30. 事前学習済みモデルmT5を用いたMultilingual NMTの例#
Transformersモデルの一つ101言語をカバーするT5モデルmT5を用いて、機械翻訳学習する流れを追いかけてみよう。
全体の流れ
注意点
環境構築
関連モジュールの用意(import)
Tokenizer, Modelの用意(事前学習済みモデルの用意)
Transforersを使う際の Tips
トークナイザの動作確認
タスクに向けた専用トークンを追加
データセットの準備
ファインチューニング方針
データセット前処理
前処理の動作確認
ファインチューニング部分
パラメータやモデル評価関数を準備
ファインチューニング
学習中の損失推移
ファインチューニングしたモデルで翻訳してみる
参考
今回の原本(original): Multilingual NMT mt5
英語ですが、動画解説あり。
30.1. 注意点#
専用の仮想環境構築を推奨する。
機械学習ライブラリHugging FaceのTransformersは、関連ライブラリのバージョン依存度が高いことから専用の仮想環境を構築することが推奨されている。自身の環境で試す際には venv で別途環境構築することを推奨する。
CUDA環境での実行を推奨する。
動作確認することを主眼としているため、系列長やエポック数を小さく設定している。それでもCPU環境では1エポックに1時間程度かかる。時間がない人はCUDA環境(Google Colab)での実行を推奨する。
CPUで実行する際にはコードの一部を編集する必要がある。
コード中に
.cuda()と付けている箇所は、CUDA環境が必須である。これを消せばCPU環境でも動作するようになる。
30.2. 環境構築#
仮想環境に入った状態で、下記のコメントアウトを外して実行しよう。
!pip install transformers sentencepiece datasets
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: transformers in /usr/local/lib/python3.7/dist-packages (4.20.1)
Requirement already satisfied: sentencepiece in /usr/local/lib/python3.7/dist-packages (0.1.96)
Requirement already satisfied: datasets in /usr/local/lib/python3.7/dist-packages (2.3.2)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.7/dist-packages (from transformers) (21.3)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.7/dist-packages (from transformers) (6.0)
Requirement already satisfied: huggingface-hub<1.0,>=0.1.0 in /usr/local/lib/python3.7/dist-packages (from transformers) (0.8.1)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.7/dist-packages (from transformers) (4.64.0)
Requirement already satisfied: tokenizers!=0.11.3,<0.13,>=0.11.1 in /usr/local/lib/python3.7/dist-packages (from transformers) (0.12.1)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from transformers) (2.23.0)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from transformers) (2022.6.2)
Requirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from transformers) (4.11.4)
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.7/dist-packages (from transformers) (1.21.6)
Requirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from transformers) (3.7.1)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.7/dist-packages (from huggingface-hub<1.0,>=0.1.0->transformers) (4.1.1)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from packaging>=20.0->transformers) (3.0.9)
Requirement already satisfied: dill<0.3.6 in /usr/local/lib/python3.7/dist-packages (from datasets) (0.3.5.1)
Requirement already satisfied: aiohttp in /usr/local/lib/python3.7/dist-packages (from datasets) (3.8.1)
Requirement already satisfied: pyarrow>=6.0.0 in /usr/local/lib/python3.7/dist-packages (from datasets) (6.0.1)
Requirement already satisfied: fsspec[http]>=2021.05.0 in /usr/local/lib/python3.7/dist-packages (from datasets) (2022.5.0)
Requirement already satisfied: responses<0.19 in /usr/local/lib/python3.7/dist-packages (from datasets) (0.18.0)
Requirement already satisfied: pandas in /usr/local/lib/python3.7/dist-packages (from datasets) (1.3.5)
Requirement already satisfied: multiprocess in /usr/local/lib/python3.7/dist-packages (from datasets) (0.70.13)
Requirement already satisfied: xxhash in /usr/local/lib/python3.7/dist-packages (from datasets) (3.0.0)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (1.25.11)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2.10)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2022.6.15)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (3.0.4)
Requirement already satisfied: attrs>=17.3.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets) (21.4.0)
Requirement already satisfied: frozenlist>=1.1.1 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets) (1.3.0)
Requirement already satisfied: charset-normalizer<3.0,>=2.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets) (2.0.12)
Requirement already satisfied: asynctest==0.13.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets) (0.13.0)
Requirement already satisfied: multidict<7.0,>=4.5 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets) (6.0.2)
Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets) (4.0.2)
Requirement already satisfied: aiosignal>=1.1.2 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets) (1.2.0)
Requirement already satisfied: yarl<2.0,>=1.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets) (1.7.2)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->transformers) (3.8.0)
Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas->datasets) (2022.1)
Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/dist-packages (from pandas->datasets) (2.8.2)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.7.3->pandas->datasets) (1.15.0)
30.3. 関連モジュールの用意#
from datasets import load_dataset
#from google.colab import drive
#from IPython.display import display
#from IPython.html import widgets
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import torch
from torch import optim
from torch.nn import functional as F
from transformers import AdamW, AutoModelForSeq2SeqLM, AutoTokenizer
from transformers import get_linear_schedule_with_warmup
from tqdm import tqdm_notebook
sns.set()
30.4. Tokenizer, Modelの準備#
Transformersを利用するには大別して、(1)まっさらな状態から事前学習する、(2)事前学習済みモデルを用いてファインチューニングする、(3)ファインチューニング済みモデルを利用する、の3パターンが考えられる。
ここでは(2)を体験してみよう。最終的にやりたいことは機械翻訳(日英、英日)だ。このタスクのために今回は事前学習済みモデルとしてmT5を準備する。mT5は “Text-to-Text Transfer Transformer” (T5) と呼ばれる Google が開発したモデルをベースとし、多言語(101言語)で事前学習されたモデルだ。
参考
公式で用意されている事前学習済みモデルはMODELSを参照しよう。
一般開発者を含めたコミュニティで公開されているモデルはここから検索しよう。
Note
事前学習済みモデルを利用する場合、事前学習時に用いたトークナイザ(≒分かち書き器)を利用する必要がある点に注意しよう。
model_repo = 'google/mt5-small' # 事前学習済みモデル
model_path = 'mt5_translation.pt' # ファインチューニングしたモデルを保存する際のファイル名
max_seq_len = 20 # トークン上限数。計算機リソースや学習時間に余裕があるなら増やしてみよう。
# トークナイザを準備
tokenizer = AutoTokenizer.from_pretrained(model_repo)
# 事前学習済みモデルを準備
model = AutoModelForSeq2SeqLM.from_pretrained(model_repo)
# 環境がCUDA対応してるなら、以下を実行することで高速実行可能。
# CPU実行したい場合にはコメントアウトしよう。
model = model.cuda()
/usr/local/lib/python3.7/dist-packages/transformers/convert_slow_tokenizer.py:435: UserWarning: The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option which is not implemented in the fast tokenizers. In practice this means that the fast version of the tokenizer can produce unknown tokens whereas the sentencepiece version would have converted these unknown tokens into a sequence of byte tokens matching the original piece of text.
"The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option"
30.5. Transformers を使う際の Tips#
学習時に用いたトークナイザを用いる必要がある。
あるトークナイザXでは
thisをid = 1として割り振っているとしよう。このトークナイザXを使って学習したモデルにとっては1 == thisである。しかしファインチューニング時に別のトークナイザを使ってしまうと、idがずれたり、存在しない事もありえる。このような問題を起こさないためには事前学習とファインチューニングで用いるトークナイザを合わせる必要がある。
モデルは、エンコードされた系列データでやり取りする。
モデルに対する入出力は「エンコードされた系列データ」である。分かち書きされたトークンに対しユニークなtoken_idを割り振り(これをエンコードと呼ぶ)、token_idを並べた系列データをモデルは受け取り、処理結果も同様のtoken_id系列データとして出力する。以下を実行して確認してみよう。
系列長は固定する必要がある。
例えば固定長10で学習したモデルに対しては、それ未満の系列データを入力する場合には不足分を埋める必要がある。このためのトークンを padding token と呼ぶ。逆に10を超える系列データを入力する場合には、事前にサイズ10で打ち切る、もしくは文末トークンを考慮し9で打ち切る必要がある。
30.6. トークナイザの動作確認#
# テキスト例
example_input_str = 'This is test.'
