!date
!python --version
Fri May 2 12:44:12 AM UTC 2025
Python 3.11.12
更新履歴
2025年5月1日
解説追加。
TrainingArguments
evaluation_strategyをeval_strategyに変更。
report_to="none"を追加。(デフォルトだとwandbを使うため、APIキー入力待ちになってしまう)
39. AutoModelForSequenceClassificationを用いたファインチューニング例#
このノートブックではJapanese Realistic Textual Entailment Corpusのpn.tsvをデータセットとし、BERT(”tohoku-nlp/bert-base-japanese-v3”)を用いてファインチューニングする例を示している。
pn.tsvは実際のレビュー文に対して5名の被験者が極性ラベルを付与したデータセットである。上記サイトのデータ説明にあるとおり、ID, Label, Text, Judges, Usage の5列のデータがサンプル毎に用意されている。
ID: ユニークなID
Label: 1 (Positive), 0 (Neutral), -1 (Negative)
Text: レビュー文そのもの
Judges: JSONフォーマットによる極性判定結果。例:
{"0": 1, "1": 4}Usage: train, deve, testの種別。
全体の流れは以下の通り。
環境構築: fugashi, accelerateをインストール
モジュール読み込み
データ前処理: LLMにおける分類タスクでは教師ラベルを「0から始まる整数」として割り振る必要があるため、ラベルを設定し直した。
モデルの用意: tokenizerの動作確認を含む。
LLM用にデータを整形: tokenizerの出力と教師ラベルを合わせてDataset型に変換。
学習
テストデータに対する詳細結果
学習データに対する詳細結果
!curl -O https://raw.githubusercontent.com/megagonlabs/jrte-corpus/refs/heads/master/data/pn.tsv
!head pn.tsv
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 473k 100 473k 0 0 1275k 0 --:--:-- --:--:-- --:--:-- 1275k
pn17q00001 0 出張でお世話になりました。 {"0": 3} test
pn17q00002 0 朝食は普通でした。 {"0": 3} test
pn17q00003 1 また是非行きたいです。 {"1": 3} test
pn17q00004 1 また利用したいと思えるホテルでした。 {"1": 3} test
pn17q00005 1 駅から近くて便利でした。 {"0": 1, "1": 2} test
pn17q00006 1 また来年も利用したいと思います。 {"0": 1, "1": 2} test
pn17q00007 0 新婚旅行で利用しました。 {"0": 3} test
pn17q00008 1 また利用いたします。 {"0": 1, "1": 2} test
pn17q00009 1 コストパフォーマンス最高です。 {"1": 3} test
pn17q00010 0 お心遣いありがとうございました。 {"0": 2, "1": 1} test
39.1. 注意#
39.1.1. GPUを指定する#
LLMを用いた学習を行っている都合上、デフォルト(CPU)実行すると極めて時間がかかる。おそらく数時間要するだろう。自身でも動作確認したい人は、GPUを指定して実行することをお勧めする。
GPUを指定するには以下の手順を取る。
「ランタイム」から「ランタイムのタイプの変更」を選ぶ。
「ハードウェア アクセラレータ」からGPUを選ぶ。
T4 GPU を選ぶと良い。この中では低スペックだが十分早い。T4 GPUなら、10エポックの学習が約14分で終了する。
39.1.2. リソース使用制限#
Google Colabは無料で利用できるが、利用度合いに応じてリソースが制限されることがある。特にGPUは使えなくなることが多いため、不必要に何度も実行することは避けよう。
39.1.3. 必要に応じてモデルや結果をファイル保存する#
このノートブックではノートブック内に出力しつつ、学習したモデルはセッション内に保存しているだけで終えている。このため後日「学習結果を利用したい」場合には改めて学習し直す必要がある。それが面倒に思う人はファイル保存するようにしよう。
なお、正確には「ファイル」ではなく「複数のファイルを含むフォルダ」として保存されている。このフォルダ単位でダウンロードしたり、アップロードしてモデルを復元する必要があることに注意しよう。
またモデルはとてもファイルサイズが大きく、実際にダウンロード&アップロードするにはとても時間がかかる。そのためGoogleドライブにアクセス許可した上で自身のドライブ内に保存する方が楽だ。
# ノートブックからドライブへのアクセスを許可する
from google.colab import drive
drive.mount('/content/drive')
39.2. 環境構築#
!pip install fugashi[unidic-lite]
!pip install accelerate -U
Collecting fugashi[unidic-lite]
Downloading fugashi-1.4.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (6.9 kB)
Collecting unidic-lite (from fugashi[unidic-lite])
Downloading unidic-lite-1.0.8.tar.gz (47.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 47.4/47.4 MB 20.3 MB/s eta 0:00:00
?25h Preparing metadata (setup.py) ... ?25l?25hdone
Downloading fugashi-1.4.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (698 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 698.0/698.0 kB 5.4 MB/s eta 0:00:00
?25hBuilding wheels for collected packages: unidic-lite
Building wheel for unidic-lite (setup.py) ... ?25l?25hdone
Created wheel for unidic-lite: filename=unidic_lite-1.0.8-py3-none-any.whl size=47658817 sha256=dbcb89f589c4f364e62826e9552de412a0e688f737d11c42dde9f26283941cb3
Stored in directory: /root/.cache/pip/wheels/b7/fd/e9/ea4459b868e6d2902e8d80e82dbacb6203e05b3b3a58c64966
Successfully built unidic-lite
Installing collected packages: unidic-lite, fugashi
Successfully installed fugashi-1.4.0 unidic-lite-1.0.8
Requirement already satisfied: accelerate in /usr/local/lib/python3.11/dist-packages (1.6.0)
