5. 代表的な自然言語処理; 日本語, spacyコード編¶
mecabによる形態素解析
出力オプションの例
ノード単位で処理し、原型取得する例
NLTKの利用
KWIC(もしくはKWIC index)
コロケーション(collocations)
単語の出現頻度順
単語の条件付き出現頻度
KNPによる係り受け解析
文節単位での処理例
係り受けを利用したクエリ検索例
5.1. 環境構築¶
!date
# 1. spacy, ginzaインストール
#!pip install -U spacy ginza
!pip install -U ginza
# 2. 言語モデルダウンロード sm=small, lg=large
!python -m spacy download ja_core_news_sm
#!python -m spacy download ja_core_news_lg
# 3. NLTKインストール
!pip install nltk
# 3. データセット用意
# データ準備
# https://newtechnologylifestyle.net/711-2/
# momotaro.txtは、上記を使ってルビを除外したもの。
!curl -O https://raw.githubusercontent.com/naltoma/datamining_intro/master/3-nlp/corpus/momotaro.txt
!mkdir corpus
!mv momotaro.txt corpus/
filename = "./corpus/momotaro.txt"
# 4. matplotlib で日本語フォントを使うための環境構築
!pip install japanize-matplotlib
# パッケージ管理リストを更新
import pkg_resources, imp
imp.reload(pkg_resources)
!date
Wed Apr 14 06:19:30 UTC 2021
Collecting ginza
Downloading https://files.pythonhosted.org/packages/a6/cc/5d3a9230cf3dd8426d0fc147133eb49913acdb8a6c8828320a7c8e2ae8b9/ginza-4.0.5.tar.gz
Collecting spacy<3.0.0,>=2.3.2
?25l Downloading https://files.pythonhosted.org/packages/95/89/1539c4024c339650c222b0b2ca2b3e3f13523b7a02671f8001b7b1cee6f2/spacy-2.3.5-cp37-cp37m-manylinux2014_x86_64.whl (10.4MB)
|████████████████████████████████| 10.4MB 8.7MB/s
?25hCollecting ja_ginza<4.1.0,>=4.0.0
?25l Downloading https://files.pythonhosted.org/packages/89/7d/c8778b5472082da8488b2686cbab3e34ab371fa038c1a712a8d55d8dba2b/ja_ginza-4.0.0.tar.gz (51.5MB)
|████████████████████████████████| 51.5MB 83kB/s
?25hCollecting SudachiPy>=0.4.9
?25l Downloading https://files.pythonhosted.org/packages/86/c9/1ccdbb8cb70925b6a6b0b99c2574b453c1dfee08695dd1ebbe6f966bc42f/SudachiPy-0.5.2.tar.gz (70kB)
|████████████████████████████████| 71kB 4.1MB/s
?25hCollecting SudachiDict-core>=20200330
Downloading https://files.pythonhosted.org/packages/e4/b9/ae63802ffa1cbeca5b984a6ff8afcb70e30448b897feb74904a068897ebc/SudachiDict-core-20201223.post1.tar.gz
Requirement already satisfied, skipping upgrade: requests<3.0.0,>=2.13.0 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (2.23.0)
Requirement already satisfied, skipping upgrade: preshed<3.1.0,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (3.0.5)
Requirement already satisfied, skipping upgrade: blis<0.8.0,>=0.4.0 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (0.4.1)
Requirement already satisfied, skipping upgrade: wasabi<1.1.0,>=0.4.0 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (0.8.2)
Requirement already satisfied, skipping upgrade: plac<1.2.0,>=0.9.6 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (1.1.3)
Requirement already satisfied, skipping upgrade: tqdm<5.0.0,>=4.38.0 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (4.41.1)
Requirement already satisfied, skipping upgrade: srsly<1.1.0,>=1.0.2 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (1.0.5)
Requirement already satisfied, skipping upgrade: murmurhash<1.1.0,>=0.28.0 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (1.0.5)
Requirement already satisfied, skipping upgrade: catalogue<1.1.0,>=0.0.7 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (1.0.0)