# tokenizer.encode() でエンコード。
token_ids = tokenizer.encode(
example_input_str, # 入力したいテキスト
return_tensors='pt').cuda() # PyTorchのテンソル型を指定
print('token_ids = ', token_ids)
print('-----------')
# 試しにモデルに入力して、その結果を受け取ってみる。
model_out = model.generate(token_ids)
print('model_out = ', model_out)
print('-----------')
# 分かりづらいので、出力結果を元の文字に戻す。
output_text = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(model_out[0]))
print('output_text = ', output_text)
token_ids = tensor([[1494, 339, 2978, 260, 1]], device='cuda:0')
-----------
model_out = tensor([[ 0, 250099, 1]], device='cuda:0')
-----------
output_text = <pad> <extra_id_0></s>
# token_ids をもとに戻してみる。
# id=1 が </s> になっている。これは文末を表す特殊トークン。
tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens([1494, 339, 2978, 260, 1]))
'This is test.</s>'
# トークン一覧を確認
# <pad>: padding用のトークン。トークン長を揃えるためのもの。
# </s>: 文末トークン。
# <unk>: unknownトークン。未知語は全てこれになる。
print(len(tokenizer.vocab))
sorted(tokenizer.vocab.items(), key=lambda x: x[1])
250100
[('<pad>', 0),
('</s>', 1),
('<unk>', 2),
('<0x00>', 3),
('<0x01>', 4),
('<0x02>', 5),
('<0x03>', 6),
('<0x04>', 7),
('<0x05>', 8),
('<0x06>', 9),
('<0x07>', 10),
('<0x08>', 11),
('<0x09>', 12),
('<0x0A>', 13),
('<0x0B>', 14),
('<0x0C>', 15),
('<0x0D>', 16),
('<0x0E>', 17),
('<0x0F>', 18),
('<0x10>', 19),
('<0x11>', 20),
('<0x12>', 21),
('<0x13>', 22),
('<0x14>', 23),
('<0x15>', 24),
('<0x16>', 25),
('<0x17>', 26),
('<0x18>', 27),
('<0x19>', 28),
('<0x1A>', 29),
('<0x1B>', 30),
('<0x1C>', 31),
('<0x1D>', 32),
('<0x1E>', 33),
('<0x1F>', 34),
('<0x20>', 35),
('<0x21>', 36),
('<0x22>', 37),
('<0x23>', 38),
('<0x24>', 39),
('<0x25>', 40),
('<0x26>', 41),
('<0x27>', 42),
('<0x28>', 43),
('<0x29>', 44),
('<0x2A>', 45),
('<0x2B>', 46),
('<0x2C>', 47),
('<0x2D>', 48),
('<0x2E>', 49),
('<0x2F>', 50),
('<0x30>', 51),
('<0x31>', 52),
('<0x32>', 53),
('<0x33>', 54),
('<0x34>', 55),
('<0x35>', 56),
('<0x36>', 57),
('<0x37>', 58),
('<0x38>', 59),
('<0x39>', 60),
('<0x3A>', 61),
('<0x3B>', 62),
('<0x3C>', 63),
('<0x3D>', 64),
('<0x3E>', 65),
('<0x3F>', 66),
('<0x40>', 67),
('<0x41>', 68),
('<0x42>', 69),
('<0x43>', 70),
('<0x44>', 71),
('<0x45>', 72),
('<0x46>', 73),
('<0x47>', 74),
('<0x48>', 75),
('<0x49>', 76),
('<0x4A>', 77),
('<0x4B>', 78),
('<0x4C>', 79),
('<0x4D>', 80),
('<0x4E>', 81),
('<0x4F>', 82),
('<0x50>', 83),
('<0x51>', 84),
('<0x52>', 85),
('<0x53>', 86),
('<0x54>', 87),
('<0x55>', 88),
('<0x56>', 89),
('<0x57>', 90),
('<0x58>', 91),
('<0x59>', 92),
('<0x5A>', 93),
('<0x5B>', 94),
('<0x5C>', 95),
('<0x5D>', 96),
('<0x5E>', 97),
('<0x5F>', 98),
('<0x60>', 99),
('<0x61>', 100),
('<0x62>', 101),
('<0x63>', 102),
('<0x64>', 103),
('<0x65>', 104),
('<0x66>', 105),
('<0x67>', 106),
('<0x68>', 107),
('<0x69>', 108),
('<0x6A>', 109),
('<0x6B>', 110),
('<0x6C>', 111),
('<0x6D>', 112),
('<0x6E>', 113),
('<0x6F>', 114),
('<0x70>', 115),
('<0x71>', 116),
('<0x72>', 117),
('<0x73>', 118),
('<0x74>', 119),
('<0x75>', 120),
('<0x76>', 121),
('<0x77>', 122),
('<0x78>', 123),
('<0x79>', 124),
('<0x7A>', 125),
('<0x7B>', 126),
('<0x7C>', 127),
('<0x7D>', 128),
('<0x7E>', 129),
('<0x7F>', 130),
('<0x80>', 131),
('<0x81>', 132),
('<0x82>', 133),
('<0x83>', 134),
('<0x84>', 135),
('<0x85>', 136),
('<0x86>', 137),
('<0x87>', 138),
('<0x88>', 139),
('<0x89>', 140),
('<0x8A>', 141),
('<0x8B>', 142),
('<0x8C>', 143),
('<0x8D>', 144),
('<0x8E>', 145),
('<0x8F>', 146),
('<0x90>', 147),
('<0x91>', 148),
('<0x92>', 149),
('<0x93>', 150),
('<0x94>', 151),
('<0x95>', 152),
('<0x96>', 153),
('<0x97>', 154),
('<0x98>', 155),
('<0x99>', 156),
('<0x9A>', 157),
('<0x9B>', 158),
('<0x9C>', 159),
('<0x9D>', 160),
('<0x9E>', 161),
('<0x9F>', 162),
('<0xA0>', 163),
('<0xA1>', 164),
('<0xA2>', 165),
('<0xA3>', 166),
('<0xA4>', 167),
('<0xA5>', 168),
('<0xA6>', 169),
('<0xA7>', 170),
('<0xA8>', 171),
('<0xA9>', 172),
('<0xAA>', 173),
('<0xAB>', 174),
('<0xAC>', 175),
('<0xAD>', 176),
('<0xAE>', 177),
('<0xAF>', 178),
('<0xB0>', 179),
('<0xB1>', 180),
('<0xB2>', 181),
('<0xB3>', 182),
('<0xB4>', 183),
('<0xB5>', 184),
('<0xB6>', 185),
('<0xB7>', 186),
('<0xB8>', 187),
('<0xB9>', 188),
('<0xBA>', 189),
('<0xBB>', 190),
('<0xBC>', 191),
('<0xBD>', 192),
('<0xBE>', 193),
('<0xBF>', 194),
('<0xC0>', 195),
('<0xC1>', 196),
('<0xC2>', 197),
('<0xC3>', 198),
('<0xC4>', 199),
('<0xC5>', 200),
('<0xC6>', 201),
('<0xC7>', 202),
('<0xC8>', 203),
('<0xC9>', 204),
('<0xCA>', 205),
('<0xCB>', 206),
('<0xCC>', 207),
('<0xCD>', 208),
('<0xCE>', 209),
('<0xCF>', 210),
('<0xD0>', 211),
('<0xD1>', 212),
('<0xD2>', 213),
('<0xD3>', 214),
('<0xD4>', 215),
('<0xD5>', 216),
('<0xD6>', 217),
('<0xD7>', 218),
('<0xD8>', 219),
('<0xD9>', 220),
('<0xDA>', 221),
('<0xDB>', 222),
('<0xDC>', 223),
('<0xDD>', 224),
('<0xDE>', 225),
('<0xDF>', 226),
('<0xE0>', 227),
('<0xE1>', 228),
('<0xE2>', 229),
('<0xE3>', 230),
('<0xE4>', 231),
('<0xE5>', 232),
('<0xE6>', 233),
('<0xE7>', 234),
('<0xE8>', 235),
('<0xE9>', 236),
('<0xEA>', 237),
('<0xEB>', 238),
('<0xEC>', 239),
('<0xED>', 240),
('<0xEE>', 241),
('<0xEF>', 242),
('<0xF0>', 243),
('<0xF1>', 244),
('<0xF2>', 245),
