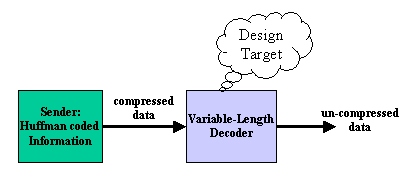
図1 システム図
琉球大学工学部情報工学科 和田 知久
今回はデジタルデータのデータ量削減のためにHUFFMAN符号を用いて圧縮されたデータを元データに戻す(デコード)するための、可変長符号デコーダ設計を行います。
音声圧縮であるMP3やAdvanced Audio Coding、画像圧縮であるJPEG、動画圧縮であるMPEG等は離散コサイン変換(DCT)等の変換と量子化を組み合わせてデータ圧縮を行っていることは有名ですが、そのようなデータも最終的にはHUFFMAN符号により符号化され、さらにデータ量が圧縮されます。このような音声、動画はリアルタイムで伝送されるアプリケーションに現在多様されていますので、今回の設計課題ではリアルタイムで伝送されてくるHUFFMAN符号に対してデコード処理を行い所望の出力をリアルタイムで出力する可変長符号デコーダを設計します。
学生対象のコンテストですので、小さめのデジタル回路を設計することを念頭に、符号長を実際に使用されている長さよりかなり短くし、取り扱いやすい大きさとします。また、いくつの設計オプションを設定し、各個人やチームによって色々な工夫ができるように、実現方法には自由度をある程度与えています。
要求されている設計内容はHDL(VHDLもしくはVerilogHDL)による設計と論理合成です。特にシノプシス社の合成ツールを使用する必要はなく、FPGA等の合成ツールでも参加できます。HDL設計に興味のある学生はどしどし参加してください。また、余裕のある方はFPGA等で実装すれば、努力を認めて高い評価が得られると思います。FPGA等での実装もぜひトライしてみてください。
図1 システム図
図1に可変長符号デコーディングシステムのブロック図を示します。システムは大きく分けて、ハフマン符号により圧縮されたデータを出力する送信部、その圧縮データをリアルタイムでデコードするデコーダに分か、今回の設計課題はその可変長符号デコーダです。
送信者はビット列を出力しますが、HUFFMAN符号は符号長が固定ではなく可変長であるのでデコーダ部はそのビット列を受信し、復号を行う時に同時に符号長を解析し、符号間の切れ目を自分で発見しながら処理を行う必要があります。
今回の課題ではHUFFMAN符号のの知識がなくても設計できるように、以下の仕様書でわかりやすく説明しています。設計すべきことは比較的単純ですので、デジタル設計の知識のある学生は自信を持って、課題に取り組んでください。
一つの例として、アルファベットA, B, C, D, Eの5つの文字からなる以下の文章があったとする。
CEACDABABCEABADACADABABADEACBADABCADAEE
トータルの文字数は39文字であり、以下の表1に出現頻度をまとめる
| 記号 | 出現頻度 |
| A | 15 |
| B | 7 |
| C | 6 |
| D | 6 |
| E | 5 |
表1 アルファベットの出現頻度
この表1を見るとA出現頻度が高いことになります。さて、この文章をデジタルデータとして取り扱うわけですが、もっとも単純な方法はそれぞれのアルファベットに対して1対1対応する固定長のビット列を対応させることで。以下の表2に固定長ビット列を対応させた例を表2に示します。
| 記号 | 出現頻度 | 対応ビット列 | トータルビット数 |
| A | 15 | 000 | 15*3=45 |
| B | 7 | 001 | 7*3=21 |
| C | 6 | 010 | 6*3=18 |
| D | 6 | 011 | 6*3=18 |
