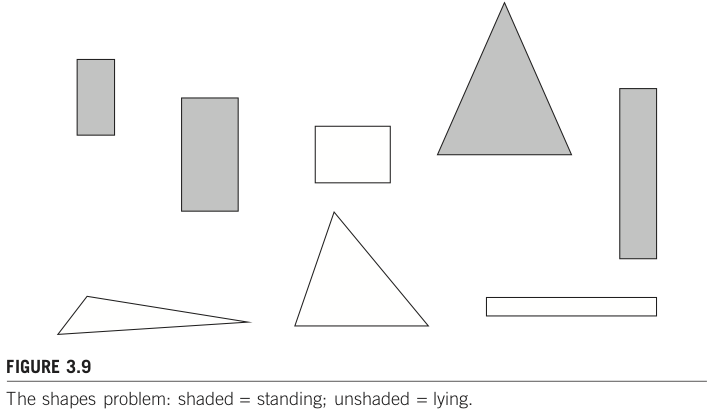
係り受けを用いた目的語抽出+ネットワーク描画の例
目次
20. 係り受けを用いた目的語抽出+ネットワーク描画の例¶
自然言語処理における代表的な情報抽出には、(1) 表面的な文字そのものを指定する方法、(2) 品詞を指定する方法、(3) 係り受け関係を指定する方法、(4) 分散表現による距離を参照する方法がある。
ここでは係り受け関係の例として「目的語 => 係り受け先」という関係を抽出してみよう。例えば「例題を取り入れて理解しやすくしてほしい。」という文においては「例題 => 取り入れ」がこの関係に相当する。この例では「例題」が目的語(UDではtoken.dep_ == obj)となり、「取り入れ」が係り受け先(UDではtoken.head)に相当する。
NOTE
ネットワーク描画のために networkx, pyviz を利用している。これらは pip install でインストール可能。
networkx はネットワーク描画や分析等に使われるライブラリ。本来ならこれだけで済むことが多いが、日本語には未対応のため pyviz (グラフ描画ライブラリ)も利用している。
pyviz注意点。
Google Colab ではやや取り扱いに難がある。具体的には pip install 後に一旦カーネルに再接続し直す必要がある。
Pythonスクリプトとして実行するか、ノートブック(ipynb)として実行するかによりコードがやや異なる。具体的にはコード内コメントを参照。
参考
20.1. 利用ライブラリの用意、データセット準備¶
事前に、load_r_assesment.ipynb でデータセットを作成し、pkl形式でファイル保存(r_assesment.pkl)しておく。今回は作成済みファイルをダウンロードして利用することにする。
r_assesment.pklは授業評価アンケートの自由記述欄をpd.DataFrame形式で保存したもので、授業名(title)、学年(grade)、必修か否か(required)、質問番号(q_id)、コメント(comment)で構成される。
!curl -O https://ie.u-ryukyu.ac.jp/~tnal/2022/dm/static/r_assesment.pkl
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 34834 100 34834 0 0 71686 0 --:--:-- --:--:-- --:--:-- 72722
import collections
import numpy as np
import pandas as pd
import spacy
import networkx as nx
import matplotlib.pyplot as plt
import japanize_matplotlib
nlp = spacy.load("ja_ginza")
assesment_df = pd.read_pickle('r_assesment.pkl')
assesment_df.head()
| title | grade | required | q_id | comment | |
|---|---|---|---|---|---|
| 0 | 工業数学Ⅰ | 1 | True | Q21 (1) | 特になし |
| 1 | 工業数学Ⅰ | 1 | True | Q21 (2) | 正直わかりずらい。むだに間があるし。 |
| 2 | 工業数学Ⅰ | 1 | True | Q21 (2) | 例題を取り入れて理解しやすくしてほしい。 |
| 3 | 工業数学Ⅰ | 1 | True | Q21 (2) | 特になし |
| 4 | 工業数学Ⅰ | 1 | True | Q21 (2) | スライドに書く文字をもう少しわかりやすくして欲しいです。 |
from spacy import displacy
sample = assesment_df['comment'][2]
print('sample = ', sample)
doc = nlp(sample)
displacy.render(doc, style="dep", options={"compact":True})
sample = 例題を取り入れて理解しやすくしてほしい。
from spacy.symbols import obj
for token in doc:
if token.dep == obj:
print(token.text, token.head.text)
例題 取り入れ
20.2. 目的語とその係り受け先を抽出してみよう¶
{‘例題_取り入れ’:1], ,,,}のように obj と token.head をアンダースコアで結んだ文字列を作り、その文字列が出現した回数も同時にカウントしてみる。
from spacy.symbols import obj
result = {}
for text in assesment_df['comment']:
doc = nlp(text)
for token in doc:
if token.dep == obj:
target = token.lemma_ + '_' + token.head.lemma_
if target not in result:
result[target] = 1
else:
result[target] += 1
print(collections.Counter(result))
