう。
- Level 2 : 最急降下法により求めた解の質(最適性)と、その解を見つけるのに要するコスト(効率性)について考察せよ。
-
Level 2.1 〜 2.3 に示した関数について、最急降下法により最小値を求めるプログラムを作成し、計算機実験により評価し、結果を示した上で考察せよ。なお、最適解を求める(発見する)にあたり、出発点となる解はランダムに選ばれるものとする。
アルゴリズムの簡単な説明
- 微分値を基に x を移動させる幅を決定する際、「xnext = x -α*f'(x)」により移動先を算出する。学習係数αは 0 より大きい実数とし、この値を変更する事でどのように探索が行われるかを観察せよ。
- 解 x の探索範囲は「-10 <= x <= 10」とする。
サンプルプログラムの利用方法
- サンプルソース:steepestsearch (リポジトリ)
- step 1: ソースのダウンロード。上記URLからダウンロードするか、リポジトリを複製して利用(下記)。
# e1557xxは各自のアカウントを指定すること。 hg clone ssh://e1557xx@shell.ie.u-ryukyu.ac.jp//net/home/hg/teacher/tnal/steepestsearch cd steepestsearch
- step 2: 各ファイルの説明は 0README_ja.txt を参照。
./0README_ja.txt このファイル. ./Makefile ./steepest-decent.c 探索プログラム本体(これだけ) ./run_ave.sh 10試行時の平均探索回数算出スクリプト。 ./trans_step_vs_func.sh 探索ステップ数あたりの目的関数推移図作成スクリプト。 ./trans_x_vs_func.sh (1変数用)探索時の挙動確認スクリプト。 ./trans_xy_vs_func.sh (2変数用)探索時の挙動確認スクリプト。
- step 3: 目的関数に合わせたプログラム変更。
Level 2.x 毎にプログラム steepest-decent.c を2, 3カ所変更する必要がある。3番目の関数 pdf_y() は2変数時のみ使用する。1変数時には、pd_y()は0を返せば良い。デフォルトでは y=x (Level 2.0) での記述をしている。
- double f(double x, double y): 関数 f(x) or f(x,y) の値を算出するように記述。
- double pd_x(double x, double y): xでの微分値 or 偏微分値を算出するように記述。
- double pd_y(double x, double y): yでの微分値 or 偏微分値を算出するように記述。
- step 4: 学習係数alphaの変更。
- step 5: コンパイル方法。
make コマンド1発でコンパイルできるはずです。エラーがでる場合には編集箇所がおかしい可能性あり。自分で解決できない場合にはTA or 教員に確認してください。
make
- step 6: シミュレーションの実行。
プログラムのコンパイルは make コマンドを実行するのみ。ここでエラーが出なければ ok。実行方法は下記4通りを用意している。基本的には(1)か(2)だけで十分実験が可能である。(3),(4)はオマケで用意したスクリプトである。
- (1) ./steepest_decent シード値
実行ファイルに直接シード値を指定して実行する方法。Level 2.0 でシード値を1として指定した際の実行結果例。シード値は探索点の初期値を設定するために使用しているため、シード値を変更する度に異なる探索点から出発する。
プログラムの終了条件は3つ。実行結果例ではFINISH 2で終了。
FINISH 1 step ...: 探索回数が term_cond (1000回)を越えた場合。 FINISH 2 step ...: 定義域 (-10 <= x <= +10) を外れた場合。 FINISH 3 step ...: 殆ど探索点が動いていない場合。
- (2) ./run_ave.sh
シード値を千刻み10パターン(1000〜10000)で実行し、FINISH 1〜3で終了した際の平均試行回数を出力。個別の詳細実行結果は「.archive-シード値」というファイルに保存される。終了条件を3つとも含んでいるため、「最適解を得るために要した平均試行回数」ではない点に注意。
- (3) ./trans_step_vs_func.sh 図タイトル シード値
試行回数(step)あたりの目的関数推移を線グラフで生成。例えば Level 2.1 でシード値1として実行する(下記)とこのような図が作成される。
./trans_step_vs_func.sh "y=x**2" 1 # 上記のように「シード値1」を指定すると、「sim-1.svg」グラフが生成される。
- (4) ./trans_x_vs_func.sh 関数 シード値
探索点が関数上をどのように推移しているかを可視化するスクリプト。例えば Level 2.1 でシード値1として実行する(下記)とこのような図が作成される。
./trans_x_vs_func.sh "x**2" 1 # 実行方法(3)と違い、第1引数は「gnuplotで作図する際の関数そのもの」である必要があります。 # 上記のように「シード値1」を指定すると、「sim-1.svg」グラフが生成される。
- (1) ./steepest_decent シード値
注記:レポートには下記4点を含めて報告すること。
- [Level2.1~2.3共通] 探索の手続き、フローチャート。
2.1~2.3で共通している報告事項はまとめて報告すること(同じ報告を繰り返す必要はありません)。
- プログラムソース(スクリプトを含む)。
レポート内には変更個所のみを記載した上で、ソース全体はアップロード提出すること。
- 観察意図と観察方法(実験計画)。コメント: どうやれば最適性or効率性を検討できるだろうか?