Collecting thinc<7.5.0,>=7.4.1
?25l Downloading https://files.pythonhosted.org/packages/9a/92/71ab278f865f7565c37ed6917d0f23342e4f9a0633013113bd435cf0a691/thinc-7.4.5-cp37-cp37m-manylinux2014_x86_64.whl (1.0MB)
|████████████████████████████████| 1.1MB 32.4MB/s
?25hRequirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (54.2.0)
Requirement already satisfied, skipping upgrade: numpy>=1.15.0 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (1.19.5)
Requirement already satisfied, skipping upgrade: cymem<2.1.0,>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from spacy<3.0.0,>=2.3.2->ginza) (2.0.5)
Collecting sortedcontainers~=2.1.0
Downloading https://files.pythonhosted.org/packages/13/f3/cf85f7c3a2dbd1a515d51e1f1676d971abe41bba6f4ab5443240d9a78e5b/sortedcontainers-2.1.0-py2.py3-none-any.whl
Collecting dartsclone~=0.9.0
?25l Downloading https://files.pythonhosted.org/packages/63/6e/3680ae2eb9fe32698f7489630186314106b8464ad37747268ff36fe2dec7/dartsclone-0.9.0-cp37-cp37m-manylinux1_x86_64.whl (473kB)
|████████████████████████████████| 481kB 43.6MB/s
?25hRequirement already satisfied, skipping upgrade: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.0.0,>=2.3.2->ginza) (3.0.4)
Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.0.0,>=2.3.2->ginza) (2020.12.5)
Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.0.0,>=2.3.2->ginza) (1.24.3)
Requirement already satisfied, skipping upgrade: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.0.0,>=2.3.2->ginza) (2.10)
Requirement already satisfied, skipping upgrade: importlib-metadata>=0.20; python_version < "3.8" in /usr/local/lib/python3.7/dist-packages (from catalogue<1.1.0,>=0.0.7->spacy<3.0.0,>=2.3.2->ginza) (3.10.0)
Requirement already satisfied, skipping upgrade: Cython in /usr/local/lib/python3.7/dist-packages (from dartsclone~=0.9.0->SudachiPy>=0.4.9->ginza) (0.29.22)
Requirement already satisfied, skipping upgrade: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata>=0.20; python_version < "3.8"->catalogue<1.1.0,>=0.0.7->spacy<3.0.0,>=2.3.2->ginza) (3.4.1)
Requirement already satisfied, skipping upgrade: typing-extensions>=3.6.4; python_version < "3.8" in /usr/local/lib/python3.7/dist-packages (from importlib-metadata>=0.20; python_version < "3.8"->catalogue<1.1.0,>=0.0.7->spacy<3.0.0,>=2.3.2->ginza) (3.7.4.3)
Building wheels for collected packages: ginza, ja-ginza, SudachiPy, SudachiDict-core
Building wheel for ginza (setup.py) ... ?25l?25hdone
Created wheel for ginza: filename=ginza-4.0.5-cp37-none-any.whl size=15896 sha256=aeedfcfb1f949ff0af4a9b8609bd0327c465282b81c7a6434cf2e05914b76aba
Stored in directory: /root/.cache/pip/wheels/a2/4f/b8/74029780ece4fedfa1f16ba6b9b86fdeee8260ade265e3756e
Building wheel for ja-ginza (setup.py) ... ?25l?25hdone
Created wheel for ja-ginza: filename=ja_ginza-4.0.0-cp37-none-any.whl size=51530814 sha256=b4cd3548e65fb54ea7f7e1dcb6a36050c0fd368fbc6a1ce0cf53c22909e22b37
Stored in directory: /root/.cache/pip/wheels/28/5a/c0/95ac590b39eff99c77d729f284341d15a6903e4011d70ff421
Building wheel for SudachiPy (setup.py) ... ?25l?25hdone