('<0xF3>', 246),
('<0xF4>', 247),
('<0xF5>', 248),
('<0xF6>', 249),
('<0xF7>', 250),
('<0xF8>', 251),
('<0xF9>', 252),
('<0xFA>', 253),
('<0xFB>', 254),
('<0xFC>', 255),
('<0xFD>', 256),
('<0xFE>', 257),
('<0xFF>', 258),
('▁', 259),
('.', 260),
(',', 261),
('a', 262),
('s', 263),
('-', 264),
('e', 265),
('i', 266),
(':', 267),
('o', 268),
('▁de', 269),
('t', 270),
(')', 271),
('n', 272),
('u', 273),
('▁(', 274),
('/', 275),
('y', 276),
("'", 277),
('en', 278),
('и', 279),
('l', 280),
('▁in', 281),
('m', 282),
('▁la', 283),
('com', 284),
('d', 285),
('r', 286),
('▁the', 287),
('▁to', 288),
('▁en', 289),
('_', 290),
('?', 291),
('、', 292),
('’', 293),
('▁na', 294),
('er', 295),
(';', 296),
('c', 297),
('▁A', 298),
('es', 299),
('▁v', 300),
('▁di', 301),
('...', 302),
('▁se', 303),
('▁of', 304),
('▁and', 305),
('。', 306),
('▁|', 307),
('а', 308),
('!', 309),
('▁на', 310),
('"', 311),
('(', 312),
('▁"', 313),
('k', 314),
('▁в', 315),
('b', 316),
('▁c', 317),
('g', 318),
('▁que', 319),
('▁S', 320),
('an', 321),
('▁–', 322),
('▁www', 323),
('е', 324),
('p', 325),
('▁m', 326),
('▁sa', 327),
('3', 328),
('x', 329),
('▁b', 330),
('▁d', 331),
('▁for', 332),
('▁1', 333),
('h', 334),
('▁un', 335),
('▁I', 336),
('os', 337),
('2', 338),
('▁is', 339),
('▁le', 340),
('▁و', 341),
('▁do', 342),
('،', 343),
('▁at', 344),
('ed', 345),
('te', 346),
('ing', 347),
('in', 348),
('=', 349),
('▁da', 350),
('▁on', 351),
('▁M', 352),
('1', 353),
('у', 354),
('▁đ', 355),
('▁2', 356),
('A', 357),
('as', 358),
('▁“', 359),
('z', 360),
('é', 361),
('▁el', 362),
('▁P', 363),
('▁B', 364),
('”', 365),
('▁T', 366),
('f', 367),
('de', 368),
('à', 369),
('ng', 370),
('▁C', 371),
('ar', 372),
('▁og', 373),
('▁за', 374),
('▁no', 375),
('ه', 376),
('na', 377),
('।', 378),
('v', 379),
('re', 380),
('▁3', 381),
('▁h', 382),
('▁et', 383),
('▁je', 384),
('j', 385),
('▁il', 386),
('▁#', 387),
('▁с', 388),
('і', 389),
('▁be', 390),
('://', 391),
('▁2018', 392),
('▁per', 393),
('▁th', 394),
('▁si', 395),
('я', 396),
('▁z', 397),
('▁die', 398),
('S', 399),
('▁te', 400),
('▁не', 401),
('▁ال', 402),
('D', 403),
('▁«', 404),
('ne', 405),
('ی', 406),
('da', 407),
('▁k', 408),
('|', 409),
('4', 410),
('о', 411),
('▁K', 412),
('▁du', 413),
('▁w', 414),
('▁E', 415),
('▁me', 416),
('is', 417),
('▁are', 418),
('▁4', 419),
('í', 420),
('▁p', 421),
('ta', 422),
('の', 423),
('C', 424),
('▁по', 425),
('▁del', 426),
('▁ka', 427),
('5', 428),
('et', 429),
('▁5', 430),
('▁D', 431),
('▁ja', 432),
('ы', 433),
('▁V', 434),
('▁para', 435),
('»', 436),
('","', 437),
('us', 438),
(']', 439),
('▁al', 440),
('▁N', 441),
('▁der', 442),
('▁O', 443),
('on', 444),
('ة', 445),
('▁да', 446),
('▁H', 447),
('▁ne', 448),
('8', 449),
('▁con', 450),
('6', 451),
('B', 452),
('▁er', 453),
('ul', 454),
('▁by', 455),
('▁у', 456),
('▁yang', 457),
('▁L', 458),
('▁De', 459),
('0', 460),
('▁an', 461),
('ja', 462),
('\xad', 463),
('▁van', 464),
('▁ה', 465),
('▁za', 466),
('】【', 467),
('le', 468),
('▁dan', 469),
('em', 470),
('á', 471),
('▁und', 472),
('al', 473),
('è', 474),
('▁10', 475),
('to', 476),
('ي', 477),
('E', 478),
('ka', 479),
('▁...', 480),
('w', 481),
('▁på', 482),
(').', 483),
('ly', 484),
('▁po', 485),
('▁The', 486),
('7', 487),
('":"', 488),
('▁G', 489),
('T', 490),
('▁[', 491),
('la', 492),
('的', 493),
('li', 494),
('9', 495),
('▁ma', 496),
('▁0', 497),
('▁des', 498),
('▁med', 499),
('▁til', 500),
('▁La', 501),
('kan', 502),
('it', 503),
('▁ki', 504),
('no', 505),
('),', 506),
('м', 507),
('َ', 508),
('▁در', 509),
('▁so', 510),
('M', 511),
('▁som', 512),
('▁ke', 513),
('▁with', 514),
('▁F', 515),
('ni', 516),
('▁su', 517),
('▁και', 518),
('▁por', 519),
('▁les', 520),
('▁you', 521),
('si', 522),
('at', 523),
('ti', 524),
('id', 525),
('▁av', 526),
('▁as', 527),
('▁ya', 528),
('▁ve', 529),
('▁den', 530),
('▁R', 531),
('▁ב', 532),
('▁that', 533),
('▁tr', 534),
('は', 535),
('が', 536),
('do', 537),
('N', 538),
('ia', 539),
('\\', 540),
('ce', 541),
('▁om', 542),
('й', 543),
('▁се', 544),
('F', 545),
('&', 546),
('L', 547),
('▁م', 548),
('▁&', 549),
('▁د', 550),
('▁det', 551),
('▁от', 552),
('ó', 553),
('▁به', 554),
('▁pa', 555),
('▁من', 556),
('K', 557),
('на', 558),
('P', 559),
('▁ha', 560),
('V', 561),
('▁ch', 562),
('▁In', 563),
('▁W', 564),
('▁„', 565),
('I', 566),
('▁var', 567),
('▁ni', 568),
('se', 569),
('▁6', 570),
('ra', 571),
('ل', 572),
('▁una', 573),
('を', 574),
('▁في', 575),
('▁ta', 576),
('▁http', 577),
('COM', 578),
('am', 579),
('ה', 580),
('▁U', 581),
('R', 582),
('▁з', 583),
('▁re', 584),
('▁op', 585),
('ن', 586),
('т', 587),
('▁har', 588),
('ο', 589),
('H', 590),
('“', 591),
('ek', 592),
('▁ag', 593),
('▁ng', 594),
('▁los', 595),
('{', 596),
('▁och', 597),
('▁2017', 598),
('▁WWW', 599),
('に', 600),
('▁ku', 601),
('ir', 602),
('▁pe', 603),
('un', 604),
('х', 605),
('um', 606),
('▁2019', 607),
('je', 608),
('▁it', 609),
('▁до', 610),
('을', 611),
('ʻ', 612),
('www', 613),
('▁ب', 614),
('▁li', 615),
('но', 616),
('▁7', 617),
('▁»', 618),
('▁ir', 619),
('▁kan', 620),
('G', 621),
('▁het', 622),
('▁ho', 623),
('▁par', 624),
('▁vi', 625),