| E | 5 | 100 | 5*3=15 |
| Total 117bits |
表2 固定長符号
5つのアルファベットを区別するために3ビットの符号を使用しています。全体では39文字ですので、39*3=117ビットを用いてこの文章をデジタルで表現することが可能です。
上記例ではすべてのアルファベットに対して3ビットの符号を対応させましたが、Aの出現頻度が高いので、出現頻度の高いアルファベットに対してはビット長が短い符号を対応させれば全体として少ないビット数でこの文章をデジタル表現することが可能です。この時の符号の作り方の一つとしてHUFFMAN符号があります。HUFFMANのアルゴリズムを用いて作成した符号の例を表3に示します。
| 記号 | 出現頻度 | 対応ビット列 | 符号のビット長 | トータルビット数 |
| A | 15 | 0 | 1 | 15*1=15 |
| B | 7 | 100 | 3 | 7*3=21 |
| C | 6 | 101 | 3 | 6*3=18 |
| D | 6 | 110 | 3 | 6*3=18 |
| E | 5 | 111 | 3 | 5*3=15 |
| Total 87bits |
表3 HUFFMAN符号
表3のHUFFMAN符号を用いれば、BADという3文字の単語は1000110なる7ビットのビット列になります。逆に、01100111なるビット列が与えられた場合は最初のビットから解析して、ADAEと元の文字列を生成することができます。以下の復号の方法を図2に示します。
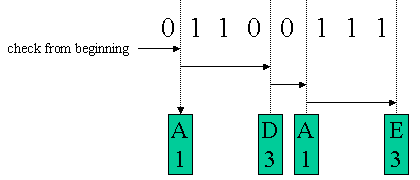
図2 HUFFMAN符号のデコード
01100111なるビット列の解析ですが先頭のビットより順に見てゆき、マッチするHUFFMAN符号を発見する必要があります。符号長が固定ではなく可変であるので前から順に解析しないと、次の符号との境界を発見することができません。図2の例では最初のビットから解析をスタートすると、まず符号’0’すなわちアルファベットAで符号長1の符号を発見します。この時点でAというデコード結果が得られ、符号長1なので、すぐ後に次の符号との境界があることが判明します。次にこの境界より解析を行います。3ビットを解析した時点で、符号’110’すなわち、アルファベットDで符号長3の符号を発見します。この時点でDというデコード結果が得られ、符号長3なので、図に示す位置に境界があることが判明します。
HUFFMAN符号では「どの符号も他の符号の先頭の一部と同じにならない」という条件が成立しており、上記の復号方で一意的に直ちに復号が可能なことが保証されています。
今回設計するデコーダは画像圧縮、伸張システムの一部であるとします。図3は今回取り扱う3ビットの白黒画像の例を示したものです。3ビットですので、8階調で0から7で示される白黒の画素を用います。
![]()
図3 白黒画像
図3の左側に8種類の画素を示します(図中の青い文字は画素の濃度を示す番号)。最も白い(明るい)画素は0であり、番号が大きくなるにつれて画素が黒に近づきます。8階調すなわち0から7の整数で示されますので、3ビットの符号で表すことができます。図3の右側のクロスマークの図は8X8=64ピクセルで構成されているので、単純には64X3=192ビットの画像となります。以下の表はこのクロスマークを可変長符号にて圧縮した場合のビット数の計算を示しています。最も出現頻度の高いPixel Number=0 (白)に符号長1の符号’1’が対応されており、トータルではクロスマーク画像を168bitで表現することができます。したがって、圧縮率は168/192 = 87.5%になります。