Counter({'課題_出す': 3, '講義_受ける': 3, 'こと_学ぶ': 2, '講義_通す': 2, '話_聞く': 2, '予習_する': 2, '解答_出す': 2, '単位_落とす': 2, '知識_獲得': 2, '仮説_立てる': 2, '手法_使う': 2, '例題_取り入れる': 1, '文字_する': 1, '行列_扱う': 1, '演習_出す': 1, '時間_おく': 1, '何_話す': 1, '道徳_学ぶ': 1, '想い_考える': 1, '品性_伸ばす': 1, 'こと_学べる': 1, 'こと_知れる': 1, '考え方_持てる': 1, '興味_持つ': 1, '心_学べる': 1, '側面_見れる': 1, 'これ_考える': 1, '計画_立てる': 1, '将来_想像': 1, 'アドバイス_もらえる': 1, 'マナー_学べる': 1, 'ある_知る': 1, 'ニーズ_聞ける': 1, '友達_作る': 1, '作成_通す': 1, '将来_見通す': 1, '機会_設ける': 1, '対面_増やす': 1, '課題_変更': 1, 'プログラミング_学べる': 1, 'それ_完成': 1, '復習_こなせる': 1, '基礎_学ぶ': 1, '課題_見る': 1, 'コード_良い': 1, 'プログラミング_触る': 1, '予想_上回る': 1, '復習_する': 1, '言語_学ぶ': 1, '課題_やる': 1, 'プログラミング_学ぶ': 1, 'こと_覚える': 1, '知識_生かす': 1, '演習_通す': 1, '基礎_定着': 1, 'デンチュウ_動かす': 1, 'denchu_通す': 1, '方_知る': 1, 'コード_書く': 1, 'denchu_動かす': 1, 'プログラミング_楽しい': 1, 'こと_実践': 1, '事_落とし込む': 1, 'メモ書き_消す': 1, 'こと_書く': 1, 'こと_聞く': 1, '環境_作る': 1, '点数_教える': 1, '提出_行う': 1, 'コマンド_打つ': 1, '方_招待': 1, '資料_理解': 1, '授業_理解': 1, 'テスト_延期': 1, '試験_続ける': 1, 'まとめ方_する': 1, '内容_補強': 1, '不便_感ずる': 1, 'メール_読む': 1, 'チャンネル_開設': 1, '内容_アウトプット': 1, 'ペン_使う': 1, '説明_聞く': 1, '何_言う': 1, '点数_公開': 1, '点_送る': 1, '採点_願う': 1, '試験_実施': 1, '試験_行なう': 1, 'ら_用いる': 1, '勉強_する': 1, 'ところ_調べる': 1, '採点_使う': 1, 'プログラム_作る': 1, '内容_網羅': 1, '提出期間_過ぎる': 1, '試験_する': 1, '解決策_考える': 1, '問題_解決': 1, '試験_受ける': 1, '環境_整える': 1, '回答_出す': 1, '理解_測る': 1, 'こと_する': 1, '試験_もつ': 1, '間違い_指摘': 1, '授業_受ける': 1, '説明_書く': 1, '難易度_する': 1, '過去問_配布': 1, '要点_押さえる': 1, '不満_書く': 1, '部分_ミス': 1, 'こと_望む': 1, '自学_増やす': 1, '質問_する': 1, '説明_する': 1, '動き_理解': 1, '欲_言う': 1, '緊張感_持てる': 1, '課題_再提出': 1, '間隔_空ける': 1, '時間_作る': 1, '知識_利用': 1, '知識_使う': 1, '研究_踏まえる': 1, '講義_する': 1, '録画_残す': 1, '大切_学ぶ': 1, '成績_決定': 1, '資料_写す': 1, '使う_学ぶ': 1, '配分_間違える': 1, '結果_出す': 1, 'こと_使う': 1, 'こと_実感': 1, 'アイディア_出す': 1, '物事_伝える': 1, 'スキル_向上': 1, '書_紹介': 1, '力_活かす': 1, '情報_得る': 1, '時間_とる': 1, '顔_合わせる': 1, '説明_行く': 1, '手_焼く': 1, '報告会_行う': 1, 'javascript_用いる': 1, 'アプリケーション_開発': 1, 'コーディング_教える': 1, 'フレームワーク_試す': 1})
20.3. ネットワーク描画してみる¶
「目的語=>係り受け先単語」の関係を「単語間動詞を接続したエッジ」として可視化してみよう。まずはpd.DataFrame形式で「係り受け元単語、係り受け先単語、出現回数」として保存し直す。
columns = ['from', 'to', 'weight']
df = pd.DataFrame(columns=columns)
index = 0
nodes = []
for key, value in result.items():
node1, node2 = key.split('_')
if node1 not in nodes:
nodes.append(node1)
if node2 not in nodes:
nodes.append(node2)
df.loc[index] = [node1, node2, value]
index += 1
df
| from | to | weight | |
|---|---|---|---|
| 0 | 例題 | 取り入れる | 1 |
| 1 | 文字 | する | 1 |
| 2 | 行列 | 扱う | 1 |
| 3 | 演習 | 出す | 1 |
| 4 | 時間 | おく | 1 |
| ... | ... | ... | ... |
| 146 | 報告会 | 行う | 1 |
| 147 | javascript | 用いる | 1 |
| 148 | アプリケーション | 開発 | 1 |
| 149 | コーディング | 教える | 1 |
| 150 | フレームワーク | 試す | 1 |
151 rows × 3 columns
20.4. networkx + pyvizで描画¶
networkxはネットワークの描画・操作・解析などに使われるライブラリ。
pyvizはグラフ描画ライブラリ。
グラフ描画するだけなら networkx + matplotlib でも可能だが、日本語には未対応で文字化けしてしまうため、ここではpyvizを採用している。
import networkx as nx
from pyvis.network import Network
G = nx.from_pandas_edgelist(df, source='from', target='to', edge_attr='weight')
pyvis_G = Network(notebook=True) # .pyで実行するならFalse
pyvis_G.from_nx(G)
pyvis_G.show('mygraph.html')