京都出張2日目(情報処理学会第77回全国大会 1日目)
暑い。素で暑いよ〜。室内にいる間はコート(薄手)を脱いだけどそれでも暑い。暖房不要だろこれ〜。と思ってたら途中から暖房ではなく換気になってるところも。ですよねー。それでも一部の部屋(特にポスターセッション会場)は熱気が凄かった。冷房必要でしょあれ。





大学近辺にはあちこちにサークル勧誘のポスター/掲示物が。そういう時期だよね。でも3年はないよな(そっちか)。
情報処理学会の全国大会は30ぐらいの通常口頭セッションが走りつつ、他にもイベント企画が用意されてたりするという恐ろしい並列度で動いている(=参加人数ももの凄いことになる)学術会議の一つ。メインイベント時には口頭セッション被らないように工夫するとかもあるけど、今回は「言語処理学会も同時開催」、「京大独自イベント(?)も同時開催」状況になってて、どうしようもない集中具合に。加えて観光客も多数いるわで路線バスが激混み。10分間隔ぐらいで着まくるからそれでも捌けるんだろうけど、清水近辺とかのバス停待ち行列がほぼ減らないという状況。学会参加の点では言語処理学会も覗きに行きたいのだけど、スケジュールがタイト過ぎ。ピンポイントで何かを見に行くぐらいはやれるかもしれないけど、現時点での予定では情報処理学会だけかなぁ。
今日はシンポジウム(講演3件)、うちの学生発表セッション2件、京大のポスターセッション(京都大学第9回ICTイノベーション)を覗いてきました。IPSJ-ONEとかいう「多様な研究分野を垣根なく俯瞰し,すぐれた研究を自らの言葉で語れるプレゼン力の高い,若手を中心とした研究者を,希望する研究会が主体的に推薦する形式で募集」なイベントも面白そうだったんだけど、タイミング合わず。togetterまとめもあるらしいが、映像もあとで公開されるのかしら。と思ったらアーカイブ化も検討中なのね。期待しておこう。
<目次>
- 情報学シンポジウム「ビッグデータとヒューマンサイエンス」
- 講演(1) 脳から心を読む技術:脳情報デコーディング
- 講演(2) 情報通信技術は医療をどう変えようとしているのか?
- 講演(3) 機械学習技術によるビッグデータチャレンジ
- 言語生成とユーザ支援
- 認識・学習・最適化
- 京都大学第9回ICTイノベーション
- お食事
情報学シンポジウム「ビッグデータとヒューマンサイエンス」
講演(1) 脳から心を読む技術:脳情報デコーディング, 神谷 之康 (ATR脳情報研究所 神経情報学研究室・室長)



[サマリ的な何か] 脳波を直接眺めても良く分からないが、差異があることは確か。様々なレベルでノイズが混入する中で、どうデータを収集し、どう分析するか。2005年当時はまだ殆ど機械学習を適用する事例がなかったが、問題設定によっては割とうまくいくらしい。
brain decoding
コーディング: 心->脳波
デコーディング 脳波->心を読み取る
見ても分からない
機械学習によるデコーディング(2005年頃までは殆どやられていなかった)
脳活動を計測し「ラベル」をつける
脳活動からラベルを予測する「デコーダ」を構築する
そのモデルが新たに与えられる脳活動のラベルを正確に予測できるかを評価する
Q: ノイズだらけな気がするが、どうモデル化する? 粗く見ることで軽減できる?2005年当時は3mm角でしか見れなかったが、それでも各マス分布には差異があった
->機械学習classification -> 多様な状態: e.g., 見ているものを画像として取り出すには?
モジュラー・デコーディング(要素の分解、それらの組み合わせとして表現)
視覚像再構成
Q: 情報工学的にはモジュラー・デコーディングで表現できない状態/状況は?
Q: 生態学(?)的には、人間がそういう風に捉えているかどうかはどう検証?
(視覚ならそれで分かっている部分が多いかもしれないが)エンコード vs. デコード・モデル
e.g., 生成モデル vs. DBモデル
物体認識のための階層的視覚特徴抽出, CNN夢の再構成
数分置きに起こして確認寝る
実験自体は比較的簡単だが、画像再構成は困難(視点のずれ?より抽象的な情報?)
言語データベースを用いた意味情報の抽出
夢の意味ラベル
夢の中の「動き」のデコーディング
脳コードコンバータ: 同じ画像見せても脳活動は被験者毎に異なる
講演(2) 情報通信技術は医療をどう変えようとしているのか?, 黒田 知宏 (京都大学医学部附属病院 教授)