Requirement already satisfied: numpy<3.0.0,>=1.17 in /usr/local/lib/python3.11/dist-packages (from accelerate) (2.0.2)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.11/dist-packages (from accelerate) (24.2)
Requirement already satisfied: psutil in /usr/local/lib/python3.11/dist-packages (from accelerate) (5.9.5)
Requirement already satisfied: pyyaml in /usr/local/lib/python3.11/dist-packages (from accelerate) (6.0.2)
Requirement already satisfied: torch>=2.0.0 in /usr/local/lib/python3.11/dist-packages (from accelerate) (2.6.0+cu124)
Requirement already satisfied: huggingface-hub>=0.21.0 in /usr/local/lib/python3.11/dist-packages (from accelerate) (0.30.2)
Requirement already satisfied: safetensors>=0.4.3 in /usr/local/lib/python3.11/dist-packages (from accelerate) (0.5.3)
Requirement already satisfied: filelock in /usr/local/lib/python3.11/dist-packages (from huggingface-hub>=0.21.0->accelerate) (3.18.0)
Requirement already satisfied: fsspec>=2023.5.0 in /usr/local/lib/python3.11/dist-packages (from huggingface-hub>=0.21.0->accelerate) (2025.3.2)
Requirement already satisfied: requests in /usr/local/lib/python3.11/dist-packages (from huggingface-hub>=0.21.0->accelerate) (2.32.3)
Requirement already satisfied: tqdm>=4.42.1 in /usr/local/lib/python3.11/dist-packages (from huggingface-hub>=0.21.0->accelerate) (4.67.1)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.11/dist-packages (from huggingface-hub>=0.21.0->accelerate) (4.13.2)
Requirement already satisfied: networkx in /usr/local/lib/python3.11/dist-packages (from torch>=2.0.0->accelerate) (3.4.2)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.11/dist-packages (from torch>=2.0.0->accelerate) (3.1.6)
Collecting nvidia-cuda-nvrtc-cu12==12.4.127 (from torch>=2.0.0->accelerate)
Downloading nvidia_cuda_nvrtc_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB)
Collecting nvidia-cuda-runtime-cu12==12.4.127 (from torch>=2.0.0->accelerate)
Downloading nvidia_cuda_runtime_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB)
Collecting nvidia-cuda-cupti-cu12==12.4.127 (from torch>=2.0.0->accelerate)
Downloading nvidia_cuda_cupti_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB)
Collecting nvidia-cudnn-cu12==9.1.0.70 (from torch>=2.0.0->accelerate)
Downloading nvidia_cudnn_cu12-9.1.0.70-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB)
Collecting nvidia-cublas-cu12==12.4.5.8 (from torch>=2.0.0->accelerate)
Downloading nvidia_cublas_cu12-12.4.5.8-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB)
Collecting nvidia-cufft-cu12==11.2.1.3 (from torch>=2.0.0->accelerate)
Downloading nvidia_cufft_cu12-11.2.1.3-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB)
Collecting nvidia-curand-cu12==10.3.5.147 (from torch>=2.0.0->accelerate)
Downloading nvidia_curand_cu12-10.3.5.147-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB)
Collecting nvidia-cusolver-cu12==11.6.1.9 (from torch>=2.0.0->accelerate)
Downloading nvidia_cusolver_cu12-11.6.1.9-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB)
Collecting nvidia-cusparse-cu12==12.3.1.170 (from torch>=2.0.0->accelerate)
Downloading nvidia_cusparse_cu12-12.3.1.170-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB)
Requirement already satisfied: nvidia-cusparselt-cu12==0.6.2 in /usr/local/lib/python3.11/dist-packages (from torch>=2.0.0->accelerate) (0.6.2)
Requirement already satisfied: nvidia-nccl-cu12==2.21.5 in /usr/local/lib/python3.11/dist-packages (from torch>=2.0.0->accelerate) (2.21.5)
Requirement already satisfied: nvidia-nvtx-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=2.0.0->accelerate) (12.4.127)