| Pixel Number | 出現頻度 | 符号 | 符号長 | トータルビット数 |
| 0(白) | 24 | 1 | 1 | 24 |
| 1 | 16 | 011 | 3 | 48 |
| 2 | 8 | 0101 | 4 | 32 |
| 3 | 2 | 0100 | 4 | 8 |
| 4 | 2 | 0011 | 4 | 8 |
| 5 | 4 | 0010 | 4 | 16 |
| 6 | 4 | 0001 | 4 | 16 |
| 7(黒) | 4 | 0000 | 4 | 16 |
| Total 168bit |
表4 クロスマーク画像のHUFFMAN符号化
以下にクロスマーク画像をPixel NumberとHUFFMAN符号化したものの両方をしめします。
| Pixel Number | Huffman Code | |||||||||||||||
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 0000 | 1 | 1 | 1 | 1 | 1 | 1 | 0000 | |
| 0 | 6 | 1 | 1 | 1 | 1 | 6 | 0 | 1 | 0001 | 011 | 011 | 011 | 011 | 0001 | 1 | |
| 0 | 1 | 5 | 2 | 2 | 5 | 1 | 0 | 1 | 011 | 0010 | 0101 | 0101 | 0010 | 011 | 1 | |
| 0 | 1 | 2 | 3 | 4 | 2 | 1 | 0 | 1 | 011 | 0101 | 0100 | 0011 | 0101 | 011 | 1 | |
| 0 | 1 | 2 | 4 | 3 | 2 | 1 | 0 | 1 | 011 | 0101 | 0011 | 0100 | 0101 | 011 | 1 | |
| 0 | 1 | 5 | 2 | 2 | 5 | 1 | 0 | 1 | 011 | 0010 | 0101 | 0101 | 0010 | 011 | 1 | |
| 0 | 6 | 1 | 1 | 1 | 1 | 6 | 0 | 1 | 0001 | 011 | 011 | 011 | 011 | 0001 | 1 | |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 0000 | 1 | 1 | 1 | 1 | 1 | 1 | 0000 | |
表5 クロスマーク画像データ
また以下にクロスマークをHUFFMAN符号化したデータ列を1次元的につなげたデータファイルをリンクします。
自分で中味を見て確かめてみてください。
クロス画像のHUFFMAN符号化データ: crossdata.txt
本セクションでは、セクション2示されたで圧縮された画像データのビット列からもとのPixel Numberデータを生成する(デコードする)方式の一例を示します。今回取り扱っている可変長符号の符号長は1から4ビットであり、最長でも4ビットです。したがって、4ビットの符号データから少なくとも1つのデータをデコードすることができます。具体例を表6に示します。
| 符号 | Pixel Number | |
| 4bitの符号から1つのPixel Numberがデコードされる場合 | 0001 | 6 |
| 4bitの符号から複数のPixel Numberがデコードされる場合 | 1111 | 0, 0, 0, 0 |
| 1011 | 0, 1 |
表6 デコード例