Created wheel for SudachiPy: filename=SudachiPy-0.5.2-cp37-cp37m-linux_x86_64.whl size=870187 sha256=b0f1e1cf199c424c977e50ec91c98bd389a4a059aac1af2aa2ca7e8773d419e6
Stored in directory: /root/.cache/pip/wheels/f1/cc/90/8c68725c622127bb3e5dc46756a8c03bd548dc6d756e66c72d
Building wheel for SudachiDict-core (setup.py) ... ?25l?25hdone
Created wheel for SudachiDict-core: filename=SudachiDict_core-20201223.post1-cp37-none-any.whl size=71405681 sha256=ac249b6dcd6d09bc5522d803d53413978a9713b4a98e7aa9d9ead8d7ca440a31
Stored in directory: /root/.cache/pip/wheels/d4/f8/ff/f9465f9313f865acb1c5500f4d538c470b163b674e184a90d7
Successfully built ginza ja-ginza SudachiPy SudachiDict-core
Installing collected packages: thinc, spacy, ja-ginza, sortedcontainers, dartsclone, SudachiPy, SudachiDict-core, ginza
Found existing installation: thinc 7.4.0
Uninstalling thinc-7.4.0:
Successfully uninstalled thinc-7.4.0
Found existing installation: spacy 2.2.4
Uninstalling spacy-2.2.4:
Successfully uninstalled spacy-2.2.4
Found existing installation: sortedcontainers 2.3.0
Uninstalling sortedcontainers-2.3.0:
Successfully uninstalled sortedcontainers-2.3.0
Successfully installed SudachiDict-core-20201223.post1 SudachiPy-0.5.2 dartsclone-0.9.0 ginza-4.0.5 ja-ginza-4.0.0 sortedcontainers-2.1.0 spacy-2.3.5 thinc-7.4.5
Collecting ja_core_news_sm==2.3.2
?25l Downloading https://github.com/explosion/spacy-models/releases/download/ja_core_news_sm-2.3.2/ja_core_news_sm-2.3.2.tar.gz (7.6MB)
|████████████████████████████████| 7.6MB 8.2MB/s
?25hRequirement already satisfied: spacy<2.4.0,>=2.3.0 in /usr/local/lib/python3.7/dist-packages (from ja_core_news_sm==2.3.2) (2.3.5)
Requirement already satisfied: sudachipy>=0.4.5 in /usr/local/lib/python3.7/dist-packages (from ja_core_news_sm==2.3.2) (0.5.2)
Requirement already satisfied: sudachidict_core>=20200330 in /usr/local/lib/python3.7/dist-packages (from ja_core_news_sm==2.3.2) (20201223.post1)
Requirement already satisfied: plac<1.2.0,>=0.9.6 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (1.1.3)
Requirement already satisfied: preshed<3.1.0,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (3.0.5)
Requirement already satisfied: cymem<2.1.0,>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (2.0.5)
Requirement already satisfied: srsly<1.1.0,>=1.0.2 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (1.0.5)
Requirement already satisfied: setuptools in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (54.2.0)
Requirement already satisfied: numpy>=1.15.0 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (1.19.5)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (2.23.0)
Requirement already satisfied: wasabi<1.1.0,>=0.4.0 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (0.8.2)
Requirement already satisfied: tqdm<5.0.0,>=4.38.0 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (4.41.1)
Requirement already satisfied: thinc<7.5.0,>=7.4.1 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (7.4.5)
Requirement already satisfied: murmurhash<1.1.0,>=0.28.0 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (1.0.5)
Requirement already satisfied: blis<0.8.0,>=0.4.0 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (0.4.1)