[サマリ的な何か] 立地制約上でITCを活用しないと病院内での情報共有すらコストが大きかったこともあり、「単に通信するだけではなく、医療ならではの支援はどうあるべきか」から考え、やれることをやってきている。例えばカルテを電子化するという話もあるが、そもそもカルテに書かれている内容は何なのか。データを蓄積するという側面は大切だが、使えるデータとして整理する必要がある。他の分野に学べる所は学び、実現場に導入するためにはどうしたら良いかを実例を含めて紹介してました。
医療現場の情報化はどこまで進んだか?
京大病院の悪夢(立地条件上建物高さ制限->縦横に長い建造)
KING5: どこでも電子カルテ
ユビキタスセンサネットワーク
Context-Aware IT System: 病院では「場所=コンテキスト」
さりげない情報支援医療情報はビッグデータ?
そもそもカルテに書かれていること
POMR (Problem Oriented Medical Record)
主観的情報/客観的情報、病名、評価、分析、検査や治療指針等の計画
*必ずしもそうなっていない。
保健医療機関及び保健医療担当規則第8条(->保険請求の証拠になる情報)
電子カルテになって
自動的にカルテに記載されるもの: コピペして追記+スキャナ文書
あらゆる情報を未整理に記載: ゴミ箱?
カルテをゴミ箱でなくすためには?
情報を整理する術: e.g., 先例: 飛行機のフライトレコーダー
主観的記録+客観的記録: データと認識を分離
Ubicomp の記録=客観的な記録
4W, 誰がいつ何処で何を)は自動で。
患者とスタッフのライフログ。
標本化定理(とはいえ十分な通院は不可能)->過程に医療機器を。
PHR (Personal Health Record) + PCEHR
カルテは「使えるビッグデータ」ではない
使えるカルテにするために情報の整理
サンプリング周波数を増やす「ソフトウェア薬事」後の医療機器: モジュール化
ゲノムレベルになると人間では対応不可能->コンピュータ化
これからの医者の役割: センサ/翻訳者/医療行為
講演(3) 機械学習技術によるビッグデータチャレンジ, 上田 修功 (NTTコミュニケーション科学基礎研究所 上席特別研究員)