Collecting nvidia-nvjitlink-cu12==12.4.127 (from torch>=2.0.0->accelerate)
Downloading nvidia_nvjitlink_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB)
Requirement already satisfied: triton==3.2.0 in /usr/local/lib/python3.11/dist-packages (from torch>=2.0.0->accelerate) (3.2.0)
Requirement already satisfied: sympy==1.13.1 in /usr/local/lib/python3.11/dist-packages (from torch>=2.0.0->accelerate) (1.13.1)
Requirement already satisfied: mpmath<1.4,>=1.1.0 in /usr/local/lib/python3.11/dist-packages (from sympy==1.13.1->torch>=2.0.0->accelerate) (1.3.0)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.11/dist-packages (from jinja2->torch>=2.0.0->accelerate) (3.0.2)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.11/dist-packages (from requests->huggingface-hub>=0.21.0->accelerate) (3.4.1)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.11/dist-packages (from requests->huggingface-hub>=0.21.0->accelerate) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.11/dist-packages (from requests->huggingface-hub>=0.21.0->accelerate) (2.4.0)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.11/dist-packages (from requests->huggingface-hub>=0.21.0->accelerate) (2025.4.26)
Downloading nvidia_cublas_cu12-12.4.5.8-py3-none-manylinux2014_x86_64.whl (363.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 363.4/363.4 MB 4.0 MB/s eta 0:00:00
?25hDownloading nvidia_cuda_cupti_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl (13.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.8/13.8 MB 116.3 MB/s eta 0:00:00
?25hDownloading nvidia_cuda_nvrtc_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl (24.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24.6/24.6 MB 95.2 MB/s eta 0:00:00
?25hDownloading nvidia_cuda_runtime_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl (883 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 883.7/883.7 kB 56.9 MB/s eta 0:00:00
?25hDownloading nvidia_cudnn_cu12-9.1.0.70-py3-none-manylinux2014_x86_64.whl (664.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 664.8/664.8 MB 2.8 MB/s eta 0:00:00
?25hDownloading nvidia_cufft_cu12-11.2.1.3-py3-none-manylinux2014_x86_64.whl (211.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 211.5/211.5 MB 5.5 MB/s eta 0:00:00
?25hDownloading nvidia_curand_cu12-10.3.5.147-py3-none-manylinux2014_x86_64.whl (56.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 56.3/56.3 MB 13.2 MB/s eta 0:00:00
?25hDownloading nvidia_cusolver_cu12-11.6.1.9-py3-none-manylinux2014_x86_64.whl (127.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 127.9/127.9 MB 7.9 MB/s eta 0:00:00
?25hDownloading nvidia_cusparse_cu12-12.3.1.170-py3-none-manylinux2014_x86_64.whl (207.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 207.5/207.5 MB 5.9 MB/s eta 0:00:00
?25hDownloading nvidia_nvjitlink_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl (21.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 21.1/21.1 MB 86.5 MB/s eta 0:00:00
?25hInstalling collected packages: nvidia-nvjitlink-cu12, nvidia-curand-cu12, nvidia-cufft-cu12, nvidia-cuda-runtime-cu12, nvidia-cuda-nvrtc-cu12, nvidia-cuda-cupti-cu12, nvidia-cublas-cu12, nvidia-cusparse-cu12, nvidia-cudnn-cu12, nvidia-cusolver-cu12
Attempting uninstall: nvidia-nvjitlink-cu12
Found existing installation: nvidia-nvjitlink-cu12 12.5.82
Uninstalling nvidia-nvjitlink-cu12-12.5.82:
Successfully uninstalled nvidia-nvjitlink-cu12-12.5.82
Attempting uninstall: nvidia-curand-cu12
Found existing installation: nvidia-curand-cu12 10.3.6.82
Uninstalling nvidia-curand-cu12-10.3.6.82:
Successfully uninstalled nvidia-curand-cu12-10.3.6.82