Requirement already satisfied: catalogue<1.1.0,>=0.0.7 in /usr/local/lib/python3.7/dist-packages (from spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (1.0.0)
Requirement already satisfied: sortedcontainers~=2.1.0 in /usr/local/lib/python3.7/dist-packages (from sudachipy>=0.4.5->ja_core_news_sm==2.3.2) (2.1.0)
Requirement already satisfied: dartsclone~=0.9.0 in /usr/local/lib/python3.7/dist-packages (from sudachipy>=0.4.5->ja_core_news_sm==2.3.2) (0.9.0)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (2020.12.5)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (2.10)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (3.0.4)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (1.24.3)
Requirement already satisfied: importlib-metadata>=0.20; python_version < "3.8" in /usr/local/lib/python3.7/dist-packages (from catalogue<1.1.0,>=0.0.7->spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (3.10.0)
Requirement already satisfied: Cython in /usr/local/lib/python3.7/dist-packages (from dartsclone~=0.9.0->sudachipy>=0.4.5->ja_core_news_sm==2.3.2) (0.29.22)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata>=0.20; python_version < "3.8"->catalogue<1.1.0,>=0.0.7->spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (3.4.1)
Requirement already satisfied: typing-extensions>=3.6.4; python_version < "3.8" in /usr/local/lib/python3.7/dist-packages (from importlib-metadata>=0.20; python_version < "3.8"->catalogue<1.1.0,>=0.0.7->spacy<2.4.0,>=2.3.0->ja_core_news_sm==2.3.2) (3.7.4.3)
Building wheels for collected packages: ja-core-news-sm
Building wheel for ja-core-news-sm (setup.py) ... ?25l?25hdone
Created wheel for ja-core-news-sm: filename=ja_core_news_sm-2.3.2-cp37-none-any.whl size=7572679 sha256=bc3aea891ea6181d0d6a2b013ae7b09d00098ab922283e9330d57cb917d3c244
Stored in directory: /tmp/pip-ephem-wheel-cache-6w1zjosc/wheels/a9/90/6f/9fdba619c4403234b2695fd40d77e635a6c80672a6a05920f0
Successfully built ja-core-news-sm
Installing collected packages: ja-core-news-sm
Successfully installed ja-core-news-sm-2.3.2
✔ Download and installation successful
You can now load the model via spacy.load('ja_core_news_sm')
Requirement already satisfied: nltk in /usr/local/lib/python3.7/dist-packages (3.2.5)
Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from nltk) (1.15.0)
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 16575 100 16575 0 0 75340 0 --:--:-- --:--:-- --:--:-- 75340
Collecting japanize-matplotlib
?25l Downloading https://files.pythonhosted.org/packages/aa/85/08a4b7fe8987582d99d9bb7ad0ff1ec75439359a7f9690a0dbf2dbf98b15/japanize-matplotlib-1.1.3.tar.gz (4.1MB)
|████████████████████████████████| 4.1MB 10.6MB/s
?25hRequirement already satisfied: matplotlib in /usr/local/lib/python3.7/dist-packages (from japanize-matplotlib) (3.2.2)
Requirement already satisfied: numpy>=1.11 in /usr/local/lib/python3.7/dist-packages (from matplotlib->japanize-matplotlib) (1.19.5)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->japanize-matplotlib) (1.3.1)