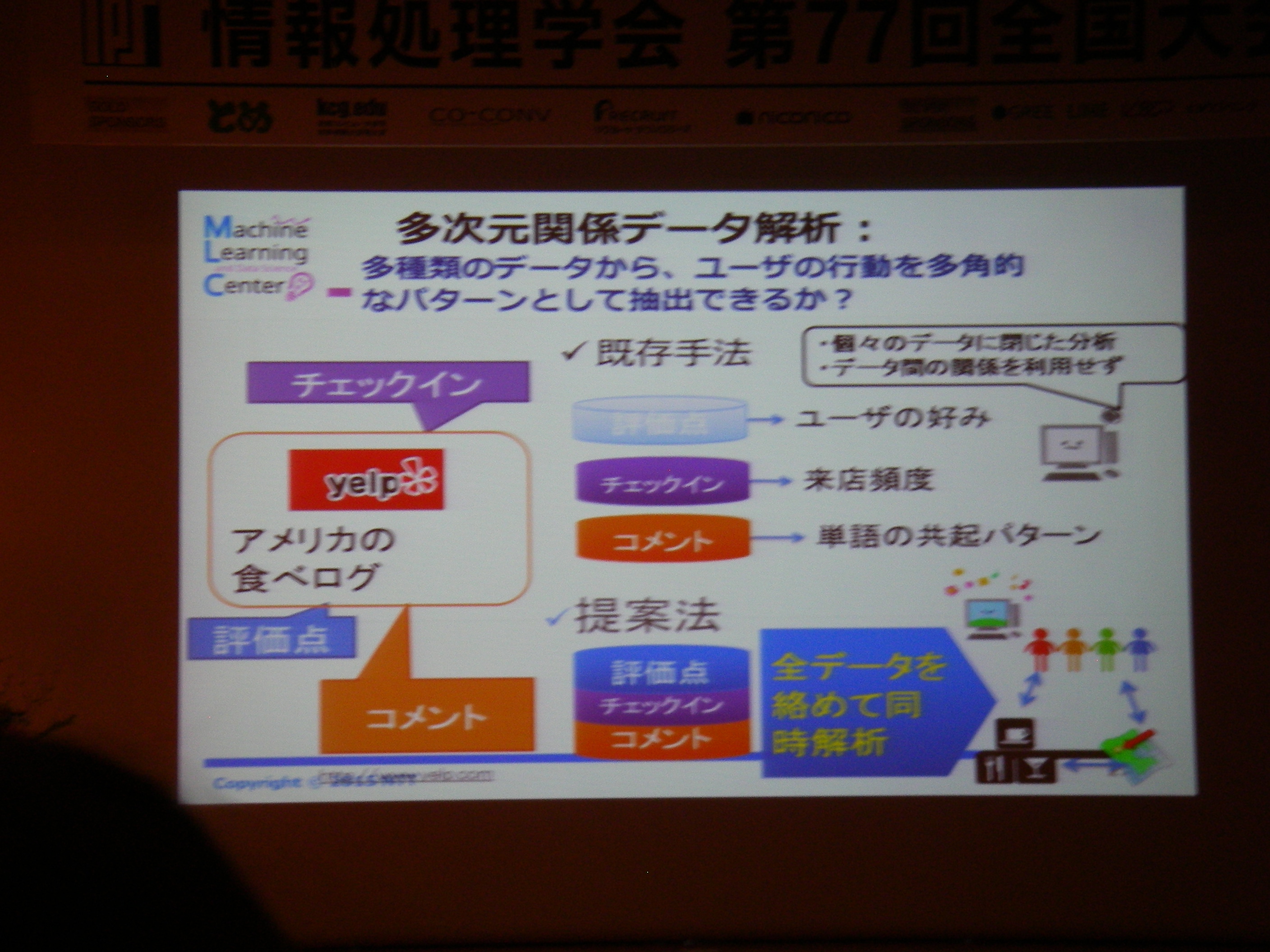
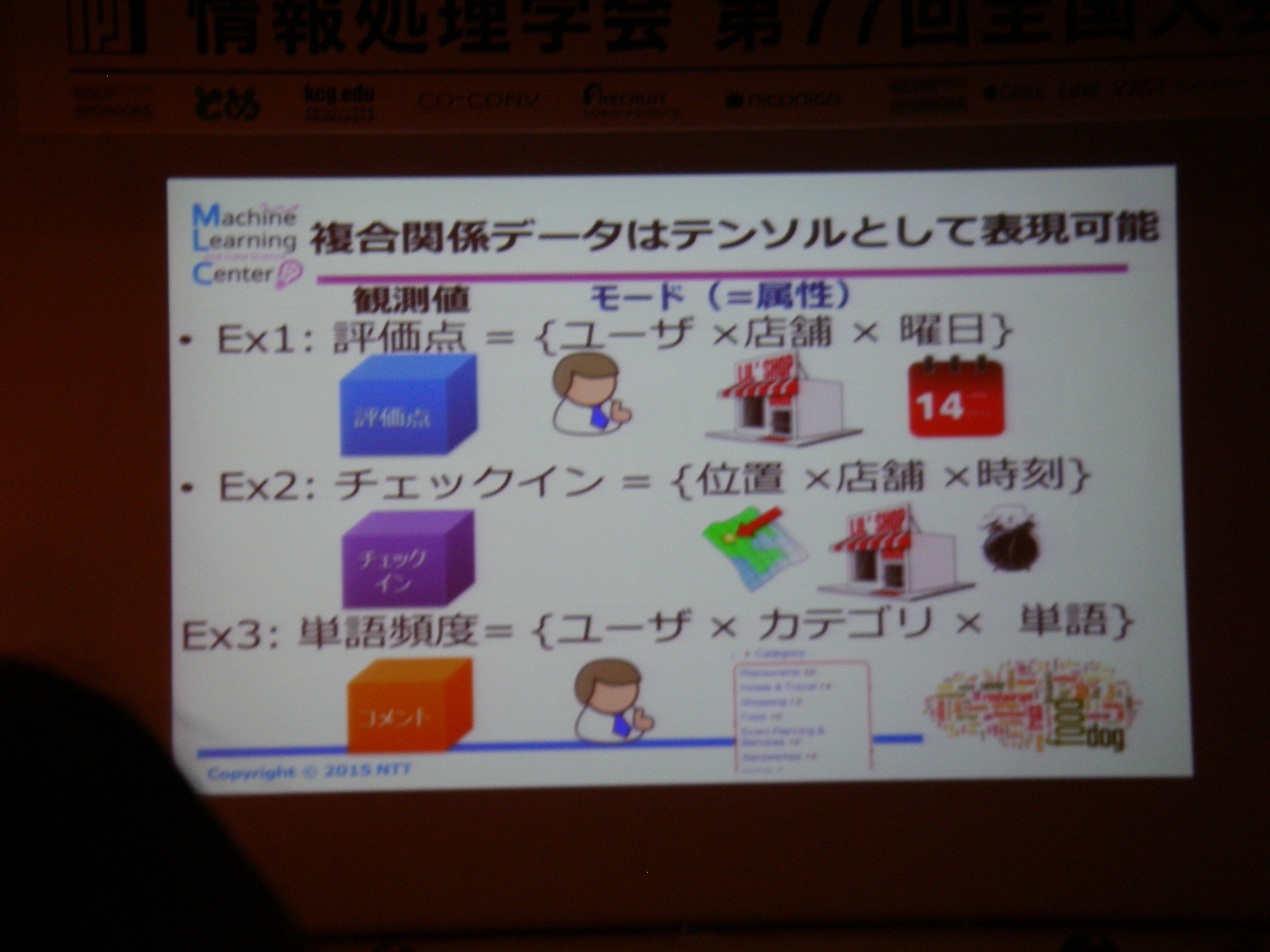
[サマリ的な何か] データがあること自体の優位性はまだあるが、期待されていることは技術ではなく、そのデータに基づいた価値創造であり、例えば新たな事業創造等どのような貢献ができるかが重要。従来の列挙モデルに比べ、統計モデルで仮説を立てる手法が盛り上がり、更にはノンパラメトリックなDNNが2010年頃から流行。これからの対象としては時空間統計解析が重要ではないか、とのお話。
機械学習・データ科学センタ(MLC)
NTT新中期: ビッグデータ解析による新価値創造->変革のenablerとして貢献
IoT, ビッグデータ
技術そのものへの期待ではなく、データに基づいた価値創造: e.g., 新たな事業創造機械学習
記憶するのではなく、汎化して新たなパターンへも対応する
列挙 vs. 統計モデル
列挙例: POS分析、相関ルール、アプリオリアルゴリズム、協調フィルタリング
確率モデル: 生成モデル(仮説)、潜在変数(隠れ変数)、パラメータ(ベイズでは確率変数)
相関ぐらいしか使わないモデルから確率モデルへの以降
関係データ解析: 共クラスタリング
確率モデルアプローチ: e.g., 観測データがどう生成されるかをモデル化予測と補完
重回帰分析: 変数選択が分析者の腕
非負値行列因子分解を応用
多次元データ解析: 複合非負値行列因子分解、非負値テンソル分析
DNNによる音響モデル予測・制御
時空間統計解析: 時空間多次元集合データ解析
時空間回帰:人流予測・制御
先行予測し、どう誘導したら混雑しないかをガイドする
学生セッション2Q: 言語生成とユーザ支援
URL: タイトル&アブスト一覧。

