推薦システムのコード例
目次
34. 推薦システムのコード例¶
参考: Collaborative Filtering for Movie Recommendations by Keras例題
全体の流れ
データセットの用意
学習用データ・検証用データに分割
モデル構築
学習
学習過程の観察
top-N推薦
34.1. 環境構築¶
import pandas as pd
import numpy as np
from zipfile import ZipFile
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from pathlib import Path
import matplotlib.pyplot as plt
34.2. データセットの用意¶
MovieLensの小データセットをダウンロード。
pd.read_csvで ratings.csv を DataFrame として読み込む。
# Download the actual data from http://files.grouplens.org/datasets/movielens/ml-latest-small.zip"
# Use the ratings.csv file
movielens_data_file_url = (
"http://files.grouplens.org/datasets/movielens/ml-latest-small.zip"
)
movielens_zipped_file = keras.utils.get_file(
"ml-latest-small.zip", movielens_data_file_url, extract=False
)
keras_datasets_path = Path(movielens_zipped_file).parents[0]
movielens_dir = keras_datasets_path / "ml-latest-small"
# Only extract the data the first time the script is run.
if not movielens_dir.exists():
with ZipFile(movielens_zipped_file, "r") as zip:
# Extract files
print("Extracting all the files now...")
zip.extractall(path=keras_datasets_path)
print("Done!")
ratings_file = movielens_dir / "ratings.csv"
df = pd.read_csv(ratings_file)
df
Downloading data from http://files.grouplens.org/datasets/movielens/ml-latest-small.zip
983040/978202 [==============================] - 0s 0us/step
Extracting all the files now...
Done!
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 |
| 1 | 1 | 3 | 4.0 | 964981247 |
| 2 | 1 | 6 | 4.0 | 964982224 |
| 3 | 1 | 47 | 5.0 | 964983815 |
| 4 | 1 | 50 | 5.0 | 964982931 |
| ... | ... | ... | ... | ... |
| 100831 | 610 | 166534 | 4.0 | 1493848402 |
| 100832 | 610 | 168248 | 5.0 | 1493850091 |
| 100833 | 610 | 168250 | 5.0 | 1494273047 |
| 100834 | 610 | 168252 | 5.0 | 1493846352 |
| 100835 | 610 | 170875 | 3.0 | 1493846415 |
100836 rows × 4 columns
34.3. データ前処理1:連番振り直し¶
userId, movieIDは整数がラベルとして振られているが、欠番が存在する。このままでは扱いづらいため番号を振り直し。
user_ids = df["userId"].unique().tolist()
user2user_encoded = {x: i for i, x in enumerate(user_ids)}
userencoded2user = {i: x for i, x in enumerate(user_ids)}
movie_ids = df["movieId"].unique().tolist()
movie2movie_encoded = {x: i for i, x in enumerate(movie_ids)}
movie_encoded2movie = {i: x for i, x in enumerate(movie_ids)}
df["user"] = df["userId"].map(user2user_encoded)
df["movie"] = df["movieId"].map(movie2movie_encoded)
num_users = len(user2user_encoded)
num_movies = len(movie_encoded2movie)
df["rating"] = df["rating"].values.astype(np.float32)
# min and max ratings will be used to normalize the ratings later
min_rating = min(df["rating"])
max_rating = max(df["rating"])
print(
"Number of users: {}, Number of Movies: {}, Min rating: {}, Max rating: {}".format(
num_users, num_movies, min_rating, max_rating
)
)
Number of users: 610, Number of Movies: 9724, Min rating: 0.5, Max rating: 5.0
df
| userId | movieId | rating | timestamp | user | movie | |
|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 | 0 | 0 |
| 1 | 1 | 3 | 4.0 | 964981247 | 0 | 1 |
| 2 | 1 | 6 | 4.0 | 964982224 | 0 | 2 |
| 3 | 1 | 47 | 5.0 | 964983815 | 0 | 3 |
| 4 | 1 | 50 | 5.0 | 964982931 | 0 | 4 |
| ... | ... | ... | ... | ... | ... | ... |
| 100831 | 610 | 166534 | 4.0 | 1493848402 | 609 | 3120 |
| 100832 | 610 | 168248 | 5.0 | 1493850091 | 609 | 2035 |
| 100833 | 610 | 168250 | 5.0 | 1494273047 | 609 | 3121 |
| 100834 | 610 | 168252 | 5.0 | 1493846352 | 609 | 1392 |
| 100835 | 610 | 170875 | 3.0 | 1493846415 | 609 | 2873 |
100836 rows × 6 columns
34.4. データ前処理2:レーティングを正規化¶
元の評価値は0〜5の範囲を取る。これを学習しやすくするため0〜1の範囲に調整。
df = df.sample(frac=1, random_state=42)