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->japanize-matplotlib) (2.8.1)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib->japanize-matplotlib) (0.10.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->japanize-matplotlib) (2.4.7)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.1->matplotlib->japanize-matplotlib) (1.15.0)
Building wheels for collected packages: japanize-matplotlib
Building wheel for japanize-matplotlib (setup.py) ... ?25l?25hdone
Created wheel for japanize-matplotlib: filename=japanize_matplotlib-1.1.3-cp37-none-any.whl size=4120276 sha256=ab44d978253c7da17ff9361554f781a3abbd3ca5ecc028ceb4ab12fd53dc76ab
Stored in directory: /root/.cache/pip/wheels/b7/d9/a2/f907d50b32a2d2008ce5d691d30fb6569c2c93eefcfde55202
Successfully built japanize-matplotlib
Installing collected packages: japanize-matplotlib
Successfully installed japanize-matplotlib-1.1.3
Wed Apr 14 06:21:04 UTC 2021
5.2. 形態素解析¶
# 形態素解析
# 学習済みモデルにより解析結果(推定結果)が変わる
# Models & Languages: https://spacy.io/usage/models
import spacy
# Ginza利用
nlp = spacy.load("ja_ginza")
sentence = "格闘家ボブ・サップの出身国はどこでしょう。"
doc = nlp(sentence)
for sent in doc.sents:
for token in sent:
print(token)
print("EOS")
print("-----")
# ja_core_news_sm利用
nlp = spacy.load("ja_core_news_sm")
doc = nlp(sentence)
for sent in doc.sents:
for token in sent:
print(token)
print("EOS")
# 以下では ginza で実行。
nlp = spacy.load("ja_ginza")
格闘家
ボブ
・
サップ
の
出身国
は
どこ
でしょう
。
EOS
-----
格闘
家
ボブ
・
サップ
の
出身
国
は
どこ
でしょう
。
EOS
# parse結果の例
import pandas as pd
import numpy as np
text = '日本予防医学協会の説明に検査項目ごとの基準値が示されている。例えばASTは0〜40U/L、総コレステロールは130〜219mg/dL、HbA1cは4.6〜5.5%といった具合だ。'
doc = nlp(text)
columns = ["index", ".text", "t.lemma_", ".pos_", ".dep_",
".head.text", ".is_punct", ".is_digit", ".like_num"]
index = list(range(len(doc)))
data = []
for token in doc:
parsed = [token.i, token.text, token.lemma_, token.pos_, token.dep_,
token.head.text, token.is_punct, token.is_digit, token.like_num]
data.append(parsed)
df = pd.DataFrame(np.array(data), columns=columns, index=index)
df
| index | .text | t.lemma_ | .pos_ | .dep_ | .head.text | .is_punct | .is_digit | .like_num | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 日本 | 日本 | PROPN | compound | 協会 | False | False | False |
| 1 | 1 | 予防 | 予防 | NOUN | compound | 協会 | False | False | False |
| 2 | 2 | 医学 | 医学 | NOUN | compound | 協会 | False | False | False |
| 3 | 3 | 協会 | 協会 | NOUN | nmod | 説明 | False | False | False |
| 4 | 4 | の | の | ADP | case | 協会 | False | False | False |
| 5 | 5 | 説明 | 説明 | NOUN | obl | 示さ | False | False | False |
| 6 | 6 | に | に | ADP | case | 説明 | False | False | False |
| 7 | 7 | 検査項目 | 検査項目 | NOUN | compound | ごと | False | False | False |
| 8 | 8 | ごと | ごと | NOUN | nmod | 基準値 | False | False | False |
| 9 | 9 | の | の | ADP | case | ごと | False | False | False |
| 10 | 10 | 基準値 | 基準値 | NOUN | nsubj | 示さ | False | False | False |
| 11 | 11 | が | が | ADP | case | 基準値 | False | False | False |
| 12 | 12 | 示さ | 示す | VERB | ROOT | 示さ | False | False | False |
| 13 | 13 | れ | れる | AUX | aux | 示さ | False | False | False |
| 14 | 14 | て | て | SCONJ | mark | 示さ | False | False | False |
| 15 | 15 | いる | いる | AUX | aux | 示さ | False | False | False |
| 16 | 16 | 。 | 。 | PUNCT | punct | 示さ | True | False | False |