うちの学生が同じ時間帯に2カ所に分かれての発表となってたため、こちらには前半2件だけの参加。
日本語の語彙平易化システムの構築は、義務教育レベルへの表現/語彙に言い換える(検出&変換)という話。あれこれ公開されてる先行研究を組み合わせつつ、用意したデータセットで検証する限りでは7割強の精度で動いているらしい。デモがここで公開されてます。
神谷さんの小説検索システムのためのプロット作成に関する基礎研究へは、名大学生らからの質問・コメントがどしどし。後で卒研ノートの方に整理してくれるはず。
学生セッション2D: 認識・学習・最適化
URL: タイトル&アブスト一覧。

バナー広告に対する閲覧者の印象分類と自動印象推定に関する一検討は、広告内のテキストに対する印象を推定できれば広告作成者にとって嬉しいよねという話。ただ色んな影響が混ざり合っての広告だと思うので、テキストを独立して扱う(後で組み合わせる)というアプローチが良いのかは良く分からないかも。
玉城くんのDeep Learning におけるコストを考慮した Dropout率制御に関する検証も、後で卒研ノートに整理してくれるでしょう。
エントロピーとDP Matchingを用いたファイル類似度評価システムに関する考察は「バイナリの類似度を適切に計測できるようにしたい」というところから始めてるらしく、例えばハッシュ値を全バージョンで適切に管理するのは非現実なので「似たようなバージョンならバイナリで判別できた方がいいじゃん」とか。面白そうなんですが、具体的な応用イメージとして偽アプリ検出みたいなところを想定してるのはちょっと違うかなという気も。質疑で出てたLSAとの違いは?というのはその通りだよな。
人間活動と室内環境変化に対応した掃引システムの提案は、原則として環境にマーキングとかせずに、センサ情報だけで人活動を含めた環境変化に対応させたいという話。気持ちは分かるけど、実現するだけなら(完全自動化を目指すのではなく)もうちょっとインタラクション考えた方が良いのじゃないかなという印象。
京都大学第9回ICTイノベーション

URL: 京都大学第9回ICTイノベーション
タイトル見直すとてんかん発作兆候監視なんてのもやってたのか、見たかったor被験者申請したかったなw
並列言語Tascellによるグラフマイニングの並列化は、many cores上での並列化という話で、それなりに早くはなってるのだけどやっぱりグラフ展開上の都合というか作業分けしてる時点でのコスト差が大きいままタスクを分けちゃってるので、線形スケールにはまだまだという感じ。いや、十分早いのかもしれないが。
スマートポスターボード ―聴衆の反応のセンシング―は、Kinectと19-ch. Microphone Arrayぐらいのセンシング情報から「ポスター説明者+それらの聴者らの視線と相づちをリアルタイムで検出」し、それをベースに「興味や理解の度合い」を推定したいらしい。検出の方は割と精度高く実現できてるとのこと。Kinectデフォルトのモデルだとキャリブレーション必要なのに加え、差異が大きいとNGだったりするので、そうではなくてリアルタイムにそのユーザの3Dモデルを構築し、顔の向きを推定してるとのこと。キャリブレーションも不要だし、一度構築できれば真横向いても問題無いという。おおー。ただしリアルタイム処理するなら、1ユーザあたり「5~6万ぐらいのGPU1個」ぐらいが必要らしい。会場でも廃熱追いつかないのでPCのカバー開けてましたw
認知構造のビジュアル分析システムE-Gridは、多人数へのインタビュー結果における「重要な部分」をうまく可視化したいという話。テキスト等の処理はユーザ側がする必要があるらしいが、可視化の例として面白そう。E-Gridとして公開されてるらしい。
デザインスクールの展示(コンソーシアム、サマースクール)もあったようですが、途中からの参加だったこともあって時間内に見れず、残念。


お食事



例によってというか昨日の時点で良さげな候補がまだあったのでポルタ地下街でだし茶漬け えんへ。店内にsoup stockな文字があったけどその系列?あっちが大好きなお店だけあってお茶漬けも旨し。すぐお腹減るだろうということで持ち帰りでおにぎりをゲット。