('・', 626),
('で', 627),
('▁20', 628),
('▁të', 629),
('▁8', 630),
('▁or', 631),
('ا', 632),
('م', 633),
('ie', 634),
('▁В', 635),
('ت', 636),
('ом', 637),
('W', 638),
('▁was', 639),
('την', 640),
('▁के', 641),
('▁En', 642),
('▁af', 643),
('▁12', 644),
('me', 645),
('O', 646),
('nya', 647),
('ma', 648),
('의', 649),
('ki', 650),
('▁cu', 651),
('μ', 652),
('▁No', 653),
('▁2016', 654),
('▁es', 655),
('▁een', 656),
('ки', 657),
('▁mi', 658),
('Ð', 659),
('10', 660),
('▁—', 661),
('ku', 662),
('":', 663),
('▁J', 664),
('px', 665),
('일', 666),
('▁ל', 667),
('ни', 668),
('>', 669),
('▁15', 670),
('▁‘', 671),
('▁ver', 672),
('▁um', 673),
('▁man', 674),
('▁ko', 675),
('+', 676),
('▁nh', 677),
('η', 678),
('ка', 679),
('ny', 680),
('α', 681),
('▁od', 682),
('▁wa', 683),
('▁ge', 684),
('ов', 685),
('н', 686),
('ten', 687),
('▁С', 688),
('▁מ', 689),
('▁ph', 690),
('▁>', 691),
('▁men', 692),
('▁ber', 693),
('▁του', 694),
('▁از', 695),
('il', 696),
('ch', 697),
('▁bir', 698),
('▁το', 699),
('▁να', 700),
('el', 701),
('▁from', 702),
('▁nu', 703),
('ko', 704),
('st', 705),
('ë', 706),
('▁lo', 707),
('ủ', 708),
('▁az', 709),
('▁dem', 710),
('mi', 711),
('▁va', 712),
('▁att', 713),
('▁this', 714),
('ur', 715),
('▁nie', 716),
('#', 717),
('▁gi', 718),
('▁tu', 719),
('di', 720),
('å', 721),
('ات', 722),
('or', 723),
('▁em', 724),
('と', 725),
('ת', 726),
('▁Na', 727),
('▁am', 728),
('▁из', 729),
('▁11', 730),
('▁pro', 731),
('▁în', 732),
('▁30', 733),
('▁che', 734),
('для', 735),
('▁Z', 736),
('ru', 737),
('▁can', 738),
('ya', 739),
('▁ang', 740),
('ai', 741),
('▁f', 742),
('ga', 743),
('▁+', 744),
('za', 745),
('▁Se', 746),
('이', 747),
('ю', 748),
('▁mit', 749),
('ca', 750),
('▁all', 751),
('▁של', 752),
('ke', 753),
('",', 754),
('°', 755),
('▁tak', 756),
('ने', 757),
('▁bu', 758),
('▁bo', 759),
('▁zu', 760),
('ą', 761),
('ή', 762),
('▁pour', 763),
('▁Le', 764),
('[', 765),
('▁ت', 766),
('▁ter', 767),
('▁با', 768),
('ci', 769),
('▁és', 770),
('co', 771),
('▁your', 772),
('om', 773),
('▁9', 774),
('▁کے', 775),
('▁not', 776),
('их', 777),
('▁к', 778),
('▁din', 779),
('im', 780),
('q', 781),
('ă', 782),
('▁have', 783),
('▁mai', 784),
('▁{', 785),
('▁pre', 786),
('▁we', 787),
('▁Re', 788),
('▁El', 789),
('▁he', 790),
('ς', 791),
('▁•', 792),
('và', 793),
('Y', 794),
('▁von', 795),
('▁là', 796),
('ې', 797),
('▁ar', 798),
('▁16', 799),
('▁las', 800),
('ú', 801),
('app', 802),
('▁کی', 803),
('▁au', 804),
('▁при', 805),
('U', 806),
('th', 807),
('▁}', 808),
('▁2014', 809),
('▁ba', 810),
('be', 811),
('▁18', 812),
('X', 813),
('▁2015', 814),
('▁2013', 815),
('▁(1)', 816),
('ой', 817),
('▁14', 818),
('▁qu', 819),
('ِ', 820),
('ha', 821),
('▁می', 822),
('man', 823),
('▁met', 824),
('are', 825),
('▁nga', 826),
('▁das', 827),
('▁της', 828),
('‘', 829),
('▁है', 830),
('ية', 831),
('то', 832),
('ь', 833),
('va', 834),
('ba', 835),
('】', 836),
('▁bi', 837),
('日', 838),
('한', 839),
('▁24', 840),
('ر', 841),
('ى', 842),
('▁est', 843),
('▁में', 844),
('lar', 845),
('▁2012', 846),
('▁dengan', 847),
('年', 848),
('▁13', 849),
('▁με', 850),
('▁untuk', 851),
('▁Y', 852),
(');', 853),
('▁ini', 854),
('▁ש', 855),
('▁ist', 856),
('ve', 857),
('▁ا', 858),
('▁im', 859),
('this', 860),
('est', 861),
('▁online', 862),
('न', 863),
('▁А', 864),
('▁sur', 865),
('J', 866),
('▁У', 867),
('ך', 868),
('은', 869),
('ado', 870),
('▁ti', 871),
('ہ', 872),
('에', 873),
('ri', 874),
('▁för', 875),
('tu', 876),
('▁25', 877),
('lo', 878),
('」', 879),
('den', 880),
('%', 881),
('▁א', 882),
('د', 883),
('▁את', 884),
('▁có', 885),
('▁pas', 886),
('="', 887),
('▁ein', 888),
('ou', 889),
('▁mu', 890),
('月', 891),
('▁что', 892),
('ого', 893),
('*', 894),
('ի', 895),
('ים', 896),
('р', 897),
('▁will', 898),
('▁fa', 899),
('net', 900),
('▁για', 901),
('д', 902),
('ê', 903),
('▁*', 904),
('ُ', 905),
('ada', 906),
('▁qui', 907),
('ới', 908),
('г', 909),
('▁over', 910),
('▁17', 911),
('▁από', 912),
('ها', 913),
(',"', 914),
('ā', 915),
('▁را', 916),
('▁со', 917),
('та', 918),
('▁ser', 919),
('л', 920),
('que', 921),
('▁так', 922),
('▁про', 923),
('ể', 924),
('ok', 925),
('▁To', 926),
('▁σ', 927),
('▁და', 928),
('가', 929),
('ό', 930),
('ción', 931),
('ak', 932),
('ị', 933),
('▁که', 934),
('▁non', 935),
('ן', 936),
('▁је', 937),
('ro', 938),
('「', 939),
('ag', 940),
('ان', 941),
('على', 942),
('▁आ', 943),
('ите', 944),
('да', 945),
('с', 946),
('▁się', 947),
('▁€', 948),
('▁mo', 949),
('▁است', 950),
('▁·', 951),
('ý', 952),
('▁این', 953),
('Р', 954),
('▁if', 955),
('▁für', 956),
('не', 957),
('▁como', 958),
('▁X', 959),
('▁ca', 960),
('▁är', 961),
('ní', 962),
('▁19', 963),
('▁co', 964),
('▁כ', 965),
('▁100', 966),
('ere', 967),
('▁að', 968),
('wa', 969),
('▁cho', 970),
('▁voor', 971),
('▁2020', 972),
('▁میں', 973),
('و', 974),
('▁की', 975),
('ji', 976),
('▁Đ', 977),
('も', 978),
('▁pri', 979),
('▁este', 980),
('▁2011', 981),
('▁ce', 982),
('▁О', 983),
('▁է', 984),
('ik', 985),
('ት', 986),
('▁21', 987),
('는', 988),
('ку', 989),
('ж', 990),
('ے', 991),
('▁во', 992),
('ç', 993),
('ে', 994),
('п', 995),
('र', 996),
('Z', 997),
('▁од', 998),
('▁ob', 999),
...]