Attempting uninstall: nvidia-cufft-cu12
Found existing installation: nvidia-cufft-cu12 11.2.3.61
Uninstalling nvidia-cufft-cu12-11.2.3.61:
Successfully uninstalled nvidia-cufft-cu12-11.2.3.61
Attempting uninstall: nvidia-cuda-runtime-cu12
Found existing installation: nvidia-cuda-runtime-cu12 12.5.82
Uninstalling nvidia-cuda-runtime-cu12-12.5.82:
Successfully uninstalled nvidia-cuda-runtime-cu12-12.5.82
Attempting uninstall: nvidia-cuda-nvrtc-cu12
Found existing installation: nvidia-cuda-nvrtc-cu12 12.5.82
Uninstalling nvidia-cuda-nvrtc-cu12-12.5.82:
Successfully uninstalled nvidia-cuda-nvrtc-cu12-12.5.82
Attempting uninstall: nvidia-cuda-cupti-cu12
Found existing installation: nvidia-cuda-cupti-cu12 12.5.82
Uninstalling nvidia-cuda-cupti-cu12-12.5.82:
Successfully uninstalled nvidia-cuda-cupti-cu12-12.5.82
Attempting uninstall: nvidia-cublas-cu12
Found existing installation: nvidia-cublas-cu12 12.5.3.2
Uninstalling nvidia-cublas-cu12-12.5.3.2:
Successfully uninstalled nvidia-cublas-cu12-12.5.3.2
Attempting uninstall: nvidia-cusparse-cu12
Found existing installation: nvidia-cusparse-cu12 12.5.1.3
Uninstalling nvidia-cusparse-cu12-12.5.1.3:
Successfully uninstalled nvidia-cusparse-cu12-12.5.1.3
Attempting uninstall: nvidia-cudnn-cu12
Found existing installation: nvidia-cudnn-cu12 9.3.0.75
Uninstalling nvidia-cudnn-cu12-9.3.0.75:
Successfully uninstalled nvidia-cudnn-cu12-9.3.0.75
Attempting uninstall: nvidia-cusolver-cu12
Found existing installation: nvidia-cusolver-cu12 11.6.3.83
Uninstalling nvidia-cusolver-cu12-11.6.3.83:
Successfully uninstalled nvidia-cusolver-cu12-11.6.3.83
Successfully installed nvidia-cublas-cu12-12.4.5.8 nvidia-cuda-cupti-cu12-12.4.127 nvidia-cuda-nvrtc-cu12-12.4.127 nvidia-cuda-runtime-cu12-12.4.127 nvidia-cudnn-cu12-9.1.0.70 nvidia-cufft-cu12-11.2.1.3 nvidia-curand-cu12-10.3.5.147 nvidia-cusolver-cu12-11.6.1.9 nvidia-cusparse-cu12-12.3.1.170 nvidia-nvjitlink-cu12-12.4.127
39.3. モジュール読み込み、データ前処理#
元データでは極性が -1, 0, 1 で付与されている。しかし教師ラベルとしては0から始まる整数で設定する必要がある。そのためここでは read_csv() で読み込んだ後、map関数により -1を0に、0を1に、1を2に置換している。
import torch
import pandas as pd
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
import numpy as np
# データの読み込み
filename = "pn.tsv"
columns = ["id", "sentiment", "text", "judges-json", "usage"]
df = pd.read_csv(filename, sep="\t", names=columns)
df.head()
| id | sentiment | text | judges-json | usage | |
|---|---|---|---|---|---|
| 0 | pn17q00001 | 0 | 出張でお世話になりました。 | {"0": 3} | test |
| 1 | pn17q00002 | 0 | 朝食は普通でした。 | {"0": 3} | test |
| 2 | pn17q00003 | 1 | また是非行きたいです。 | {"1": 3} | test |
| 3 | pn17q00004 | 1 | また利用したいと思えるホテルでした。 | {"1": 3} | test |
| 4 | pn17q00005 | 1 | 駅から近くて便利でした。 | {"0": 1, "1": 2} | test |
# ラベルの付け替え
# AutoModelForSequenceClassificationではラベルは「0から始まる整数」である必要がある。
# このため -1, 0, 1 => 0, 1, 2(ネガティブ0、ノーマル1、ポジティブ2)に付け替える。
df['sentiment'] = df['sentiment'].map({-1: 0, 0: 1, 1: 2})
df.head()
| id | sentiment | text | judges-json | usage | |
|---|---|---|---|---|---|
| 0 | pn17q00001 | 1 | 出張でお世話になりました。 | {"0": 3} | test |
| 1 | pn17q00002 | 1 | 朝食は普通でした。 | {"0": 3} | test |
| 2 | pn17q00003 | 2 | また是非行きたいです。 | {"1": 3} | test |
| 3 | pn17q00004 | 2 | また利用したいと思えるホテルでした。 | {"1": 3} | test |
| 4 | pn17q00005 | 2 | 駅から近くて便利でした。 | {"0": 1, "1": 2} | test |
# データセットの分割
train_texts = df[df["usage"] == "train"]["text"].tolist()
train_labels = df[df["usage"] == "train"]["sentiment"].tolist()
dev_texts = df[df["usage"] == "dev"]["text"].tolist()
dev_labels = df[df["usage"] == "dev"]["sentiment"].tolist()
test_texts = df[df["usage"] == "test"]["text"].tolist()