x = df[["user", "movie"]].values
# Normalize the targets between 0 and 1. Makes it easy to train.
y = df["rating"].apply(lambda x: (x - min_rating) / (max_rating - min_rating)).values
学習用データと検証用データに分割
# Assuming training on 90% of the data and validating on 10%.
train_indices = int(0.9 * df.shape[0])
x_train, x_val, y_train, y_val = (
x[:train_indices],
x[train_indices:],
y[:train_indices],
y[train_indices:],
)
print(x_train[0].shape)
print(x_train[0])
print(y_train[0])
(2,)
[ 431 4730]
0.8888888888888888
34.5. モデル構築¶
word2vecでも用いるembeddingレイヤーを用いてモデルを構築している。「ユーザ x レーティング」をtf.tensordotで演算してるだけのシンプルなモデル。
EMBEDDING_SIZE = 50
class RecommenderNet(keras.Model):
def __init__(self, num_users, num_movies, embedding_size, **kwargs):
super(RecommenderNet, self).__init__(**kwargs)
self.num_users = num_users
self.num_movies = num_movies
self.embedding_size = embedding_size
self.user_embedding = layers.Embedding(
num_users,
embedding_size,
embeddings_initializer="he_normal",
embeddings_regularizer=keras.regularizers.l2(1e-6),
)
self.user_bias = layers.Embedding(num_users, 1)
self.movie_embedding = layers.Embedding(
num_movies,
embedding_size,
embeddings_initializer="he_normal",
embeddings_regularizer=keras.regularizers.l2(1e-6),
)
self.movie_bias = layers.Embedding(num_movies, 1)
def call(self, inputs):
user_vector = self.user_embedding(inputs[:, 0])
user_bias = self.user_bias(inputs[:, 0])
movie_vector = self.movie_embedding(inputs[:, 1])
movie_bias = self.movie_bias(inputs[:, 1])
dot_user_movie = tf.tensordot(user_vector, movie_vector, 2)
# Add all the components (including bias)
x = dot_user_movie + user_bias + movie_bias
# The sigmoid activation forces the rating to between 0 and 1
return tf.nn.sigmoid(x)
model = RecommenderNet(num_users, num_movies, EMBEDDING_SIZE)
model.compile(
loss=tf.keras.losses.BinaryCrossentropy(), optimizer=keras.optimizers.Adam(lr=0.001)
)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/optimizer_v2/optimizer_v2.py:375: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
"The `lr` argument is deprecated, use `learning_rate` instead.")