# 短いトークン系列に対して padding する例。
# パラメータ padding でパディング方法を指定。'max_length'とすると、max_lengthで指定した長さになるまでパディングする。
example_input_str = 'This is test.'
token_ids = tokenizer.encode(
example_input_str, return_tensors='pt', padding='max_length',
truncation=True, max_length=max_seq_len).cuda()
print('token_ids = ', token_ids)
print('len(token_ids[0]) = ', len(token_ids[0]))
tokens = tokenizer.convert_ids_to_tokens(token_ids[0])
print('tokens = ', tokens)
print('len(tokens) =', len(tokens))
token_ids = tensor([[1494, 339, 2978, 260, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]], device='cuda:0')
len(token_ids[0]) = 20
tokens = ['▁This', '▁is', '▁test', '.', '</s>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']
len(tokens) = 20
# 長いトークン系列に対して打ち切りする例。
# パラメータ trancation を Trueにする。
long_example_input_str = 'The mT5 model was presented in mT5: A massively multilingual pre-trained text-to-text transformer by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.'
length = len(example_input_str.split())
print('length = ', length)
token_ids = tokenizer.encode(
example_input_str, return_tensors='pt', padding='max_length',
truncation=True, max_length=max_seq_len).cuda()
print('token_ids = ', token_ids)
print('len(token_ids[0]) = ', len(token_ids[0]))
tokens = tokenizer.convert_ids_to_tokens(token_ids[0])
print('tokens = ', tokens)
print('len(tokens) = ', len(tokens))
length = 3
token_ids = tensor([[1494, 339, 2978, 260, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]], device='cuda:0')
len(token_ids[0]) = 20
tokens = ['▁This', '▁is', '▁test', '.', '</s>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']
len(tokens) = 20
30.7. タスクに向けた専用トークンの追加#
翻訳して欲しいということを伝えやすくするために専用のトークンを追加しよう。具体的には以下の通り。
日本語に翻訳して欲しい場合の書式:
<jp> This is test.英語に翻訳してほしい場合の書式:
<en> これはテストです。
# トークンの確認。
# <jp>, <en> はトークンが存在せず別トークン系列に分解されてしまうので、新しいトークンとして追加する。
example_input_str = '<jp> This is test.'
token_ids = tokenizer.encode(
example_input_str, return_tensors='pt', padding='max_length',
truncation=True, max_length=max_seq_len).cuda()
print('token_ids = ', token_ids)
tokens = tokenizer.convert_ids_to_tokens(token_ids[0])
print('tokens = ', tokens)
token_ids = tensor([[1042, 3889, 669, 1494, 339, 2978, 260, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]], device='cuda:0')
tokens = ['▁<', 'jp', '>', '▁This', '▁is', '▁test', '.', '</s>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']
example_input_str = '<en> これはテストです。'
token_ids = tokenizer.encode(
example_input_str, return_tensors='pt', padding='max_length',
truncation=True, max_length=max_seq_len).cuda()
print('token_ids = ', token_ids)
tokens = tokenizer.convert_ids_to_tokens(token_ids[0])
print('tokens = ', tokens)
token_ids = tensor([[ 1042, 278, 669, 144591, 80822, 1252, 306, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]], device='cuda:0')
tokens = ['▁<', 'en', '>', '▁これは', 'テスト', 'です', '。', '</s>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']
# 追加したいトークンを辞書型で用意。
LANG_TOKEN_MAPPING = {
'ja': '<jp>',
'en': '<en>'
}
print('元のボキャブラリ数 = ', len(tokenizer.vocab))
# tokenizer.add_special_tokens を使って追加。
# 追加したことをモデルにも伝える必要がある。
special_tokens_dict = {'additional_special_tokens': list(LANG_TOKEN_MAPPING.values())}
tokenizer.add_special_tokens(special_tokens_dict) # 専用トークン追加。
print('追加後のボキャブラリ数 = ', len(tokenizer.vocab))
model.resize_token_embeddings(len(tokenizer)) # モデルのembeddingを調整。
元のボキャブラリ数 = 250100
追加後のボキャブラリ数 = 250102
Embedding(250102, 512)
# トークン追加後の動作確認。
# <ja> が一つのトークンとして処理されていることを確認。
example_input_str = '<jp> This is test.'
token_ids = tokenizer.encode(
example_input_str, return_tensors='pt', padding='max_length',
truncation=True, max_length=max_seq_len).cuda()
print('token_ids = ', token_ids)
tokens = tokenizer.convert_ids_to_tokens(token_ids[0])
print('tokens = ', tokens)
token_ids = tensor([[250100, 1494, 339, 2978, 260, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]], device='cuda:0')
tokens = ['<jp>', '▁This', '▁is', '▁test', '.', '</s>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']
30.8. データセットの準備#
ファインチューニングするためのデータセットを用意しよう。今回は13言語での対訳があるaltを使う。
30.8.1. データセット外観#
train, testが別途用意されており、それぞれ辞書型で保存されている。
dataset['url']: ソースURLdataset['translation']: 対訳テキストdataset['translation']['ja']: 日本語テキストdataset['translation']['en']: 英語テキスト
# Source: https://huggingface.co/datasets/alt
dataset = load_dataset('alt')
train_dataset = dataset['train']
test_dataset = dataset['test']
No config specified, defaulting to: alt/alt-parallel
Reusing dataset alt (/root/.cache/huggingface/datasets/alt/alt-parallel/1.0.0/e784a3f2a9f6bdf277940de6cc9d700eab852896cd94aad4233caf26008da9ed)
# 中身を確認してみよう。
train_dataset[0]
{'SNT.URLID': '80188',
'SNT.URLID.SNTID': '1',
'translation': {'bg': 'ফ্রান্সের প্যারিসের পার্ক দি প্রিন্সেস-এ হওয়া ২০০৭-এর রাগবি বিশ্বকাপের পুল সি-তে ইটালি পর্তুগালকে ৩১-৫ গোলে হারিয়েছে।',
'en': 'Italy have defeated Portugal 31-5 in Pool C of the 2007 Rugby World Cup at Parc des Princes, Paris, France.',
'en_tok': 'Italy have defeated Portugal 31-5 in Pool C of the 2007 Rugby World Cup at Parc des Princes , Paris , France .',
'fil': 'Natalo ng Italya ang Portugal sa puntos na 31-5 sa Grupong C noong 2007 sa Pandaigdigang laro ng Ragbi sa Parc des Princes, Paris, France.',
'hi': '2007 में फ़्रांस, पेरिस के पार्क डेस प्रिंसेस में हुए रग्बी विश्व कप के पूल C में इटली ने पुर्तगाल को 31-5 से हराया।',
'id': 'Italia berhasil mengalahkan Portugal 31-5 di grup C dalam Piala Dunia Rugby 2007 di Parc des Princes, Paris, Perancis.',
'ja': 'フランスのパリ、パルク・デ・プランスで行われた2007年ラグビーワールドカップのプールCで、イタリアは31対5でポルトガルを下した。',
'khm': 'អ៊ីតាលីបានឈ្នះលើព័រទុយហ្គាល់ 31-5 ក្នុងប៉ូលCនៃពីធីប្រកួតពានរង្វាន់ពិភពលោកនៃកីឡាបាល់ឱបឆ្នាំ2007ដែលប្រព្រឹត្តនៅប៉ាសឌេសប្រីន ក្រុងប៉ារីស បារាំង។',
'lo': 'ອິຕາລີໄດ້ເສຍໃຫ້ປ໊ອກຕຸຍການ 31 ຕໍ່ 5 ໃນພູລ C ຂອງ ການແຂ່ງຂັນຣັກບີ້ລະດັບໂລກປີ 2007 ທີ່ ປາກເດແພຣັງ ປາຣີ ປະເທດຝຣັ່ງ.',
'ms': 'Itali telah mengalahkan Portugal 31-5 dalam Pool C pada Piala Dunia Ragbi 2007 di Parc des Princes, Paris, Perancis.',
'my': 'ပြင်သစ်နိုင်ငံ ပါရီမြို့ ပါ့ဒက်စ် ပရင့်စက် ၌ ၂၀၀၇ခုနှစ် ရပ်ဘီ ကမ္ဘာ့ ဖလား တွင် အီတလီ သည် ပေါ်တူဂီ ကို ၃၁-၅ ဂိုး ဖြင့် ရေကူးကန် စီ တွင် ရှုံးနိမ့်သွားပါသည် ။',
'th': 'อิตาลีได้เอาชนะโปรตุเกสด้วยคะแนน31ต่อ5 ในกลุ่มc ของการแข่งขันรักบี้เวิลด์คัพปี2007 ที่สนามปาร์กเดแพร็งส์ ที่กรุงปารีส ประเทศฝรั่งเศส',
'vi': 'Ý đã đánh bại Bồ Đào Nha với tỉ số 31-5 ở Bảng C Giải vô địch Rugby thế giới 2007 tại Parc des Princes, Pari, Pháp.',
'zh': '意大利在法国巴黎王子公园体育场举办的2007年橄榄球世界杯C组以31-5击败葡萄牙。'},
'url': 'http://en.wikinews.org/wiki/2007_Rugby_World_Cup:_Italy_31_-_5_Portugal'}
print("train_dataset[0]['translation']['ja'] = ", train_dataset[0]['translation']['ja'])
print("train_dataset[0]['translation']['en'] = ", train_dataset[0]['translation']['en'])
train_dataset[0]['translation']['ja'] = フランスのパリ、パルク・デ・プランスで行われた2007年ラグビーワールドカップのプールCで、イタリアは31対5でポルトガルを下した。
train_dataset[0]['translation']['en'] = Italy have defeated Portugal 31-5 in Pool C of the 2007 Rugby World Cup at Parc des Princes, Paris, France.