test_labels = df[df["usage"] == "test"]["sentiment"].tolist()
# 動作確認
print(f"{train_texts[0]=}")
print(f"{train_labels[0]=}")
print(df['sentiment'].value_counts())
train_texts[0]='(笑)'
train_labels[0]=1
sentiment
2 3406
1 1329
0 818
Name: count, dtype: int64
39.4. モデルの用意#
ここでは “tohoku-nlp/bert-base-japanese-v3” を利用。
長文だが、最初の出力「
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at tohoku-nlp/bert-base-japanese-v3 and are newly initialized: ['classifier.bias', 'classifier.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.」は、このままでは利用できない(ので学習が必要だろう)ということを指摘している。この理由は、AutoModelForSequenceClassificationが「LLMの最後尾に新たな線形層(torch.nn.Linear)を追加しているためだ。この線形層はクラス数と同数のユニットを持つように設定されており(引数num_labelsで設定)、各ユニットに対するスコアを求めるようにモデルを拡張している。このようなにモデルを拡張しているということは、拡張した部分(Linear層のパラメータ)については重みがまっさらな状態である。このままでは当然推定できない(でたらめになる)ため、「You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.」と注意を促している。
# ハイパーパラメータ
num_labels = 3 # クラス数
max_length = 128 # 最長系列長(最大トークン数)
num_train_epochs = 10 # 最大学習エポック数
output_dir = './results' # チェックポイント等を保存するディレクトリ
batch_size = 16 # バッチサイズ(一度に処理するサンプル数)
logging_dir = './logs' # ログ出力用のディレクトリ(主にエラー確認用)
# トークナイザーとモデルの準備
model_name = "tohoku-nlp/bert-base-japanese-v3"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=num_labels)
# データセットのトークナイズ
train_encodings = tokenizer(train_texts, truncation=True, padding=True, max_length=max_length)
dev_encodings = tokenizer(dev_texts, truncation=True, padding=True, max_length=max_length)
test_encodings = tokenizer(test_texts, truncation=True, padding=True, max_length=max_length)
# 動作確認
# 'input_ids', 'token_type_ids', 'attention_mask'をキーとするリストとして保存されている。
# ['input_ids'][0] は、0番目のみを出力指定。
print(train_encodings.keys())
print(train_encodings['input_ids'][0]) # サンプル0番目
print(train_encodings['attention_mask'][0])
/usr/local/lib/python3.11/dist-packages/huggingface_hub/utils/_auth.py:94: UserWarning:
The secret `HF_TOKEN` does not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at tohoku-nlp/bert-base-japanese-v3 and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])
[2, 23, 4374, 24, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# input_ids をデコードして元の文章を確認
tokenizer.decode([2, 23, 4374, 24, 3])
'[CLS] ( 笑 ) [SEP]'
39.5. LLM用にデータを整形#
今回は分類タスクとして学習させたい。しかしtokenizerではテキストに対する前処理しか行われておらず、教師ラベルは別に用意している。これらを使いやすい形(Dataset型)にまとめ直している。
print文では、Dataset型の例としてtrain_dataset[0]を出力している。
トークン系列分用意するデータ(同じ長さで揃える必要がある)
input_ids: 入力文をトークナイズした結果(トークンのID列)。tokey_type_ids: BERT系では2文の対で用意することを前提としている。その2文を区別するためのフィルタ設定。単一文の場合は全て0(今回はこれ)。2文ある場合、文2のトークンは1になる。attention_mask: 一般的には「どのトークンに注意を向けるか」を0(無視する),1(注意を向ける)で設定している。ここでは実トークンがある部分を1に、パディングで意味の無い部分を0として設定している。
教師データ
labels: Trainerと連動した設定。train_dataset=train_datasetと設定していると、train_dataset内の”labels”を自動で参照し、損失を計算するようになっている。違う名目でラベルを設定したい場合には DataCollatorもしくはTrainerをカスタマイズする必要があります。
class SentimentDataset(torch.utils.data.Dataset):
'''サンプル毎に input_ids, token_type_ids, attention_mask, labels を設定。
'''
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = SentimentDataset(train_encodings, train_labels)
dev_dataset = SentimentDataset(dev_encodings, dev_labels)
test_dataset = SentimentDataset(test_encodings, test_labels)
# 動作確認
# サンプル毎に input_ids, token_type_ids, attention_mask, labels を用意した
print(train_dataset[0])
{'input_ids': tensor([ 2, 23, 4374, 24, 3, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]), 'token_type_ids': tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]), 'attention_mask': tensor([1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]), 'labels': tensor(1)}
39.6. 学習#
エポック毎に出力しているログは、学習データに対する損失(training loss)、検証データに対する損失(validation loss)、正解率(accuracy)、F1スコア(F1)、適合率(precision)、再現率(recall)。