34.6. 学習¶
history = model.fit(
x=x_train,
y=y_train,
batch_size=64,
epochs=5,
verbose=1,
validation_data=(x_val, y_val),
)
Epoch 1/5
1418/1418 [==============================] - 12s 7ms/step - loss: 0.6370 - val_loss: 0.6206
Epoch 2/5
1418/1418 [==============================] - 10s 7ms/step - loss: 0.6135 - val_loss: 0.6168
Epoch 3/5
1418/1418 [==============================] - 10s 7ms/step - loss: 0.6082 - val_loss: 0.6126
Epoch 4/5
1418/1418 [==============================] - 11s 7ms/step - loss: 0.6071 - val_loss: 0.6150
Epoch 5/5
1418/1418 [==============================] - 10s 7ms/step - loss: 0.6078 - val_loss: 0.6123
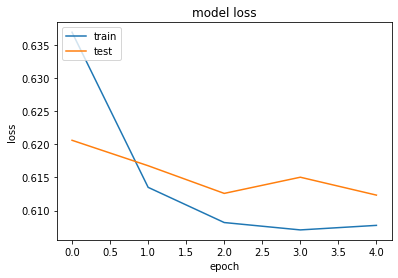
34.7. 学習履歴のグラフ化¶
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
34.8. 上位N件の推薦¶
movie_df = pd.read_csv(movielens_dir / "movies.csv")
# Let us get a user and see the top recommendations.
user_id = df.userId.sample(1).iloc[0]
# 視聴済み映画リスト。
movies_watched_by_user = df[df.userId == user_id]
# 未視聴映画リスト。
# not演算、重複排除。前処理で用意した movie2movie_encoded で前処理し直し。
movies_not_watched = movie_df[
~movie_df["movieId"].isin(movies_watched_by_user.movieId.values)
]["movieId"]
movies_not_watched = list(
set(movies_not_watched).intersection(set(movie2movie_encoded.keys()))
)
movies_not_watched = [[movie2movie_encoded.get(x)] for x in movies_not_watched]
# モデルで予測するためのデータ整形。
user_encoder = user2user_encoded.get(user_id)
user_movie_array = np.hstack(
([[user_encoder]] * len(movies_not_watched), movies_not_watched)
)
# 学習したモデルで予測。上位10件の映画idを取得。
ratings = model.predict(user_movie_array).flatten()
top_ratings_indices = ratings.argsort()[-10:][::-1]
recommended_movie_ids = [
movie_encoded2movie.get(movies_not_watched[x][0]) for x in top_ratings_indices
]
# 視聴済み映画のうち上位5件を出力。
print("Showing recommendations for user: {}".format(user_id))
print("====" * 9)
print("Movies with high ratings from user")
print("----" * 8)
top_movies_user = (
movies_watched_by_user.sort_values(by="rating", ascending=False)
.head(5)
.movieId.values
)
movie_df_rows = movie_df[movie_df["movieId"].isin(top_movies_user)]
for row in movie_df_rows.itertuples():
print(row.title, ":", row.genres)
# 推薦候補上位10件を出力。
print("----" * 8)
print("Top 10 movie recommendations")
print("----" * 8)
recommended_movies = movie_df[movie_df["movieId"].isin(recommended_movie_ids)]
for row in recommended_movies.itertuples():
print(row.title, ":", row.genres)
Showing recommendations for user: 174
====================================
Movies with high ratings from user
--------------------------------
French Kiss (1995) : Action|Comedy|Romance
Ace Ventura: Pet Detective (1994) : Comedy
Jurassic Park (1993) : Action|Adventure|Sci-Fi|Thriller
Tombstone (1993) : Action|Drama|Western
Batman (1989) : Action|Crime|Thriller
--------------------------------
Top 10 movie recommendations
--------------------------------
Braveheart (1995) : Action|Drama|War
Taxi Driver (1976) : Crime|Drama|Thriller
Godfather, The (1972) : Crime|Drama
Reservoir Dogs (1992) : Crime|Mystery|Thriller
Star Wars: Episode V - The Empire Strikes Back (1980) : Action|Adventure|Sci-Fi
Princess Bride, The (1987) : Action|Adventure|Comedy|Fantasy|Romance
Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark) (1981) : Action|Adventure
Lawrence of Arabia (1962) : Adventure|Drama|War
Apocalypse Now (1979) : Action|Drama|War
Goodfellas (1990) : Crime|Drama