| 17 | 17 | 例えば | 例えば | ADV | advmod | 具合 | False | False | False |
| 18 | 18 | AST | AST | NOUN | nsubj | dL | False | False | False |
| 19 | 19 | は | は | ADP | case | AST | False | False | False |
| 20 | 20 | 0 | 0 | NUM | nummod | L | False | True | True |
| 21 | 21 | 〜 | 〜 | SYM | compound | L | True | False | False |
| 22 | 22 | 40 | 40 | NUM | nummod | L | False | True | True |
| 23 | 23 | U | u | NOUN | compound | L | False | False | False |
| 24 | 24 | / | / | SYM | compound | L | True | False | False |
| 25 | 25 | L | l | NOUN | nmod | 219 | False | False | False |
| 26 | 26 | 、 | 、 | PUNCT | punct | L | True | False | False |
| 27 | 27 | 総 | 総 | NOUN | compound | コレステロール | False | False | False |
| 28 | 28 | コレステロール | コレステロール | NOUN | nsubj | 219 | False | False | False |
| 29 | 29 | は | は | ADP | case | コレステロール | False | False | False |
| 30 | 30 | 130 | 130 | NUM | nummod | 219 | False | True | True |
| 31 | 31 | 〜 | 〜 | SYM | compound | 219 | True | False | False |
| 32 | 32 | 219 | 219 | NUM | nummod | dL | False | True | True |
| 33 | 33 | mg | mg | NOUN | compound | dL | False | False | False |
| 34 | 34 | / | / | SYM | compound | dL | True | False | False |
| 35 | 35 | dL | DL | NOUN | nmod | % | False | False | False |
| 36 | 36 | 、 | 、 | PUNCT | punct | dL | True | False | False |
| 37 | 37 | HbA | hba | NOUN | compound | c | False | False | False |
| 38 | 38 | 1 | 1 | NUM | nummod | c | False | True | True |
| 39 | 39 | c | c | NOUN | nsubj | % | False | False | False |
| 40 | 40 | は | は | ADP | case | c | False | False | False |
| 41 | 41 | 4.6 | 4.6 | NUM | nummod | % | False | False | True |
| 42 | 42 | 〜 | 〜 | SYM | compound | % | True | False | False |
| 43 | 43 | 5.5 | 5.5 | NUM | nummod | % | False | False | True |
| 44 | 44 | % | % | NOUN | nmod | 具合 | True | False | False |
| 45 | 45 | と | と | ADP | case | % | False | False | False |
| 46 | 46 | いっ | いう | VERB | fixed | と | False | False | False |
| 47 | 47 | た | た | AUX | fixed | と | False | False | False |
| 48 | 48 | 具合 | 具合 | NOUN | ROOT | 具合 | False | False | False |
| 49 | 49 | だ | だ | AUX | cop | 具合 | False | False | False |
| 50 | 50 | 。 | 。 | PUNCT | punct | 具合 | True | False | False |
print("----Docオブジェクトから名詞句を抽出----")
for np in doc.noun_chunks:
print(np)
----Docオブジェクトから名詞句を抽出----
日本予防医学協会
説明
検査項目ごと
基準値
AST
0〜40U/L
総コレステロール
130〜219mg/dL
HbA1c
4.6〜5.5%
具合
5.3. コンコーダンス(語句集)¶
# concordance
with open(filename, "r") as fh:
sentences = ""
for line in fh.readlines():
sentences += line + " "
import nltk
nltk.download('stopwords')
def tokenize(sentences):
"""文章を分かち書きする。
:param sentences(str): 複数の文章を含む文字列。日本語想定。
:return(list): 分かち書きした単語をlistとしてまとめたもの。
"""
nlp = spacy.load("ja_ginza")
doc = nlp(sentences)
tokens = []
for token in doc:
word = token.text
if word == " " or word == "\n":
continue
tokens.append(word)
return tokens
tokens = tokenize(sentences)
print(len(tokens), tokens[:10])
text = nltk.Text(tokens)
print('\n# nltk.Text.concordance with "おじいさん"')
text.concordance("おじいさん")
print('\n# nltk.Text.concordance with "じい"')
text.concordance("じい")
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