ログを確認すると、基本的には学習データに対する損失は減り続けている。しかし検証データに対する損失は途中から「逆に増えている」ことを確認できる。これが過学習(過剰適合; over-fitting)だ。ここでは特別なことはせずに指定したエポック数の学習を続け、最終モデルを用いた検証を行うこととした。
TrainingArgumentsで用いているパラメータ
TrainingArgumentsの補足
設定可能な項目多数のため、詳細はhuggingfaceの公式ドキュメント推奨。ここでは利用したパラメータだけ説明する。
output_dir: チェックポイント(学習済みモデル)やログを保存する出力先ディレクトリを指定。チェックポイントとは、別のパラメータ「save_strategy = “epoch”」として指定したタイミングのモデルのこと。今回はepochと指定しているため1エポック毎にモデルが保存されている。
必要に応じてこれらのチェックポイントからモデルを復元することも可能。モデル読み込み時にファイルを指定するだけで良い。このためファインチューニングしたモデルをファイル保存しておきたいならば、resultsフォルダ内のチェックポイントを保存しておくか、最終モデルである sentiment_model を保存しておくと良いだろう。
ダウンロードするというよりは、Googleドライブへのアクセス許可を与え、自身のドライブ内に保存する方が良いだろう。
num_train_epochs: 学習を繰り返すエポック数。1エポックは全データを1周すること。per_device_train_batch_size: 学習時に1デバイス(GPU/CPU)あたりで処理するバッチサイズ。per_device_eval_batch_size: 評価時のバッチサイズ。warmup_steps: 指定した初期ステップ数(〜500ステップまで)は学習率を徐々に増やす。デフォルトでは0から指定した学習率まで線形単調増加。weight_decay: L2正則化による過学習抑制のための調整項。logging_dir: TensorBoard用ログの出力先。logging_steps: 指定ステップ毎に損失などのログを記録。eval_strategy: 評価を行うタイミング(今回は1エポック終了毎)。save_strategy: モデル保存タイミング。report_to: 学習をどこに送るか。今回は外部ログ連携無し。
# トレーニングの設定
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
warmup_steps=500,
weight_decay=0.01,
logging_dir=logging_dir,
logging_steps=10,
eval_strategy="epoch",
save_strategy="epoch",
report_to="none" # wandbを使わない
)
# 精度の計算
def compute_metrics(p):
pred, labels = p
pred = np.argmax(pred, axis=1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, pred, average='macro')
acc = accuracy_score(labels, pred)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
# トレーナーの設定
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=dev_dataset,
compute_metrics=compute_metrics
)
# モデルのトレーニング
trainer.train()
# モデルの保存
trainer.save_model("./sentiment_model")
# テストセットでの評価
results = trainer.evaluate(eval_dataset=test_dataset)
# 結果の表示
print(f"Test Accuracy: {results['eval_accuracy']}")
print(f"Test F1 Score: {results['eval_f1']}")
print(f"Test Precision: {results['eval_precision']}")
print(f"Test Recall: {results['eval_recall']}")
| Epoch | Training Loss | Validation Loss | Accuracy | F1 | Precision | Recall |
|---|---|---|---|---|---|---|
| 1 | 0.404300 | 0.408381 | 0.847122 | 0.792012 | 0.821642 | 0.776139 |
| 2 | 0.290400 | 0.370082 | 0.859712 | 0.815932 | 0.820656 | 0.811538 |
| 3 | 0.196200 | 0.432191 | 0.877698 | 0.838691 | 0.845239 | 0.837207 |
| 4 | 0.151200 | 0.478974 | 0.884892 | 0.844025 | 0.846112 | 0.845028 |
| 5 | 0.079300 | 0.555178 | 0.871403 | 0.831201 | 0.832901 | 0.829776 |
| 6 | 0.052700 | 0.722724 | 0.863309 | 0.824431 | 0.823894 | 0.826944 |
| 7 | 0.001300 | 0.758387 | 0.875000 | 0.831257 | 0.835224 | 0.829333 |
| 8 | 0.023000 | 0.835225 | 0.875899 | 0.828396 | 0.838685 | 0.821027 |
| 9 | 0.000300 | 0.864122 | 0.875899 | 0.831851 | 0.837495 | 0.826545 |
| 10 | 0.000600 | 0.866264 | 0.875899 | 0.831269 | 0.838046 | 0.824955 |
Test Accuracy: 0.8553345388788427
Test F1 Score: 0.8221032582050153
Test Precision: 0.8452179386146287
Test Recall: 0.8034550381672684
39.7. テストデータに対する詳細結果#
# テストデータに対する詳細結果
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
#import numpy as np
predictions, labels, _ = trainer.predict(test_dataset)
predicted_labels = np.argmax(predictions, axis=1)
labels = ['negative', 'normal', 'positive']
# 分類レポートの表示
print(classification_report(test_labels, predicted_labels, target_names=labels))
precision recall f1-score support
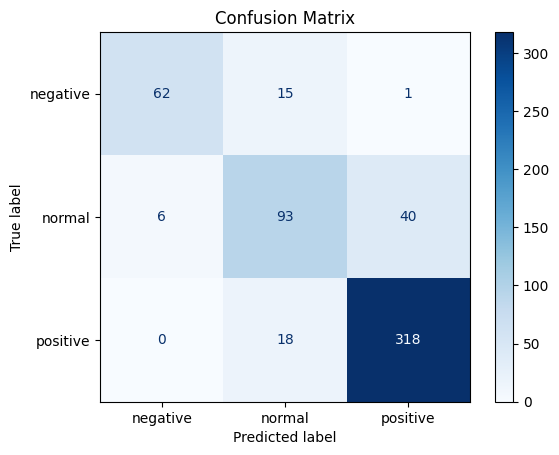
negative 0.91 0.79 0.85 78
normal 0.74 0.67 0.70 139
positive 0.89 0.95 0.92 336
accuracy 0.86 553
macro avg 0.85 0.80 0.82 553
weighted avg 0.85 0.86 0.85 553
