Archive for the ‘日記’ Category
そろそろ前期終了
土曜日, 8月 10th, 2019プログラミング1を担当し始めて4回目。課題設計はまだまだ試行錯誤の余地大きいですが、授業全体の流れは固まりつつあるかな。毎年見直してて特に今年は大きめに変えてますが、それでどうにか落ち着いた感じ。
授業評価アンケートを見る限りでは、基本的には書いてくれてる人は「難しい」「達成感はある」「予襲復讐の必要性を感じた」みたいな感じらしい。
今回は課題を難しめに用意して「最後までやれなくても良いから取り組んだ過程を書いてくれ」という形でやってみたのですが、やっぱりそう簡単にはうまくいかなくて。他人のレポートを読んでみて良いとこチェックしてみるとかもやってみてますが、これも何度も繰り返してみないと「報告書として何を書けばよいのか」が身につきにくいのだろうな。もう少し丁寧にレポートに対するレビューしてあげられれば良いとも思うけど、簡単すぎる課題の場合には「過程も何もやった内容を使って実装する」ぐらいで、難しすぎると「そもそもどう取り組むかが思いつかない」学生が多いらしい。
道具は提示しつつ、その組み合わせで考えてみてという話をしたり。
実際に問題を分割して考える例を示してみたり。
最初から小分けされたものを実装して、まとめあげてみたり。
腑に落ちる学生もいますが、落ちない学生がゼロにはならないですね。
仕方ないのかもしれないけども。
Q4.この講義で補助教材は役に立ちましたか?
(※ここでの『補助教材』は、「シラバスにある参考書、または参考図書、授業中に配布されたプリント、配布データ、サンプルプログラム、サンプルソースなど」を指しています。配布物はオンライン配布(講義のページからなど)のものも含めます。)
毎年のことですが、上記に対する回答で「補助教材がなかった」と回答する人いるし、、。
実験3・データマイニング班の発表会
水曜日, 7月 31st, 2019明日になりますが、データマイニング班の発表会があります。興味のある人はどうぞ〜。
日時: 8/1(木), 3限目
場所: 地創棟508Group 1: LinearRegressionを用いたアニメタイトルの略語予測
概要: アニメのタイトルなど様々なものの略称には何かしらルールがあるものと仮定する。我々は略前略語のタイトル群を教師データに、主に回帰分析などの様々な機械学習手法を用いてその法則性を発見することを目的としている。さらに略前のタイトルから、これから略されるであろう略称を予測し提供することを最終目標にしているGroup 2: インスタ映えする画像の判別機
概要: インスタグラムユーザがよく使う「インスタ映え」を投稿された画像から推定し,インスタ映えする画像かどうかを判別するモデルを,CNNを用いて作成する. 「インスタ映え」を満たす要素を判別するモデルを個別に作成し,それらのモデルを用いて, 入力画像をクラシフィケーションする。Group 3: バズりやすい動画の予測分析 ( YouTuber編 )
概要: YouTubeにある動画の中でヒカキンTVがどのような動画でバズるのか予測分析する。回帰分析や決定木を用いてバズるための特徴量を探し、その特徴量が多く含まれるジャンルの動画はどういったものかをクラスタリングする。Group 4: ポケモン画像のタイプ分類
概要: ポケモンの画像とそのポケモンのタイプを学習させることにより、与えられたポケモン画像のタイプを判別することを目的とした。CNN を利用し、多クラス分類や多ラベル分類、クラスタリング、ランダムフォレストまたデータ数が十分でなかったため交差検証、データ水増しを行った。これらのことからポケモンのタイプ判別に対して、どの手法が適しているかを検証した。
分解して組み立てる
金曜日, 7月 19th, 2019大辞林で「構造」を検索した時の説明文がこれ。
① 全体を形づくっている種々の材料による各部分の組み合わせ。作りや仕組み。 「機械の-」 「耐震-」
② さまざまな要素が相互に関連し合って作り上げている総体。また、各要素の相互関係。 「社会-」 「精神-」 「物質の-」 「文の-」 「汚職の-」
プログラミング1や、赤嶺先生の演習1で何度も出てきているキーワードの一つが構造化。対象をどういう機能に分解できるのかを考え、その機能を一つずつ作り上げていく。
最初から綺麗に分解できるとは限らないので、間違っても良い(後で使わない事になっても良い)からまずは「何かしらの一つの処理を実現する機能」に分解してみて、それを確認するための簡単なテストを用意し、テストが通るように実現する。
想定通りに動かないなら、使ってるライブラリのドキュメントを参照したり、デバッガを利用して、「何故こう動いているのか?」を明らかにしよう。
まずはテストが通ることを最優先し、バージョン管理。バージョン登録することでいつでもそこに戻れるようになる。余裕があればその動いたコードを俯瞰して、「よりうまい機能の切り出し方がないか」、「似たようなコードが散見していないか」等の観点から、見通しの良いコードを目指してみよう。
関数名・変数名等の命名規則や、ドキュメントも適切に用意することでコードの読みやすさが向上する。
みたいな話を14週かけてやってきました。残す所あと1回。
GPU稼働状況
水曜日, 7月 3rd, 2019さくらGPUサーバ: [ ざっくり確認 ]
6月に入った辺りから利用希望者が出始めて、お試し的にやった学生や、実際に研究の一環として一度の実行に長時間(1回あたり1週間以上?)要するような利用まで出てきました。GPUの稼働率(GPUと内部メモリ)と、GPUの稼働率とをグラフ化するとこんな感じになりました。
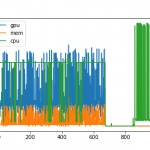