3600 ['Download', 'URL', '\n ', 'URL', ':', 'https', ':', '/', '/', 'www']
# nltk.Text.concordance with "おじいさん"
No matches
# nltk.Text.concordance with "じい"
Displaying 24 of 24 matches:
p
一
むかし 、 むかし 、 ある ところ に 、 お じい さん と お ばあ さん が あり まし た 。 まいにち 、 お じい
じい さん と お ばあ さん が あり まし た 。 まいにち 、 お じい さん は 山 へ し ば 刈り に 、 お ばあ さん は 川 へ 洗濯
。
「 お やおや 、 これ は みごと な 桃 だ こと 。 お じい さん へ の お みやげ に 、 どれ どれ 、 うち へ 持っ て 帰り
た 。 お ばあ さん は にこにこ し ながら 、
「 早く お じい さん と 二人 で 分け て 食べ ましょう 。 」
と 言っ て
おうち へ 帰り まし た 。
夕方 に なっ て やっと 、 お じい さん は 山 から しば を 背負っ て 帰っ て 来 まし た 。
「 お ばあ さん 、 今 帰っ た よ 。 」
「 おや 、 お じい さん 、 お かい ん なさい 。 待っ て い まし た よ 。 さあ
いい もの と いう の は 。 」
こう いい ながら 、 お じい さん は わらじ を ぬい で 、 上 に 上がり まし た 。 その 間
て 来 た 。 それ は いよいよ めずらしい 。 」
こう お じい さん は 言い ながら 、 桃 を 両手 に のせ て 、 ため つ 、
とび出し まし た 。
「 お やおや 、 まあ 。 」
お じい さん も 、 お ばあ さん も 、 びっくり し て 、 二人 いっしょ
この 子 を さずけ て 下さっ た に ちがい ない 。 」
お じい さん も 、 お ばあ さん も 、 うれし がっ て 、 こう 言い ま
がっ て 、 こう 言い まし た 。
そこ で あわて て お じい さん が お 湯 を わかす やら 、 お ばあ さん が むつき を そ
やおや 、 何 と いう 元気 の いい 子 だろう 。 」
お じい さん と お ばあ さん は 、 こう 言っ て 顔 を 見合わせ ながら
桃太郎 と いう 名 を つけ まし た 。
二
お じい さん と お ばあ さん は 、 それ は それ は だいじ に し て
い でし た が 、 その くせ 気だて は ごく やさしく って 、 お じい さん と お ばあ さん に よく 孝行 を し まし た 。
桃
なく なり まし た 。 そこ で うち へ 帰る と さっそく 、 お じい さん の 前 へ 出 て 、
「 どうぞ 、 わたくし に しばらく
お ひま を 下さい 。 」
と 言い まし た 。
お じい さん は びっくり し て 、
「 お前 どこ へ 行く の だ 。
さましい こと だ 。 じゃあ 行っ て お いで 。 」
と お じい さん は 言い まし た 。
「 まあ 、 そんな 遠方 へ 行く
と お ばあ さん も 言い まし た 。
そこ で 、 お じい さん と お ばあ さん は 、 お 庭 の まん中 に 、 えん やら
、 えん やら 、 えん やら 、 大きな 臼 を 持ち出し て 、 お じい さん が きね を 取る と 、 お ばあ さん はこね どり を し て
りっぱ に 鬼 を 退治 し て くる が いい 。 」
と お じい さん は 言い まし た 。
「 気 を つけ て 、 けが を し
と 元気 な 声 を のこし て 、 出 て いき まし た 。 お じい さん と お ばあ さん は 、 門 の 外 に 立っ て 、 いつ まで
声 を かけ かけ 進ん で いき まし た 。
うち で は お じい さん と 、 お ばあ さん が 、 かわるがわる 、
「 もう 桃
とくい らしい 様子 を し て 帰っ て 来 まし た の で 、 お じい さん も お ばあ さん も 、 目 も 鼻 も なくし て 喜び まし
い ぞ 、 えらい ぞ 、 それ こそ 日本一 だ 。 」
と お じい さん は 言い まし た 。
「 まあ 、 まあ 、 けが が なく
5.4. コロケーション(連語)¶
# collocation
print("\n# nltk.Text.collocations")
print("## default")
text.collocations()
print("\n## collocations(window_size=5)")
text.collocations(window_size=5)
# nltk.Text.collocations
## default
桃太郎; いかめしい くろがね; さけび ながら; 桃太郎
## collocations(window_size=5)
ドンブラコッコ スッコッコ; ていねい おじぎ; 日本一 だんご; たらこ たらこ; Download URL; URL https;
ぎゅうぎゅう 押さえつけ; だんご もらっ; ; いかめしい くろがね; 下さい ましょう; むかし;
桃太郎; キャッ キャッ; スッコッコ ドンブラコッコ; ましょう ; 桃太郎 どちら; 桃太郎 ふり返る; スッコッコ;
ドンブラコッコ
5.5. 単語の出現頻度¶
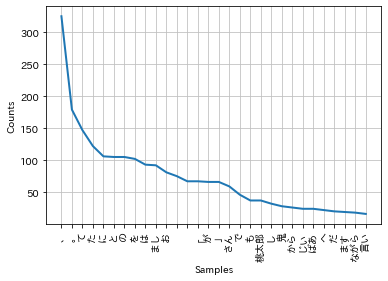
# 単語の出現頻度順
print("\n# FreqDist")
fdist = nltk.FreqDist(tokens)
check_num = 30
print(fdist.most_common(check_num))
%matplotlib inline
import japanize_matplotlib
fdist.plot(check_num)
# FreqDist
[('、', 325), ('。', 179), ('て', 147), ('た', 122), ('に', 106), ('と', 105), ('の', 105), ('を', 102), ('は', 93), ('まし', 92), ('お', 81), ('\n \u3000', 75), ('\n ', 67), ('「', 67), ('が', 66), ('」', 66), ('さん', 59), ('で', 46), ('も', 37), ('桃太郎', 37), ('し', 32), ('鬼', 28), ('から', 26), ('じい', 24), ('ばあ', 24), ('へ', 22), ('だ', 20), ('ます', 19), ('ながら', 18), ('言い', 16)]
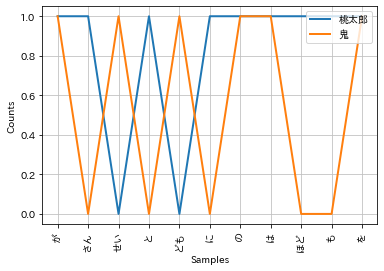
5.6. bi-gram¶
# bigram
print("\n# FreqDist with bigram (2-gram)")
bigrams = nltk.bigrams(tokens)
bigrams_fdist = nltk.FreqDist(bigrams)