- 実行結果。
無駄に全てを示す必要はなく、第三者が読んでも理解できる程度に、必要十分に示すこと。
- 考察。
特に「学習係数が探索挙動に及ぼす影響」として「得られた解の質」と「効率性」について考察すること。 (どう検証したら良いだろうか?)
必要に応じて適切な図表を作成し、理解しやすい考察となるようにすること。
- Level 2.0 : y = x (例題)
-
例題のためレポートには不要です。
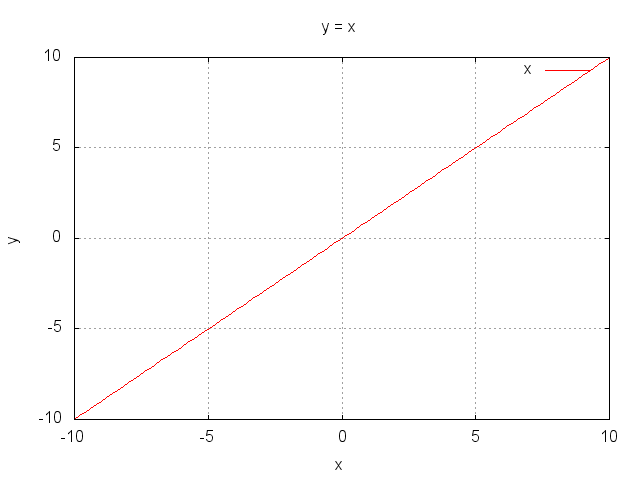
- 実行方法(1)での練習。
- 学習係数 alpha を固定したまま、シード値を変更して実行し、探索動作(出力結果)を確認してみよう。何がどう変わるだろうか?
- シード値を1のままで、学習係数 alpha を変更&コンパイルし直し、探索動作(出力結果)を確認してみよう。何がどう変わるだろうか?
- 実行方法(2)での練習。
- run_ave.sh を使い、最適解を求めるまでに要する平均試行回数を求めてみよう。本当に最適解が得られているかは、以下のようにすると確認しやすい。Level 2.0 の例では十分に x が -10 に近づいていればOK。
tail -1 .archive-*
- run_ave.sh を使い、最適解を求めるまでに要する平均試行回数を求めてみよう。本当に最適解が得られているかは、以下のようにすると確認しやすい。Level 2.0 の例では十分に x が -10 に近づいていればOK。
- 実行方法(1)での練習。
- Level 2.1 : y = x2 (12点)
-
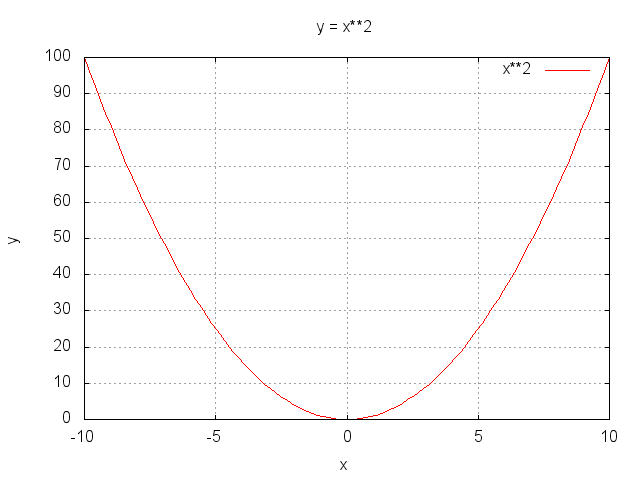
- 「傾きが0となる点」から最適解(最小値となる解)を求めた方が早い例。
- オマケ: (実行方法(3)での練習。)
- trans_step_vs_func.sh を使い、ステップあたりの目的関数推移図を作成してみよう。Level 2.1 の例では、ステップが進むにつれ y 軸が 0 に近づいていくなら正しく収束する方向に探索が進んでいることになる。
- オマケ: (実行方法(4)での練習。)
- trans_x_vs_func.sh を使い、探索点が関数上をどのように推移しているかを可視化してみよう。Level 2.1 の例では、0 に近づいていくなら正しく収束する方向に探索が進んでいることになる。
レポートに含める項目(再掲)
- プログラムソース(スクリプトを含む)。
レポート内には変更個所のみを記載した上で、ソース全体はアップロード提出すること。
- 観察意図と観察方法(実験計画)。コメント: どうやれば最適性or効率性を検討できるだろうか?
