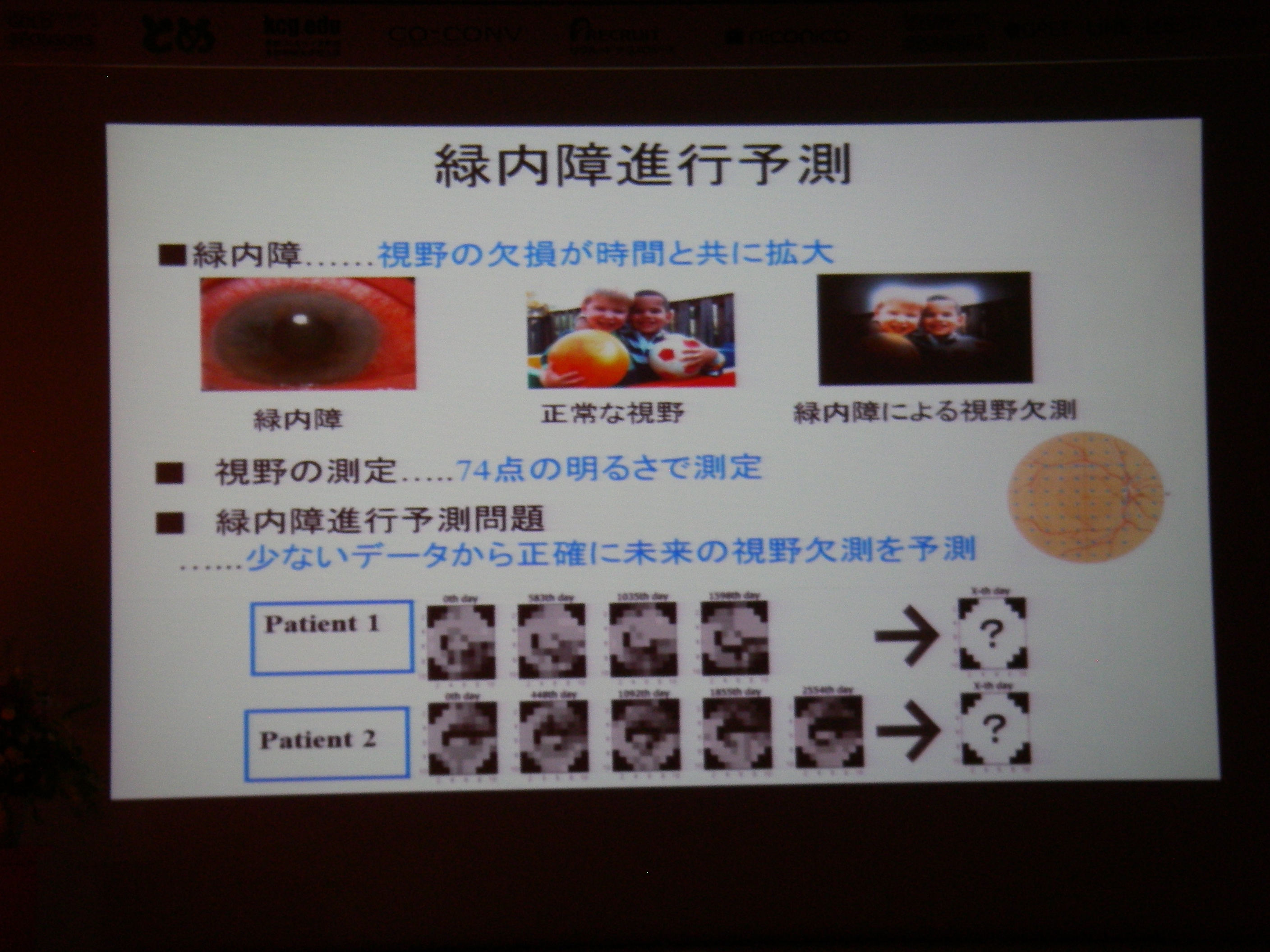