# 混同行列の表示
conf_matrix = confusion_matrix(test_labels, predicted_labels)
disp = ConfusionMatrixDisplay(confusion_matrix=conf_matrix, display_labels=labels)
disp.plot(cmap='Blues')
disp.ax_.set_title('Confusion Matrix')
Text(0.5, 1.0, 'Confusion Matrix')
39.8. 具体的な失敗例#
ラベルは「ネガティブ0、ノーマル1、ポジティブ2」に付け直していることに注意。
39.8.1. 学習データに対する誤り#
以下の通り1件しか誤りがない。学習データに対しては極めて的鉄な予測が可能なモデルになっているようだ。
# 学習データに対する予測誤り
predictions, labels, _ = trainer.predict(train_dataset)
predicted_labels = np.argmax(predictions, axis=1)
# 誤った予測のサンプルを抽出
incorrect_indices = [i for i, (true, pred) in enumerate(zip(train_labels, predicted_labels)) if true != pred]
# 誤った予測のサンプルを出力
for i in incorrect_indices:
print(f"正解ラベル: {train_labels[i]}, 予測ラベル: {predicted_labels[i]}, テキスト: {train_texts[i]}")
正解ラベル: 2, 予測ラベル: 1, テキスト: 家族旅行で利用させていただきました。
正解ラベル: 2, 予測ラベル: 1, テキスト: 東京出張時に利用しました。
39.8.2. テストデータに対する誤り#
テストデータのサンプル数は学習データより少ないにも関わらず、失敗事例数は多い。
# テストデータに対する予測誤り
predictions, labels, _ = trainer.predict(test_dataset)
predicted_labels = np.argmax(predictions, axis=1)
# 誤った予測のサンプルを抽出
incorrect_indices = [i for i, (true, pred) in enumerate(zip(test_labels, predicted_labels)) if true != pred]
# 誤った予測のサンプルを出力
for i in incorrect_indices:
print(f"正解ラベル: {test_labels[i]}, 予測ラベル: {predicted_labels[i]}, テキスト: {test_texts[i]}")
正解ラベル: 1, 予測ラベル: 2, テキスト: お心遣いありがとうございました。
正解ラベル: 0, 予測ラベル: 1, テキスト: と感じてしまいました。
正解ラベル: 2, 予測ラベル: 1, テキスト: 再訪です。
正解ラベル: 2, 予測ラベル: 1, テキスト: 二度目です。
正解ラベル: 1, 予測ラベル: 2, テキスト: お疲れ様です。
正解ラベル: 1, 予測ラベル: 2, テキスト: (^ω^
正解ラベル: 1, 予測ラベル: 2, テキスト: 対応ありがとうございました。
正解ラベル: 2, 予測ラベル: 1, テキスト: 加湿器もありました。
正解ラベル: 1, 予測ラベル: 2, テキスト: コンビニも近かったです。
正解ラベル: 1, 予測ラベル: 2, テキスト: 長々と失礼しました。
正解ラベル: 2, 予測ラベル: 1, テキスト: 定宿にします。
正解ラベル: 0, 予測ラベル: 1, テキスト: 朝食は食べませんでした。
正解ラベル: 1, 予測ラベル: 2, テキスト: 良かった所。
正解ラベル: 1, 予測ラベル: 2, テキスト: お待ちしておりました。
正解ラベル: 1, 予測ラベル: 2, テキスト: 思わず笑ってしまいました。
正解ラベル: 1, 予測ラベル: 2, テキスト: 大人の宿です。
正解ラベル: 2, 予測ラベル: 1, テキスト: 間違いないホテルです。
正解ラベル: 2, 予測ラベル: 1, テキスト: 迷わず予約しました。
正解ラベル: 1, 予測ラベル: 2, テキスト: 足湯もありました。
正解ラベル: 0, 予測ラベル: 1, テキスト: おかしいです。
正解ラベル: 1, 予測ラベル: 2, テキスト: 料理は期待通りでした。
正解ラベル: 1, 予測ラベル: 0, テキスト: 好みの問題ですが。
正解ラベル: 1, 予測ラベル: 0, テキスト: リゾートホテルではありません。
正解ラベル: 1, 予測ラベル: 2, テキスト: また機会があれば...。
正解ラベル: 1, 予測ラベル: 2, テキスト: 朝食付きをお勧めします。
正解ラベル: 2, 予測ラベル: 1, テキスト: そんなに気になりませんでした。
正解ラベル: 2, 予測ラベル: 1, テキスト: 立地は問題なしです。
正解ラベル: 0, 予測ラベル: 1, テキスト: 食べたかったなぁ。
正解ラベル: 0, 予測ラベル: 1, テキスト: 天気は雨。
正解ラベル: 1, 予測ラベル: 2, テキスト: 安ければまた利用します。
正解ラベル: 1, 予測ラベル: 2, テキスト: はあったものの美味しく頂きました。
正解ラベル: 1, 予測ラベル: 2, テキスト: 泊まる分には問題ありません。
正解ラベル: 2, 予測ラベル: 1, テキスト: マンションのようなホテルでした。
正解ラベル: 0, 予測ラベル: 1, テキスト: 理解できません。
正解ラベル: 1, 予測ラベル: 2, テキスト: 餅っ!
正解ラベル: 1, 予測ラベル: 2, テキスト: とにかくすごい!
正解ラベル: 1, 予測ラベル: 2, テキスト: 出張で利用させてもらっています。
正解ラベル: 1, 予測ラベル: 2, テキスト: お風呂とトイレは別。
正解ラベル: 1, 予測ラベル: 0, テキスト: がゴロゴロ。
正解ラベル: 1, 予測ラベル: 2, テキスト: 風呂は温泉です。
正解ラベル: 2, 予測ラベル: 1, テキスト: 一人旅で利用いたしました。
正解ラベル: 1, 予測ラベル: 2, テキスト: それ以外は◎。
正解ラベル: 0, 予測ラベル: 1, テキスト: 午後9時すぎから朝8時までなので1000円くらいだといいですね。
正解ラベル: 2, 予測ラベル: 1, テキスト: 女性専用ルームだったので、アメニティーやナノスチーマーやフットマッサージまで。
正解ラベル: 0, 予測ラベル: 1, テキスト: 時間で管理してるなら案内出して欲しいです。
正解ラベル: 2, 予測ラベル: 1, テキスト: 朝食は、お粥とチーズオムレツをお願いし、サラダに、ヨーグルトとフルーツ三昧。
正解ラベル: 1, 予測ラベル: 2, テキスト: 他にいいところが空いていればそっちを選択するかもですね。
正解ラベル: 1, 予測ラベル: 0, テキスト: ただ朝のバイキングで席を指定され並んでいた所、私達の席を隣のテーブルとくっつけていて、家族連れが座りました。
正解ラベル: 1, 予測ラベル: 2, テキスト: そこがチョット残念な思いをしただけで他の食事、お風呂などは大変満足させていただきました。
正解ラベル: 1, 予測ラベル: 2, テキスト: 料理もおいしかったし,お風呂の洗面付近の清潔感は素晴らしかったので,期待していかなければそれなりに満足できたのかもしれません。
正解ラベル: 1, 予測ラベル: 0, テキスト: この金額でシャワーが赤青の蛇口じゃないところは初めてかも。
正解ラベル: 0, 予測ラベル: 1, テキスト: チェックアウト12時のプランでしたが、10時までの料金をホテルで支払い、その後は精算機でとのことでした。
正解ラベル: 0, 予測ラベル: 1, テキスト: 4ヵ月の子どもと一緒の旅行だったので、部屋食にしたが、全体的に同じような味付けで、これ!