横軸のメモリは、1単位あたり10分。10分刻みでvmstat, nvidia-smiで稼働状況を記録。
縦軸は、稼働率(100%上限)です。
GPUはTesla P100。青い線がGPU稼働率で、オレンジがGPUメモリの稼働率。
CPUは緑色で、E5-2623V3 (3.0GHz, 4C/8H)が16個搭載されてます。これがフル稼働で100%。
これを眺めると、2パターンの利用があって、
(1) 700手前までの前半は、GPU 50% (メモリ15%) ぐらいで稼働し続けていた。
(2) 後半は、CPUだけで70%強稼働し続けていた。
らしい。
(2)でGPU使われていないのが不思議なんですが、学生に確認する限りでは pip で tensorflow-gpu をインストールしたらしいし、実際 pip list で確認してもそうなってるらしい。ので、インストールの仕方によっては gpu 版入れてたつもりでも、GPU使わないことがあるらしい。あらまぁ。
テスト駆動開発≒モデルの入出力を明確にして考える
金曜日, 6月 28th, 2019プログラミング1でユニットテスト(doctest)自体は既にやり終えてましたが、復習も兼ねてもう一度。関数単位での動作確認をしやすくするため、使い方例示のため、といった振り返りをしつつ、今回はテスト駆動開発のお話も。
実際にはいくつかの要素を組み合わせて振り返ってるので、だいぶ時間が。
- まずテストを無視してシンプルな関数を書く。
- その関数を実行するコードを書いて動作確認。
- そのスクリプト1を別ファイル2からimportした時の動作確認。
- その理由を確認するためにbreakpoint指定してデバッグ実行。
- 特殊変数の確認と、これがimport時と直接実行時とで中身が変わっていることを確認。
- 元のスクリプト1を、__name__で動作変わるように修正。
- スクリプト1をimport時の動作と、直接実行した場合とでの動作の違い確認。
- doctest追加して、テスト実行。
- 関数を拡張して、2要素を返すように修正。戻り値がtupleになってることを確認。
- tupleに合わせてテストを修正。スペース有無含めてstr型での判定になっていることの確認。
ぐらいの内容で、ユニットテスト+import+関数戻り値を確認しつつ、新しいtuple型の説明までをまとめて実行。ユニットテストがあるとドキュメントを補足する例示にもなるよと。
それを踏まえて、同じ関数を「最初はコードを分からないものとし、最初にテストを書こう」ということでテスト駆動開発の話へ。
- 実現したい関数の入力と出力の組を1例考え、テストとして記述する。
- そのテストが通るような実装を書く。
- そのコードでは通らないような別のテストを書く。
- 以下繰り返すことで、少しずつ一般化していくことを考える。
みたいな演習。
テスト駆動開発がベストだとは思わないけど、モデルの入出力を明確にすることでそもそも何を実現したいのかを目に見える形にする、という点では間違いなく有用だよね。
Jupyterが正義という訳でもない
木曜日, 6月 27th, 20193年次の学生実験は、教員一人あたり数人〜10数人程度での実施になることが殆どなので、その分細かい指導がしやすくて。データマイニング班前半はこんな感じで、授業寄りの基礎演習をやってて、後半はグループ単位での開発実習をやらせてます。
これも単に「やってて疑問に思う所あったら聞いてね」とか、「たまに見て回る」ではなく、進捗確認を兼ねた作業レビューをしています。ここでいう作業レビューとはペアプロとかモブプロに近いもので、大型モニタに接続して貰った状態で、内容確認しながら作業してもらい、その様子を見て気になる点へアドバイスし、実際に一緒に問題発見してみたり、修正してみたり、場合によってはググり方とか考え方を提示するに留めて考えさせてみたり、といったことをやっています。
ここ数年でよく見る宜しくないパターン(=Jupyter広まってから増えてるパターン)は、
- デバッガを使うことを意識していないケースが少なくないこと。
- Jupyterで書いて、後でライブラリとして使うように整理し直すことをしないこと。(毎回そこからコピペでその後も作業しがち)
- Numpy/OpenCV/TensorFlowとか便利なライブラリ使いつつ、ドキュメント参照しないこと。(怪しい解説記事を鵜呑みにしがち)
かな。関数の戻り値が何なのか分からないまま、に使ってるとかありがち。
printデバッグが多いとか、ググる際のキーワードの不適切さ(バズワードだけで検索するとか)は昔からか。
そういうのも含めて、実際に目の前で見ながら指摘してあげることができる時間ですね。プログラミングに限らず、こういう「実際の過程」に対するレビューというのは、一子相伝じゃないですが、それなりに価値があることだと考えているので、やめるつもりはありません。
私の指摘事項が古くなるという側面はありますが、、(遠い目)
Pythonコードのデバッグ(Thonny -> PyCharm -> Thinking)
金曜日, 6月 21st, 2019例年だと、Thonnyという「初心者向けIDE」を使ったデバッグ実行に、PyCharmでのデバッグ実行(breakpoint, step into, stackframe確認とか)ぐらいで終わってました。それでも前期の間に2回取り上げているという話でもあるけども。
今年はこれに加えて、PyCharmによるデバッグ演習2で、「マニュアル見よう、エラー文解釈しよう、デバッガから得られる情報から推測しよう、処理対象を小さくしよう、最小限のコードで再現してみよう」というデバッグ・シンキングな演習もやってみました。