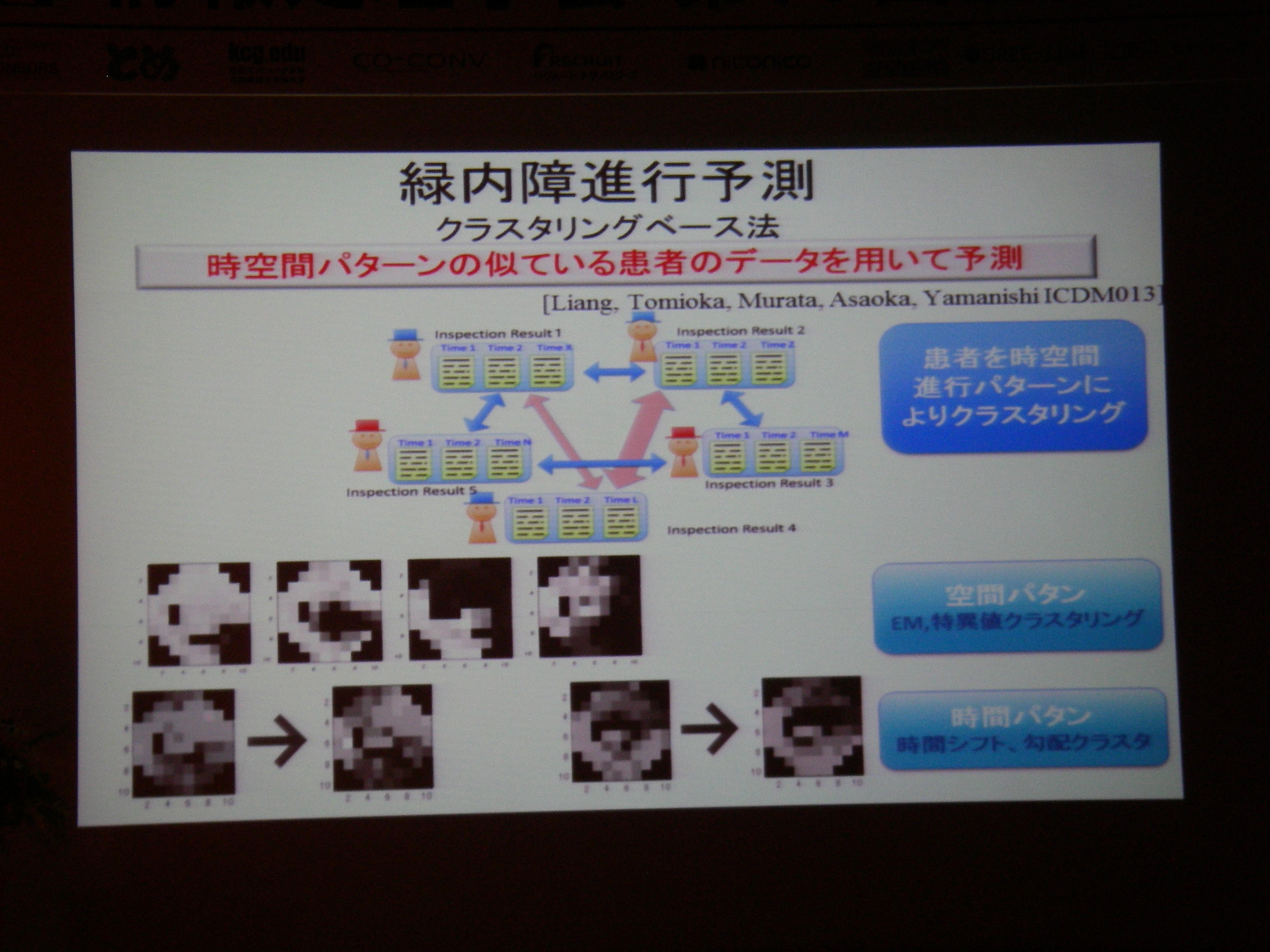
