4. matplotlib入門¶
# 適当なデータを用意
import numpy as np
datasets = np.array([[4,7], [8,10], [13,11], [17,14]])
x = datasets[:,0]
y = datasets[:,1]
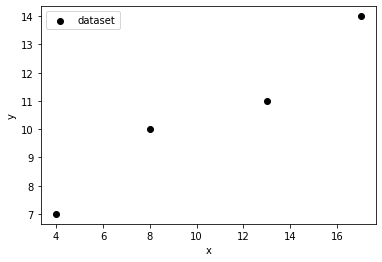
# サンプルを点で描画
import matplotlib.pyplot as plt
plt.scatter(x, y, color="black", label="dataset")
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc="best")
plt.show()
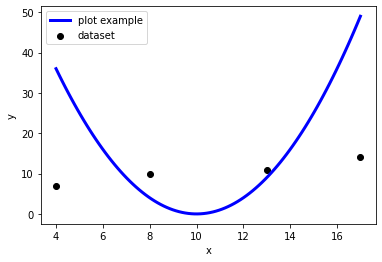
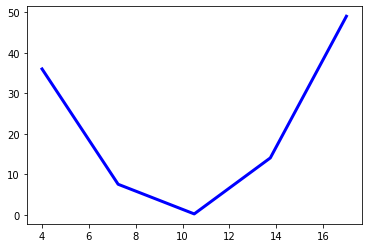
# 線グラフ描画するための適当な関数を用意
def function(x):
return (x-10)**2
x2 = np.linspace(4, 17, 5) #定義域[4,17]で5等分したサンプルを用意
y2 = function(x2) #サンプルにおけるyの値を準備
plt.plot(x2, y2, color="blue", linewidth=3, label="plot example")
plt.show()
#サンプル数を増やしてもう一度実行
x2 = np.linspace(4, 17, 100)
y2 = function(x2)
plt.plot(x2, y2, color="blue", linewidth=3, label="plot example")
plt.show()
#複数のグラフを1つに描画
plt.scatter(x, y, color="black", label="dataset")
plt.xlabel('x')
plt.ylabel('y')
plt.plot(x2, y2, color="blue", linewidth=3, label="plot example")
plt.legend(loc="best")
plt.show()