print(bigrams_fdist.most_common(check_num))
# conditional FreqDist
cfd = nltk.ConditionalFreqDist(bigrams_fdist)
cfd.plot(conditions=["桃太郎", "鬼"])
# FreqDist with bigram (2-gram)
[(('まし', 'た'), 92), (('た', '。'), 91), (('。', '」'), 66), (('て', '、'), 64), (('\n ', '「'), 57), (('」', '\n \u3000'), 39), (('。', '\n \u3000'), 36), (('。', '\n '), 32), (('、', 'お'), 28), (('は', '、'), 27), (('と', '、'), 26), (('お', 'じい'), 24), (('じい', 'さん'), 24), (('お', 'ばあ'), 24), (('ばあ', 'さん'), 24), (('に', '、'), 23), (('\n \u3000', 'と'), 22), (('し', 'て'), 21), (('さん', 'は'), 19), (('ながら', '、'), 18), (('、', '\n '), 17), (('で', '、'), 16), (('」', '\n '), 16), (('を', 'し'), 14), (('て', 'い'), 13), (('桃太郎', 'は'), 13), (('と', 'お'), 12), (('て', '来'), 12), (('から', '、'), 11), (('言い', 'まし'), 11)]
5.7. 係り受け解析+格解析¶
print("----係り受け木----")
from pathlib import Path
from spacy import displacy
#sentence = "お爺さんは山へ芝刈りに、お婆さんは川へ洗濯に行きました。"
sentence = "お爺さんは山へ芝刈りに行きました。"
doc = nlp(sentence)
for sent in doc.sents:
svg = displacy.render(sent, style="dep", jupyter=True)
----係り受け木----
options = {"compact": True, "bg": "#090305",
"color": "white", "font": "Source Sans Pro"}
for sent in doc.sents:
svg = displacy.render(sent, style="dep", jupyter=True, options=options)
print("----Docオブジェクトから名詞句だけを抽出----")
for chunk in doc.noun_chunks:
print(chunk)
----Docオブジェクトから名詞句だけを抽出----
お爺さん
山
芝刈り
# 名詞句を中心に係り受け
print("chunk\troot\tdep_\troot.head")
labels = set()
for chunk in doc.noun_chunks:
print(chunk.text, chunk.root.text, chunk.root.dep_,
chunk.root.head.text)
labels.add(chunk.root.dep_)
print("----------")
for label in labels:
print('{} = {}'.format(label, spacy.explain(label)))
chunk root dep_ root.head
お爺さん さん nsubj 行き
山 山 obl 行き
芝刈り 芝刈り obl 行き
----------
nsubj = nominal subject
obl = oblique nominal
5.8. 係り受け解析を利用したクエリ検索の例¶
# 係り受けを利用したクエリ検索例
# 補足:
# 係り受け関係が想定と異なっているため、中継単語からの検索まで実装。
def search(sentence, user_query):
nlp = spacy.load("ja_ginza")
doc = nlp(sentence)
relay_words = []
candidate_words = []
# 係り受け先(子ノード)検索
print("# 係り受け先(子ノード)")
for chunk in doc.noun_chunks:
if chunk.text == user_query:
if chunk.root.dep_ == 'obl':
relay_words.append(chunk.root.head.text)
if chunk.root.dep_ == 'nsubj':
candidate_words.append(chunk.root.head.text)
# 中継単語からの検索
if len(relay_words) >= 1:
for word in relay_words:
for chunk in doc.noun_chunks:
if chunk.root.head.text == word:
if chunk.root.dep_ == 'obl':
relay_words.append(chunk.text)
if chunk.root.dep_ == 'nsubj':
candidate_words.append(chunk.text)
return relay_words, candidate_words
sentence = "お爺さんは山へ芝刈りに、お婆さんは川へ洗濯に行きました。"
user_query = "芝刈り"
print('\n# user_query = {}'.format(user_query))
relay_words, candidate_words = search(sentence, user_query)
print("relay_words: ", relay_words)
print("candidate_words: ", candidate_words)
# user_query = 芝刈り
# 係り受け先(子ノード)
relay_words: ['行き', '芝刈り', '川', '洗濯', '山']
candidate_words: ['お爺さん', 'お婆さん']
5.9. 固有表現¶
print("----固有表現----")
doc = nlp(sentence)
print("固有表現,開始index,終了index,ラベル")
for entity in doc.ents:
print(entity.text, entity.start_char, entity.end_char, entity.label_)
----固有表現----
固有表現,開始index,終了index,ラベル
芝刈り 7 10 GOE_Other
!date
Wed Apr 14 06:21:12 UTC 2021