図4 可変長デコーダ アルゴリズム例
以下に図4のアルゴリズム例を説明します。
STEP1:
本アルゴリズム例では、入力データ列に対して4ビットの窓を設けます。4ビットの入力データに対して図4の右側に示すテーブルを検索します。表の最上段は’1’であり、入力の4ビットのMSBの1ビットが1であれば、その他のビットに関わらずこの行がマッチし、Pixel Number=0を出力し、同時にこの時の符号長1を出力します。
STEP2:
STEP1で符号長が1であったので、窓位置を1ビットずらした4ビット入力データを用意し、同様の作業を行います。上記例ではこの4ビットは"0110"であるので、MSBの3ビットが011にマッチするので、Pixel Number=1を出力し、同時にこの時の符号長3を出力します。
STEP3:
STEP2で符号長が3であったので、窓位置を3ビットずらし、次の4ビット入力データを用意し、以下同様の作業を行うことで、HUFFMAN符号のデコードが可能となります。
さて、上記セクション3で述べた復号アルゴリズムをどのようなハードウエア構成で実現できるか、例を示して説明します。
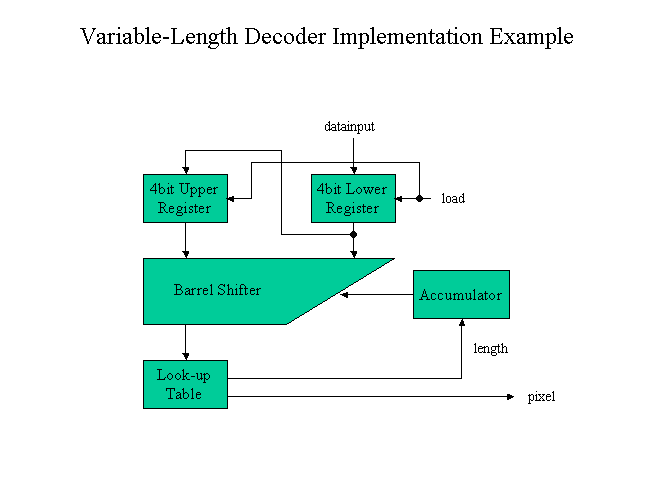
図5 可変長デコーダ アーキテクチャ例
このアーキテクチャ例では、4ビットのレジスタを2個装備しています。スライディングウインドウを動かす関係で、この8ビットの内のどこかの4ビットを選択し、LOOK-UPテーブルの内容を検索する必要があります。
LOOK-UPテーブルの検索結果より、デコードされたPixel Number出力と、符号長Lengthが得られます。Lengthにしたがって、次のスライディングウインドウの位置を決める必要があり、その機能をAccumulatorとBarrel Shifterで実現しています。
回路の動作周波数を決めるクリティカルパスはBarrel Shifter -> Look-up Table -> Accumulator -> Barrel Shifterであり、高速化のためにはこのあたりの回路構成の工夫が必要と思われます。
今回設計するシステムの構成を図6に示します。システムは大きくわけて、SENDER(送信器)とVLD(可変長符号デコーダ)からなります。
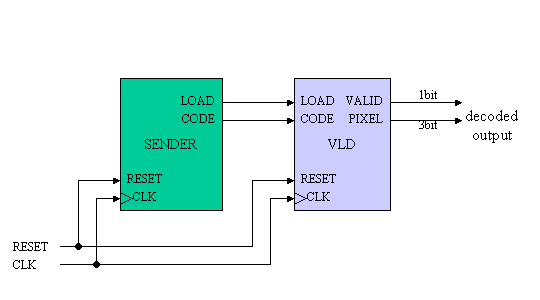
図6 システム構成図
(SENDER:送信器の説明)
SENDERはセクション2で説明したHUFFMAN符号化された画像データを出力します。
CODE出力は符号化された画像データ出力信号であり、下記の符号化データが出力されます。
クロス画像のHUFFMAN符号化データ: crossdata.txt
LOAD出力は1ビット出力であり、CODE出力がVALID(正しい)時に’1’となり、CODEデータの出力を示します。
(VLD:可変長符号デコーダの説明)
VLDはSENDERからのHUFFMAN符号化圧縮された符号をCODE入力より受け取り、内部で復号処理を行い、復号結果をPIXEL端子に出力します。PIXEL信号は0から7の整数値を示すので、3ビットの信号となります。
また、PIXEL端子からの出力信号がVALID(正しい)ことを示す信号がVALIDです。
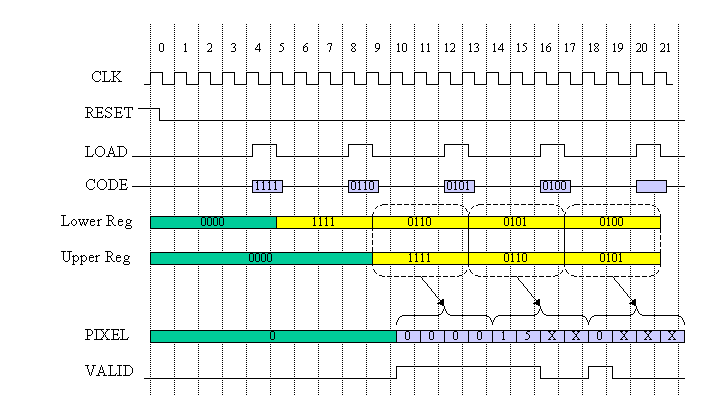
図7 システム動作タイミング図
図7に動作タイミング図を示します。RESET信号の解除の後、SENDERはCODE出力を行います。このタイミング図では以下のCODEを出力しています。
CODE出力: 1111011001010100....