30.9. ファインチューニング方針#
mT5への入出力データを対訳で用意する。
やりたい翻訳は日英または英日のみだが、ファインチューニングでは言語を問わず対訳学習させる。
元の対訳文にはテキストのみが書かれているため、データセットとして利用する際には専用トークン
<ja>, <en>を追加する。
30.9.1. データセット前処理#
# モデルへの入力分をエンコードする関数。
# テキスト本文(text)に専用トークン(target_lang)を追加し、tokenizerでエンコード。
# 戻り値は token_id 系列。
def encode_input_str(text, target_lang, tokenizer, seq_len,
lang_token_map=LANG_TOKEN_MAPPING):
target_lang_token = lang_token_map[target_lang]
# Tokenize and add special tokens
input_ids = tokenizer.encode(
text = target_lang_token + text,
return_tensors = 'pt',
padding = 'max_length',
truncation = True,
max_length = seq_len).cuda()
return input_ids[0]
# 対訳テキスト本文(text)をエンコード。ここでは専用トークンを追加しない。
def encode_target_str(text, tokenizer, seq_len,
lang_token_map=LANG_TOKEN_MAPPING):
token_ids = tokenizer.encode(
text = text,
return_tensors = 'pt',
padding = 'max_length',
truncation = True,
max_length = seq_len).cuda()
return token_ids[0]
# 上で用意した関数を使って、
# 翻訳対象テキスト(input_text)と翻訳後テキスト(target_text)の系列データを用意する。
# 実行する度に dataset['translation'] からランダムに2言語を選び、処理する。
def format_translation_data(translations, lang_token_map,
tokenizer, seq_len=128):
# Choose a random 2 languages for in i/o
langs = list(lang_token_map.keys())
input_lang, target_lang = np.random.choice(langs, size=2, replace=False)
# Get the translations for the batch
input_text = translations[input_lang]
target_text = translations[target_lang]
if input_text is None or target_text is None:
return None
input_token_ids = encode_input_str(
input_text, target_lang, tokenizer, seq_len, lang_token_map)
target_token_ids = encode_target_str(
target_text, tokenizer, seq_len, lang_token_map)
return input_token_ids, target_token_ids
# format_translation_dataを使ってバッチデータを作成。
def transform_batch(batch, lang_token_map, tokenizer):
inputs = []
targets = []
for translation_set in batch['translation']:
formatted_data = format_translation_data(
translation_set, lang_token_map, tokenizer, max_seq_len)
if formatted_data is None:
continue
input_ids, target_ids = formatted_data
inputs.append(input_ids.unsqueeze(0))
targets.append(target_ids.unsqueeze(0))
batch_input_ids = torch.cat(inputs).cuda() # CPU実行したいなら、.cuda()を外そう。
batch_target_ids = torch.cat(targets).cuda()
#batch_input_ids = torch.cat(inputs) # CPU実行の例。
#batch_target_ids = torch.cat(targets)
return batch_input_ids, batch_target_ids
# transform_batchを効率よく作成するために yield で返す。
def get_data_generator(dataset, lang_token_map, tokenizer, batch_size=32):
dataset = dataset.shuffle()
for i in range(0, len(dataset), batch_size):
raw_batch = dataset[i:i+batch_size]
yield transform_batch(raw_batch, lang_token_map, tokenizer)
30.9.2. 前処理の動作確認#
train_dataset[0] を指定しているが、その中のどの言語を指定するかはランダム選択しているため、実行する都度結果が変わる。
# Testing `data_transform`
in_ids, out_ids = format_translation_data(
train_dataset[0]['translation'], LANG_TOKEN_MAPPING, tokenizer)
print(' '.join(tokenizer.convert_ids_to_tokens(in_ids)))
print(' '.join(tokenizer.convert_ids_to_tokens(out_ids)))
# Testing data generator
data_gen = get_data_generator(train_dataset, LANG_TOKEN_MAPPING, tokenizer, 8)
data_batch = next(data_gen)
print('Input shape:', data_batch[0].shape)
print('Output shape:', data_batch[1].shape)
Loading cached shuffled indices for dataset at /root/.cache/huggingface/datasets/alt/alt-parallel/1.0.0/e784a3f2a9f6bdf277940de6cc9d700eab852896cd94aad4233caf26008da9ed/cache-09ad8735b58de120.arrow
<jp> ▁Italy ▁have ▁de feat ed ▁Portugal ▁3 1-5 ▁in ▁Pool ▁C ▁of ▁the ▁2007 ▁ Rugby ▁World ▁Cup ▁at ▁Parc ▁des ▁Princes , ▁Paris , ▁France . </s> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
▁ フランス の パリ 、 パル ク ・ デ ・ プラン ス で 行われた 2007 年 ラグビー ワールド カップ の プール C で 、 イタリア は 31 対 5 で ポル ト ガル を下 した 。 </s> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
Input shape: torch.Size([8, 20])
Output shape: torch.Size([8, 20])
30.10. ファインチューニング部分#
30.10.1. パラメータやモデル評価関数を準備#
# Constants
n_epochs = 5 # エポック数
batch_size = 16 # バッチサイズ
print_freq = 50 # 途中経過を出力するタイミング(50バッチ毎に出力)
checkpoint_freq = 1000 # モデルを保存するタイミング(1000バッチ毎に上書き保存)
lr = 5e-4 # 学習率
n_batches = int(np.ceil(len(train_dataset) / batch_size))
total_steps = n_epochs * n_batches
n_warmup_steps = int(total_steps * 0.01) # 学習率の減衰スケジューラ。徐々に減らしていく。
# Optimizer
optimizer = AdamW(model.parameters(), lr=lr)
scheduler = get_linear_schedule_with_warmup(
optimizer, n_warmup_steps, total_steps)
# 損失履歴を保存するリスト
losses = []
/usr/local/lib/python3.7/dist-packages/transformers/optimization.py:310: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
FutureWarning,
# モデルを評価する関数。
# test_dataset を受け取り、平均損失を計算。
def eval_model(model, gdataset, max_iters=8):
test_generator = get_data_generator(gdataset, LANG_TOKEN_MAPPING,
tokenizer, batch_size)
eval_losses = []
for i, (input_batch, label_batch) in enumerate(test_generator):
if i >= max_iters:
break
model_out = model.forward(
input_ids = input_batch,
labels = label_batch)
eval_losses.append(model_out.loss.item())
return np.mean(eval_losses)
30.10.2. ファインチューニング#
!date
Thu Jun 23 01:54:04 UTC 2022
for epoch_idx in range(n_epochs):
# Randomize data order
data_generator = get_data_generator(train_dataset, LANG_TOKEN_MAPPING,
tokenizer, batch_size)
for batch_idx, (input_batch, label_batch) \
in tqdm_notebook(enumerate(data_generator), total=n_batches):