正解ラベル: 0, 予測ラベル: 1, テキスト: まだ使ってない洗面所で、気になりました。
正解ラベル: 1, 予測ラベル: 0, テキスト: 8時過ぎになると人が少なってきます。
正解ラベル: 1, 予測ラベル: 2, テキスト: フロントの方たちの笑顔があれば、90点なのですが、85点の満足の宿でした。
正解ラベル: 1, 予測ラベル: 2, テキスト: 部屋は4人部屋で大変広く、7人で2次会が出来ました、アジアンリゾート風ですね・・良かったですその他テニスやパターゴルフ、散策、夏はプールなどがあり宿泊者が楽しめる配慮が随所にありますが、子供いわくゲーセンは信じられない位しょぼい(笑)
正解ラベル: 0, 予測ラベル: 1, テキスト: 夜フルーツが無いのと、朝お粥が有れば年配の方は喜ぶと思います。
正解ラベル: 0, 予測ラベル: 1, テキスト: フロントも全く同じで何コールしてもでない。
正解ラベル: 1, 予測ラベル: 2, テキスト: 朝食のメニューも変わっていて前からあった和食・洋食にエビチーズドリアセット・ロコモコ丼セットの4種類になっていました。
正解ラベル: 1, 予測ラベル: 2, テキスト: 大浴場が利用できたのが、ここに決めたポイントです。
正解ラベル: 0, 予測ラベル: 2, テキスト: 身体の大きい人は大変そう。
正解ラベル: 1, 予測ラベル: 2, テキスト: 他はパーフェクトです。
正解ラベル: 2, 予測ラベル: 1, テキスト: ほとんど寝るだけだったので、特に不便はありませんでした。
正解ラベル: 1, 予測ラベル: 2, テキスト: この宿に泊まって一番感じる事は、御主人、女将さんの人柄です。
正解ラベル: 2, 予測ラベル: 1, テキスト: 120センチのセミダブルでしたので、夫とふたりでもこれならOKと思いました。
正解ラベル: 1, 予測ラベル: 2, テキスト: チッックインが遅くなることと雨が降っていたため夕食を済ませてからホテルに着きましたが、カレーのサービスを行っていました。
正解ラベル: 0, 予測ラベル: 1, テキスト: 18:00の予約で入って料理をとったところ保温トレーの中の料理はどれもぬるい程度の温度で、松茸茶碗蒸しは容器が冷たい程で驚きました。
正解ラベル: 0, 予測ラベル: 1, テキスト: 粉コーヒーでもいいのでいつでも飲めるようになってればなぁ。
正解ラベル: 2, 予測ラベル: 1, テキスト: 全てはフロントの方の心遣いにあると思います。
正解ラベル: 2, 予測ラベル: 1, テキスト: シングルルームを2部屋予約しましたが、当日部屋が空いてるとの事で大きな部屋に変更してくださいました。
正解ラベル: 2, 予測ラベル: 1, テキスト: 料理はみんなきれいに盛られ、おいしかったですが、なにか一つ地のもので、「ここでしか食べられない」とか「何か特化したもの」があったらさらに良かったと思います。
正解ラベル: 2, 予測ラベル: 1, テキスト: お風呂場にタオルの設置があったらいいなと思うのと、朝食会場が宿泊者の人数の割に狭いのが少し惜しい気がしましたが、いいホテルに泊まって気持ちよく過ごせました。
正解ラベル: 1, 予測ラベル: 2, テキスト: 朝食は長い列ができていたが、案外すぐに呼ばれた。
正解ラベル: 1, 予測ラベル: 2, テキスト: 海沿いの立地のためか日の出スポットらしく元旦に続々前回道路に人が集まってました。
正解ラベル: 1, 予測ラベル: 2, テキスト: あと、お宿横には酒屋さん!
正解ラベル: 1, 予測ラベル: 2, テキスト: 温泉が深夜男女入替のため、チェックイン後とチェックアウト後に入浴すると両方楽しめます。
正解ラベル: 1, 予測ラベル: 2, テキスト: 温泉チケット付きのプランでしたので目の前の温泉にいきました。
正解ラベル: 1, 予測ラベル: 2, テキスト: 他は完璧だと思う。
正解ラベル: 1, 予測ラベル: 2, テキスト: 夕食の際、誕生日の特別デザートを用意頂いたり、希望すればチャンチャンコを貸して頂くこともできるようでした。