- 実行結果。
無駄に全てを示す必要はなく、第三者が読んでも理解できる程度に、必要十分に示すこと。
- 考察。
特に「学習係数が探索挙動に及ぼす影響」として「得られた解の質」と「効率性」について考察すること。 (どう検証したら良いだろうか?)
必要に応じて適切な図表を作成し、理解しやすい考察となるようにすること。
- Level 2.2 : z = x2+y2 (13点)
-
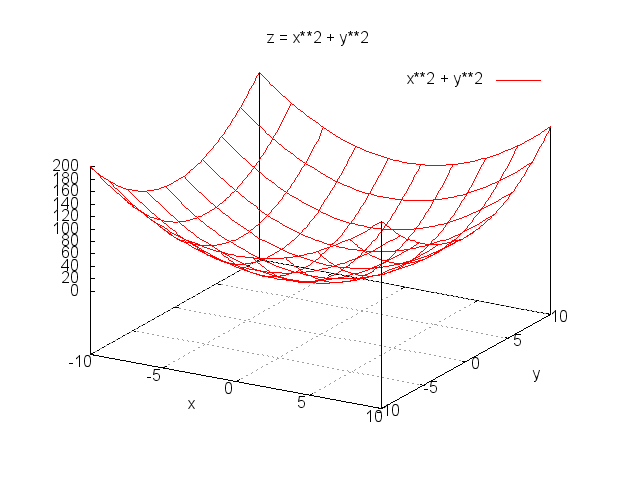
- 目的関数が2変数(x,y)の場合は、pd_y() も修正が必要。pd_x() はxによる偏微分値、pd_y() はyによる偏微分値を返すように記述すること。
レポートに含める項目(再掲)
- プログラムソース(スクリプトを含む)。
レポート内には変更個所のみを記載した上で、ソース全体はアップロード提出すること。
- 観察意図と観察方法(実験計画)。コメント: どうやれば最適性or効率性を検討できるだろうか?
- 実行結果。
無駄に全てを示す必要はなく、第三者が読んでも理解できる程度に、必要十分に示すこと。
- 考察。
特に「学習係数が探索挙動に及ぼす影響」として「得られた解の質」と「効率性」について考察すること。 (どう検証したら良いだろうか?)
必要に応じて適切な図表を作成し、理解しやすい考察となるようにすること。
- Level 2.3 : y = x*cos(x) (14点)
-
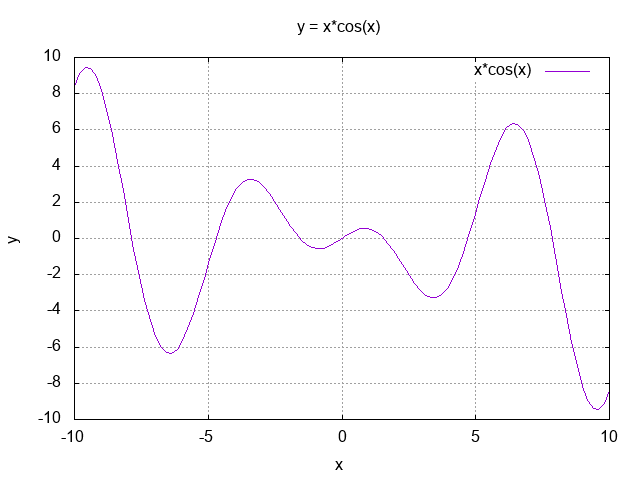
- ランダムな解からスタートするため、多峰の関数においては必ずしも最適解を発見できるとは限らない。このような場合、どのようにしたら最適解を獲得しやすくなるだろうか?
レポートに含める項目(再掲)
- プログラムソース(スクリプトを含む)。
レポート内には変更個所のみを記載した上で、ソース全体はアップロード提出すること。
- 観察意図と観察方法(実験計画)。コメント: どうやれば最適性or効率性を検討できるだろうか?
- 実行結果。
無駄に全てを示す必要はなく、第三者が読んでも理解できる程度に、必要十分に示すこと。
- 考察。
特に「学習係数が探索挙動に及ぼす影響」として「得られた解の質」と「効率性」について考察すること。 (どう検証したら良いだろうか?)