このタイミングではCODE信号は4ビット幅であり、4サイクルおきにLOAD信号が’1’にアサートされ4ビット幅のCODE入力がLowerレジスタに取り込まれています。次のLOAD信号により次の4ビットCODE信号がLowerレジスタに取り込まれると同時に以前のLowerレジスタの内容はUpperレジスタにシフトされます。
UpperレジスタとLowerレジスタの8ビットを先頭から解析し、復号処理を行いPIXEL出力に復号結果を出力し、PIXEL出力が正しい場合にVALID出力を’1’にアサートします。
復号処理はUpperレジスタ内の値のすべてを復号するまで行い、Upperレジスタ内のビットを先頭とし不足分のビットをLowerレジスタより用います。Upperレジスタ内のビットすべての復号が終了すれば、復号は一時停止し、VALID出力を’0’とします。
4ビットのUpperレジスタに対して最大で、4回のPIXEL出力をする必要があるので、上記タイミング図のように4サイクルごとにCODEデータが入力されるようにしています。
基本課題では以下の信号ビット幅とします。
|
VLD |
|||
| 信号名 | 入出力 | ビット幅 | 説明 |
| CLK | IN | 1 | クロック入力 |
| RESET | IN | 1 | ’1’でリセット |
| CODE | IN | 4 | HUFFMAN符号入力 |
| LOAD | IN | 1 | 符号入力ロード信号 |
| PIXEL | OUT | 3 | 復号されたPIXEL NUMBER出力 |
| VALID | OUT | 1 | PIXEL NUMBER出力VALID信号 |
表7 基本課題用ビット幅
以下に送信機SENDER、全体シュミレーションのVHDLファイルをリンクします。必要に応じて修正して使用してください。
送信機: sender.vhd
全体テストベンチ: test_vld.vhd
LEVEL2では詳細な仕様は自由とします。
クロス画像のHUFFMAN符号化データ: crossdata.txt
に格納されたデータを復号するデコーダであればどんなアーキテクチャ、タイミング動作でもOKとします。
琉球大学以外からの参加の場合、同一のシノプシスデザインコンパイラの論理合成用ライブラリを使用することが困難であるので、以下のような多段EXOR回路を例に従って合成し最適化して頂き、その1段あたりの遅延時間を単位時間としてスピードの単位とします。
多段EXOR回路のVHDLソース例:50入力のEXOR回路
この例では6段のEXOR段が合成され、クリティカルパス遅延はreport_timingコマンドにより7.17であったので、7.17/6=1.195を単位(UNIT)とします。
例えば、ある遅延が20ならば、20/1.195=17.74UNIT遅延とする。
琉大情報のライブラリ使用者は上記値で換算で換算すればよいです。
ちなみに面積はreport_areaコマンドのtotal cell areaにあります。
レポートには以下の内容を含めるてください。また、ページ数を少なめにコンパクトにまとめること。
| 表紙 | 1 | 代表者の氏名、チーム名、大学院修士/大学学部生/高専生の区別 |
| 2 | 共同設計者全員の名前(最高3名まで)、学籍番号、学年、学校名、住所、電話、email等連絡先 | |
| 3 | 全員のTシャツの希望サイズ | |
| 4 | 取り組んだ課題(LEVEL1/LEVEL2) | |
| 内容 | 1 | 設計した回路ブロックの構成説明(ブロック図と説明) |
| 2 | 設計した回路ブロックの動作説明(動作波形図やパイプライン動作等の説明) | |
| 3 | 工夫した点、オリジナリティを出した点(アピールが重要!) | |
| 4 | クリティカルパスのスピード、論理合成後の回路規模 | |
| 5 | VHDLもしくはVerilogのコード | |
| 6 | 正常動作しているVHDL/Verilogシミュレーション波形 | |
| 7 | その他自由意見など |
レポートはPDFファイルにて下記にEMAILにて提出すること!
他の形式での提出希望あれば、相談してください。
締め切りは2003年2月14日(金)必着です。
ENJOY HDL! 沖縄で会おう!