optimizer.zero_grad()
# Forward pass
model_out = model.forward(
input_ids = input_batch,
labels = label_batch)
# Calculate loss and update weights
loss = model_out.loss
losses.append(loss.item())
loss.backward()
optimizer.step()
scheduler.step()
# Print training update info
if (batch_idx + 1) % print_freq == 0:
avg_loss = np.mean(losses[-print_freq:])
print('Epoch: {} | Step: {} | Avg. loss: {:.3f} | lr: {}'.format(
epoch_idx+1, batch_idx+1, avg_loss, scheduler.get_last_lr()[0]))
if (batch_idx + 1) % checkpoint_freq == 0:
test_loss = eval_model(model, test_dataset)
print('Saving model with test loss of {:.3f}'.format(test_loss))
torch.save(model.state_dict(), model_path)
torch.save(model.state_dict(), model_path)
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:6: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
Epoch: 1 | Step: 50 | Avg. loss: 12.114 | lr: 0.00044642857142857147
Epoch: 1 | Step: 100 | Avg. loss: 5.509 | lr: 0.0004960707269155207
Epoch: 1 | Step: 150 | Avg. loss: 4.604 | lr: 0.0004916056438649759
Epoch: 1 | Step: 200 | Avg. loss: 4.273 | lr: 0.00048714056081443114
Epoch: 1 | Step: 250 | Avg. loss: 3.990 | lr: 0.0004826754777638864
Epoch: 1 | Step: 300 | Avg. loss: 3.813 | lr: 0.0004782103947133417
Epoch: 1 | Step: 350 | Avg. loss: 3.695 | lr: 0.00047374531166279694
Epoch: 1 | Step: 400 | Avg. loss: 3.614 | lr: 0.0004692802286122522
Epoch: 1 | Step: 450 | Avg. loss: 3.558 | lr: 0.0004648151455617075
Epoch: 1 | Step: 500 | Avg. loss: 3.488 | lr: 0.00046035006251116275
Epoch: 1 | Step: 550 | Avg. loss: 3.353 | lr: 0.00045588497946061796
Epoch: 1 | Step: 600 | Avg. loss: 3.444 | lr: 0.00045141989641007323
Epoch: 1 | Step: 650 | Avg. loss: 3.339 | lr: 0.0004469548133595285
Epoch: 1 | Step: 700 | Avg. loss: 3.293 | lr: 0.00044248973030898376
Epoch: 1 | Step: 750 | Avg. loss: 3.236 | lr: 0.000438024647258439
Epoch: 1 | Step: 800 | Avg. loss: 3.169 | lr: 0.0004335595642078943
Epoch: 1 | Step: 850 | Avg. loss: 3.172 | lr: 0.00042909448115734957
Epoch: 1 | Step: 900 | Avg. loss: 3.106 | lr: 0.0004246293981068048
Epoch: 1 | Step: 950 | Avg. loss: 3.086 | lr: 0.00042016431505626005
Epoch: 1 | Step: 1000 | Avg. loss: 3.030 | lr: 0.0004156992320057153
Saving model with test loss of 3.238
Epoch: 1 | Step: 1050 | Avg. loss: 2.993 | lr: 0.0004112341489551706
Epoch: 1 | Step: 1100 | Avg. loss: 3.027 | lr: 0.0004067690659046258
Epoch: 2 | Step: 50 | Avg. loss: 2.793 | lr: 0.00039953563136274335
Epoch: 2 | Step: 100 | Avg. loss: 2.830 | lr: 0.0003950705483121986
Epoch: 2 | Step: 150 | Avg. loss: 2.841 | lr: 0.00039060546526165383
Epoch: 2 | Step: 200 | Avg. loss: 2.805 | lr: 0.00038614038221110916
Epoch: 2 | Step: 250 | Avg. loss: 2.833 | lr: 0.00038167529916056437
Epoch: 2 | Step: 300 | Avg. loss: 2.753 | lr: 0.00037721021611001964
Epoch: 2 | Step: 350 | Avg. loss: 2.841 | lr: 0.00037274513305947496
Epoch: 2 | Step: 400 | Avg. loss: 2.804 | lr: 0.0003682800500089302
Epoch: 2 | Step: 450 | Avg. loss: 2.737 | lr: 0.00036381496695838544
Epoch: 2 | Step: 500 | Avg. loss: 2.722 | lr: 0.00035934988390784066
Epoch: 2 | Step: 550 | Avg. loss: 2.758 | lr: 0.000354884800857296
Epoch: 2 | Step: 600 | Avg. loss: 2.777 | lr: 0.0003504197178067512
Epoch: 2 | Step: 650 | Avg. loss: 2.766 | lr: 0.00034595463475620646
Epoch: 2 | Step: 700 | Avg. loss: 2.671 | lr: 0.00034148955170566173
Epoch: 2 | Step: 750 | Avg. loss: 2.723 | lr: 0.000337024468655117
Epoch: 2 | Step: 800 | Avg. loss: 2.715 | lr: 0.00033255938560457226
Epoch: 2 | Step: 850 | Avg. loss: 2.779 | lr: 0.0003280943025540275
Epoch: 2 | Step: 900 | Avg. loss: 2.690 | lr: 0.0003236292195034828
Epoch: 2 | Step: 950 | Avg. loss: 2.731 | lr: 0.000319164136452938
Epoch: 2 | Step: 1000 | Avg. loss: 2.715 | lr: 0.0003146990534023933
Saving model with test loss of 2.839
Epoch: 2 | Step: 1050 | Avg. loss: 2.688 | lr: 0.00031023397035184855
Epoch: 2 | Step: 1100 | Avg. loss: 2.738 | lr: 0.0003057688873013038
Epoch: 3 | Step: 50 | Avg. loss: 2.425 | lr: 0.0002985354527594213
Epoch: 3 | Step: 100 | Avg. loss: 2.475 | lr: 0.0002940703697088766
Epoch: 3 | Step: 150 | Avg. loss: 2.477 | lr: 0.00028960528665833185
Epoch: 3 | Step: 200 | Avg. loss: 2.508 | lr: 0.00028514020360778707
Epoch: 3 | Step: 250 | Avg. loss: 2.466 | lr: 0.0002806751205572424
Epoch: 3 | Step: 300 | Avg. loss: 2.468 | lr: 0.00027621003750669766
Epoch: 3 | Step: 350 | Avg. loss: 2.477 | lr: 0.00027174495445615287
Epoch: 3 | Step: 400 | Avg. loss: 2.448 | lr: 0.00026727987140560814
Epoch: 3 | Step: 450 | Avg. loss: 2.454 | lr: 0.0002628147883550634
Epoch: 3 | Step: 500 | Avg. loss: 2.456 | lr: 0.0002583497053045187
Epoch: 3 | Step: 550 | Avg. loss: 2.405 | lr: 0.0002538846222539739
Epoch: 3 | Step: 600 | Avg. loss: 2.508 | lr: 0.0002494195392034292
Epoch: 3 | Step: 650 | Avg. loss: 2.424 | lr: 0.0002449544561528844
Epoch: 3 | Step: 700 | Avg. loss: 2.450 | lr: 0.0002404893731023397
Epoch: 3 | Step: 750 | Avg. loss: 2.431 | lr: 0.00023602429005179496
Epoch: 3 | Step: 800 | Avg. loss: 2.452 | lr: 0.0002315592070012502
Epoch: 3 | Step: 850 | Avg. loss: 2.389 | lr: 0.0002270941239507055
Epoch: 3 | Step: 900 | Avg. loss: 2.424 | lr: 0.00022262904090016077
Epoch: 3 | Step: 950 | Avg. loss: 2.425 | lr: 0.000218163957849616