必要に応じて適切な図表を作成し、理解しやすい考察となるようにすること。
- Level 2.x: オプション課題例
-
- 結果の集計・解析ツール(言語は問わない)の作成と利活用。ソースにはコメントを付けること。
- 最急降下法以外の手法を実装する場合には、手法名・概要を説明した上で結果・考察を示す事。オリジナルの手法ならば詳細に説明する事。
3. レポート骨組み
レポート作成を分担して進めやすくするために、レポートの骨組みを用意しました。具体的には、input コマンドを用いて複数ファイルを読み込んで、一つのレポートを生成するようにしてあります。分類はあくまでも例ですので、分け方を変更してもらっても構いません。- ダウンロード: reportskel-search1.tgz
- 骨組みをコンパイルして生成できるPDFファイル: search1-utf8.pdf
- コンパイル方法
prompt> make
5. FAQ
- Level2編
- Q: 実行方法(4)の trans_x_vs_func.sh がうまく動かない。
- A: 第1引数は「gnuplotで作図する際の関数そのもの」を入力してください。例えば以下では y = x*x で、シード値1とする際の例を示しています。
./trans_x_vs_func.sh "x**2" 1 # 実行方法(3)と違い、第1引数は「gnuplotで作図する際の関数そのもの」 # である必要があります。
- Q: gnuplotでエラーがでる。or 実行方法(3)~(4)で図が作成されない。
- A: gnuplotが利用しているライブラリを次のコマンドで調べることができる。
otool -L `which gnuplot`
今回のシェルスクリプトではset terminal pdf(libpdfを利用)を指定しているが、インストールしているgnuplotの状態によってはそもそもlibpdfを組み込んでいないか、gnuplot本体との整合性が取れていないために作図時にエラーが出てしまうことがある。この場合には、次のようにシェルスクリプトを変更して作図しよう。- (1)set terminal を「postscript」に変更。
- (2)set output で保存するファイル名の拡張子をps or epsに変更。
- Q: 実験中のグループ活動で何をやって良いのか分からない。
- A: サンプルプログラムは「最急降下法で y=x における最小値を探索する」ように書かれています。そこで、まずはLevel2.1なり問題を選択して、その問題を解くようにプログラムを修正する必要があります。
[step1] プログラムの修正
まずはLevel2.1, 2.2, 2.3どれでも良いので一つ選択し、選択した関数におけるy=f(x)とy'=df(x)に書き換えて動作するようにしましょう。適切に動いているかは「xとyの関係」だけで判断できるはずです。
[step2] パラメータを変更して動作観察
想定した関数上で探索が進んでいることを確認したら、alphaやseedを変更して探索動作がどのように変わるかを観察しましょう。どちらを変更するかは「何を観察したいか」で選ぶことになります。alphaは「探索点の移動幅を調整するパラメータ」です。seedは「初期探索点を選ぶためのパラメータ」です。移動幅を大きくした時に探索点の移動がどのように変わるかを観察したいのならalphaを選択(変更)するべきでしょう。出発点を変えたときにどのように探索動作が変わるかを観察したいならseedを選択(変更)するべきでしょう。いきなり複数のパラメータを変更してしまうと、どちらのパラメータがどのように影響しているかを観察することが難しくなるため、一般的には「一つのパラメータの影響」を観察している最中は他のパラメータを固定しておき、観察対象のパラメータだけを少しずつずつ変更していき、傾向を探ることになるでしょう。今回は「最適性」と「効率性」という視点で考察できるように実験計画を練ってみてください。
- 参考文献・サイト
-
- 口頭試問調整用の記事
- 情報工学実験2/探索アルゴリズム1の口頭試問日調整(後でURLを書き直します)
- スクリプト等、実験環境関連
- google keywords: perl, ruby, gnuplot
- 実験1: Shell script と gnuplot の参考文献・サイト
- Gnuplot入門
- 探索、最適化、機械学習関連
- google keywords: 探索、最適化、連続関数、微分、不連続関数、近似解法、機械学習、損失関数、最小二乗法、勾配法
- AI リンク集@人工知能学会
- 人工知能のやさしい説明「What's AI」@人工知能学会
- 機械学習 はじめよう(学部生向けにも読みやすい連載記事)
- 朱鷺の杜Wiki(機械学習関連wiki)
- scikit-learn(Python用機械学習パッケージの一つ)
- TensorFlow(機械学習ライブラリ)
- MovieLens
- MovieLens Data Sets(GroupLens Research)
- 集合知プログラミング 2章 その11 MovieLensのデータを使った推薦をしてみる
- その他
- 口頭試問調整用の記事