step intoとか breakpointぐらいの操作は別例でやってます。それでも一回では慣れない部分もあるし、それ以外にも「そもそも要因を発見する、特定する」ための考え方やアプローチが一杯あるよねと。同じ例題に対していろんな視点から取り組んでみることでより豊かな考え方が得られるかなと、じっくり時間かけてやってみました。去年まではここまではやってないのだよな。
さくら高火力(GPU)
木曜日, 6月 13th, 20195月末に設定してから、実際に使う人が少しずつ出始めました。現時点でのアカウント保持者は6名で、たまに稼働状況見る限りでは何かしら動いてます。ガンガン使ってください。
topコマンドでCPU稼働状況見る限りではほぼ800%。E5-2623V3なので、これが2つフル稼働。
top - 20:02:51 up 20 days, 6:57, 2 users, load average: 6.63, 6.88, 7.12 Tasks: 238 total, 1 running, 237 sleeping, 0 stopped, 0 zombie %Cpu(s): 47.4 us, 3.1 sy, 0.0 ni, 49.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 13190941+total, 72995144 free, 10503812 used, 48410460 buff/cache KiB Swap: 4194300 total, 4194300 free, 0 used. 12002012+avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 13269 k198572 20 0 31.0g 9.4g 657772 S 805.6 7.5 37503:01 python
ちなみにメモリは平均7〜8%。めっさ余ってるというか、そもそも実装されてる量が桁違いに多い、、。
(base) [tnal@localhost ~]$ free
total used free shared buff/cache available
Mem: 131909416 10476416 73023776 473208 48409224 120048048
Swap: 4194300 0 4194300
GPUは、nvidia-smiなんてコマンドで稼働状況確認できるらしい。おおよそ27%なので、まだまだ余裕あるっぽい。これはプログラムにも依存するでしょう。
(base) [tnal@localhost ~]$ nvidia-smi -l
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 13269 C python 2565MiB |
+-----------------------------------------------------------------------------+
Thu Jun 13 19:38:13 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.67 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:02:00.0 Off | 0 |
| N/A 47C P0 50W / 250W | 2575MiB / 16280MiB | 27% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 13269 C python 2565MiB |
+-----------------------------------------------------------------------------+
上記のことを踏まえると、Tesla P100ぐらいのを使うならもっとそっちよりの実装を頑張って貰わないとあまり効果が期待できないということかしら。
目的の記事にたどり着けるとは限らない(news-ie)
水曜日, 6月 12th, 2019news-ie投稿の公開方法ということで、
・過去のものはデフォルト非公開。
・今後はデフォルト公開。
・閲覧範囲として学科(コース)指定できるように。
なったらしい。
昔々は、NetNewsで情報共有なりしていました。fj漁りしてた頃だな。
今のWordPressのカテゴリーに ura.ie.announe とかあるのは昔の名残りですね。NetNewsからWordPressに移行したタイミングだかでデータ含めて移行してた気もしますが、今遡ると2008年12月18日なので、記事以降まではしてなかったor諦めたのかも。
当時は「すべての科目に一つのニュースカテゴリ」を用意してて、科目毎にそこで周知なり質問相談なりしてました。今でのカテゴリありますが、殆ど指定されずに記事流れるので学生からすると探しにくいのかも。一方で、RSSなりTwitterなり、今ではSlackへも連携してたりするので、チェックする癖をつければ一通りは目にできるとも思います。が、そうしてない学生は多いのだろうな。
キーワード検索しても良いけどそうせず単に遡って探そうとしてる学生もみかけますが、これは探し方がわからないというよりは、キーワードが思いつかないのかもしれない。科目名省略されてるとか探しにくいことあるのも事実だし、イベントの類いだとそもそも正式名称知らずに探すこともあるし。イベントカレンダーなりあると良いのかも。
もうちょい便利な検索支援ツールがあるのが現実的かなとも思ってるので、研究室の学生にはそっち方面をテーマにしないか突っついてみてますが、今の所反応は半々かな。