Epoch: 3 | Step: 1000 | Avg. loss: 2.444 | lr: 0.00021369887479907128
Saving model with test loss of 2.908
Epoch: 3 | Step: 1050 | Avg. loss: 2.395 | lr: 0.00020923379174852652
Epoch: 3 | Step: 1100 | Avg. loss: 2.441 | lr: 0.00020476870869798178
Epoch: 4 | Step: 50 | Avg. loss: 2.222 | lr: 0.0001975352741560993
Epoch: 4 | Step: 100 | Avg. loss: 2.216 | lr: 0.00019307019110555458
Epoch: 4 | Step: 150 | Avg. loss: 2.266 | lr: 0.00018860510805500982
Epoch: 4 | Step: 200 | Avg. loss: 2.276 | lr: 0.0001841400250044651
Epoch: 4 | Step: 250 | Avg. loss: 2.199 | lr: 0.00017967494195392033
Epoch: 4 | Step: 300 | Avg. loss: 2.262 | lr: 0.0001752098589033756
Epoch: 4 | Step: 350 | Avg. loss: 2.207 | lr: 0.00017074477585283086
Epoch: 4 | Step: 400 | Avg. loss: 2.209 | lr: 0.00016627969280228613
Epoch: 4 | Step: 450 | Avg. loss: 2.229 | lr: 0.0001618146097517414
Epoch: 4 | Step: 500 | Avg. loss: 2.220 | lr: 0.00015734952670119664
Epoch: 4 | Step: 550 | Avg. loss: 2.210 | lr: 0.0001528844436506519
Epoch: 4 | Step: 600 | Avg. loss: 2.267 | lr: 0.00014841936060010715
Epoch: 4 | Step: 650 | Avg. loss: 2.240 | lr: 0.00014395427754956242
Epoch: 4 | Step: 700 | Avg. loss: 2.178 | lr: 0.0001394891944990177
Epoch: 4 | Step: 750 | Avg. loss: 2.253 | lr: 0.00013502411144847295
Epoch: 4 | Step: 800 | Avg. loss: 2.292 | lr: 0.00013055902839792822
Epoch: 4 | Step: 850 | Avg. loss: 2.198 | lr: 0.00012609394534738346
Epoch: 4 | Step: 900 | Avg. loss: 2.272 | lr: 0.00012162886229683873
Epoch: 4 | Step: 950 | Avg. loss: 2.218 | lr: 0.00011716377924629399
Epoch: 4 | Step: 1000 | Avg. loss: 2.179 | lr: 0.00011269869619574924
Saving model with test loss of 2.972
Epoch: 4 | Step: 1050 | Avg. loss: 2.225 | lr: 0.00010823361314520451
Epoch: 4 | Step: 1100 | Avg. loss: 2.181 | lr: 0.00010376853009465976
Epoch: 5 | Step: 50 | Avg. loss: 2.059 | lr: 9.653509555277729e-05
Epoch: 5 | Step: 100 | Avg. loss: 2.038 | lr: 9.207001250223254e-05
Epoch: 5 | Step: 150 | Avg. loss: 2.040 | lr: 8.76049294516878e-05
Epoch: 5 | Step: 200 | Avg. loss: 2.016 | lr: 8.313984640114307e-05
Epoch: 5 | Step: 250 | Avg. loss: 1.998 | lr: 7.867476335059832e-05
Epoch: 5 | Step: 300 | Avg. loss: 2.020 | lr: 7.420968030005358e-05
Epoch: 5 | Step: 350 | Avg. loss: 2.082 | lr: 6.974459724950884e-05
Epoch: 5 | Step: 400 | Avg. loss: 1.987 | lr: 6.527951419896411e-05
Epoch: 5 | Step: 450 | Avg. loss: 2.088 | lr: 6.0814431148419366e-05
Epoch: 5 | Step: 500 | Avg. loss: 2.027 | lr: 5.634934809787462e-05
Epoch: 5 | Step: 550 | Avg. loss: 2.057 | lr: 5.188426504732988e-05
Epoch: 5 | Step: 600 | Avg. loss: 1.990 | lr: 4.7419181996785136e-05
Epoch: 5 | Step: 650 | Avg. loss: 2.036 | lr: 4.2954098946240404e-05
Epoch: 5 | Step: 700 | Avg. loss: 1.997 | lr: 3.848901589569566e-05
Epoch: 5 | Step: 750 | Avg. loss: 2.068 | lr: 3.402393284515092e-05
Epoch: 5 | Step: 800 | Avg. loss: 2.006 | lr: 2.955884979460618e-05
Epoch: 5 | Step: 850 | Avg. loss: 2.048 | lr: 2.5093766744061443e-05
Epoch: 5 | Step: 900 | Avg. loss: 2.070 | lr: 2.06286836935167e-05
Epoch: 5 | Step: 950 | Avg. loss: 1.994 | lr: 1.6163600642971962e-05
Epoch: 5 | Step: 1000 | Avg. loss: 2.039 | lr: 1.1698517592427218e-05
Saving model with test loss of 2.833
Epoch: 5 | Step: 1050 | Avg. loss: 2.031 | lr: 7.2334345418824795e-06
Epoch: 5 | Step: 1100 | Avg. loss: 2.074 | lr: 2.7683514913377387e-06
!date
Thu Jun 23 02:18:53 UTC 2022
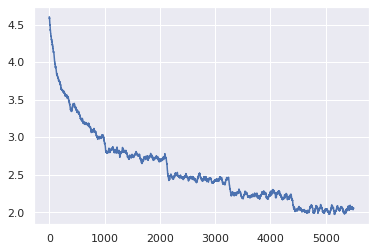
30.11. 学習中の損失推移#
# Graph the loss
window_size = 50
smoothed_losses = []
for i in range(len(losses)-window_size):
smoothed_losses.append(np.mean(losses[i:i+window_size]))
plt.plot(smoothed_losses[100:])
[<matplotlib.lines.Line2D at 0x7f83f5ae2f50>]
30.12. ファインチューニングしたモデルで翻訳してみる#
test_sentence = test_dataset[0]['translation']['en']
print('Raw input text:', test_sentence)
input_ids = encode_input_str(
text = test_sentence,
target_lang = 'ja',
tokenizer = tokenizer,
seq_len = model.config.max_length,
lang_token_map = LANG_TOKEN_MAPPING)
input_ids = input_ids.unsqueeze(0)
print('Truncated input text:', tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[0])))
Raw input text: It has been confirmed that eight thoroughbred race horses at Randwick Racecourse in Sydney have been infected with equine influenza.
Truncated input text: <jp> It has been confirmed that eight thoroughbred race horses at Randwick Racecourse</s>
output_tokens = model.generate(input_ids, num_beams=10, num_return_sequences=3)
# print(output_tokens)
for token_set in output_tokens:
print(tokenizer.decode(token_set, skip_special_tokens=True))
ニュージャージー州のRandwickRacecourseで8人の競輪のレース選手が
ニュージャージー州のRandwickRacecourseで8人の競輪のレース選手は
ニュージャージー州のRandwickRacecourseで8人の競輪の競輪の
30.13. Google Colab でフォームを用いた実行例#
#@title Slick Blue Translate
input_text = 'This is test' #@param {type:"string"}
output_language = 'ja' #@param ["en", "ja", "zh"]
input_ids = encode_input_str(
text = input_text,
target_lang = output_language,
tokenizer = tokenizer,
seq_len = model.config.max_length,
lang_token_map = LANG_TOKEN_MAPPING)
input_ids = input_ids.unsqueeze(0)
output_tokens = model.generate(input_ids, num_beams=20, length_penalty=0.2)
print(input_text + ' -> ' + \
tokenizer.decode(output_tokens[0], skip_special_tokens=True))
This is test -> これがテストの結果です。