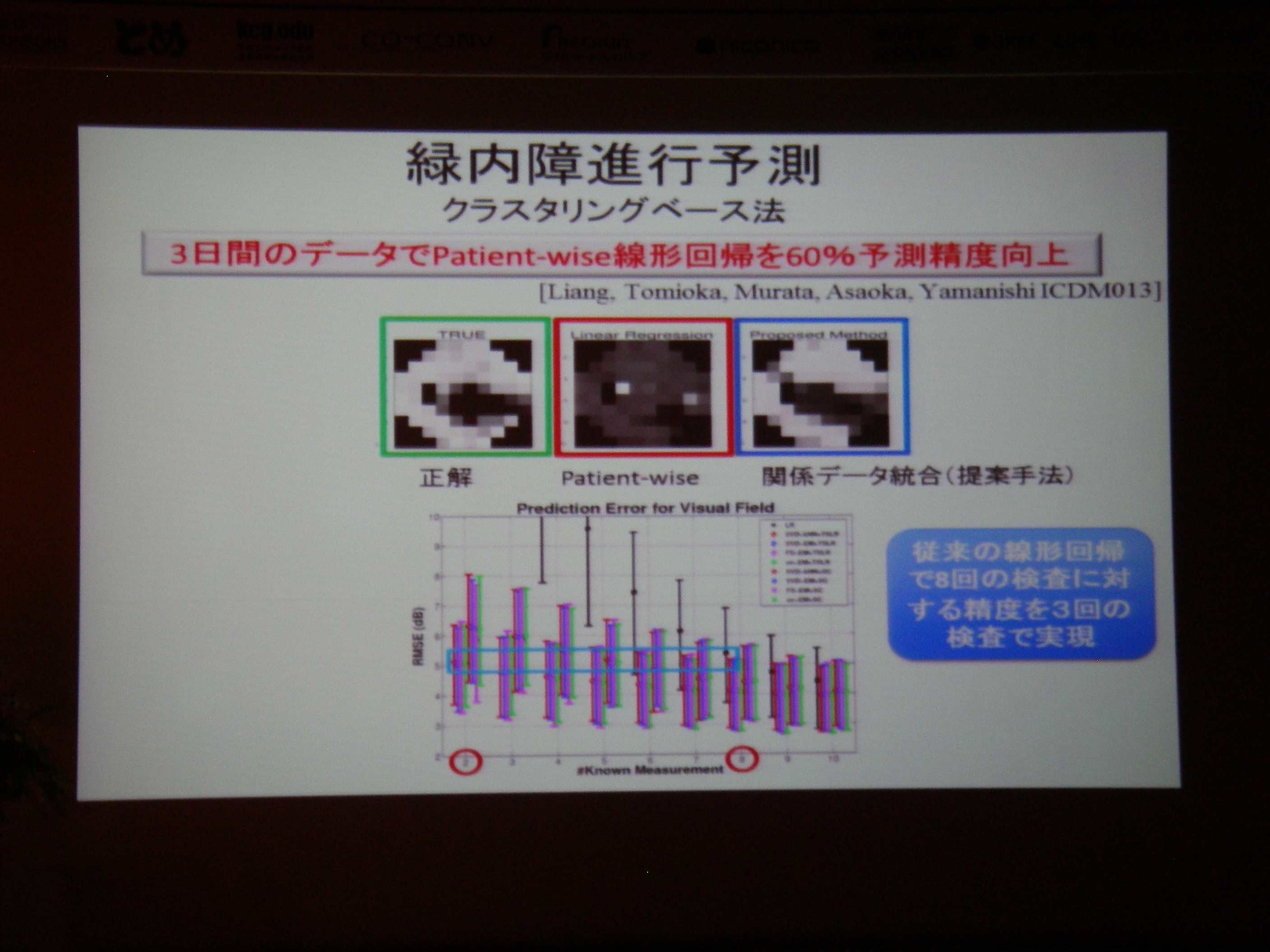
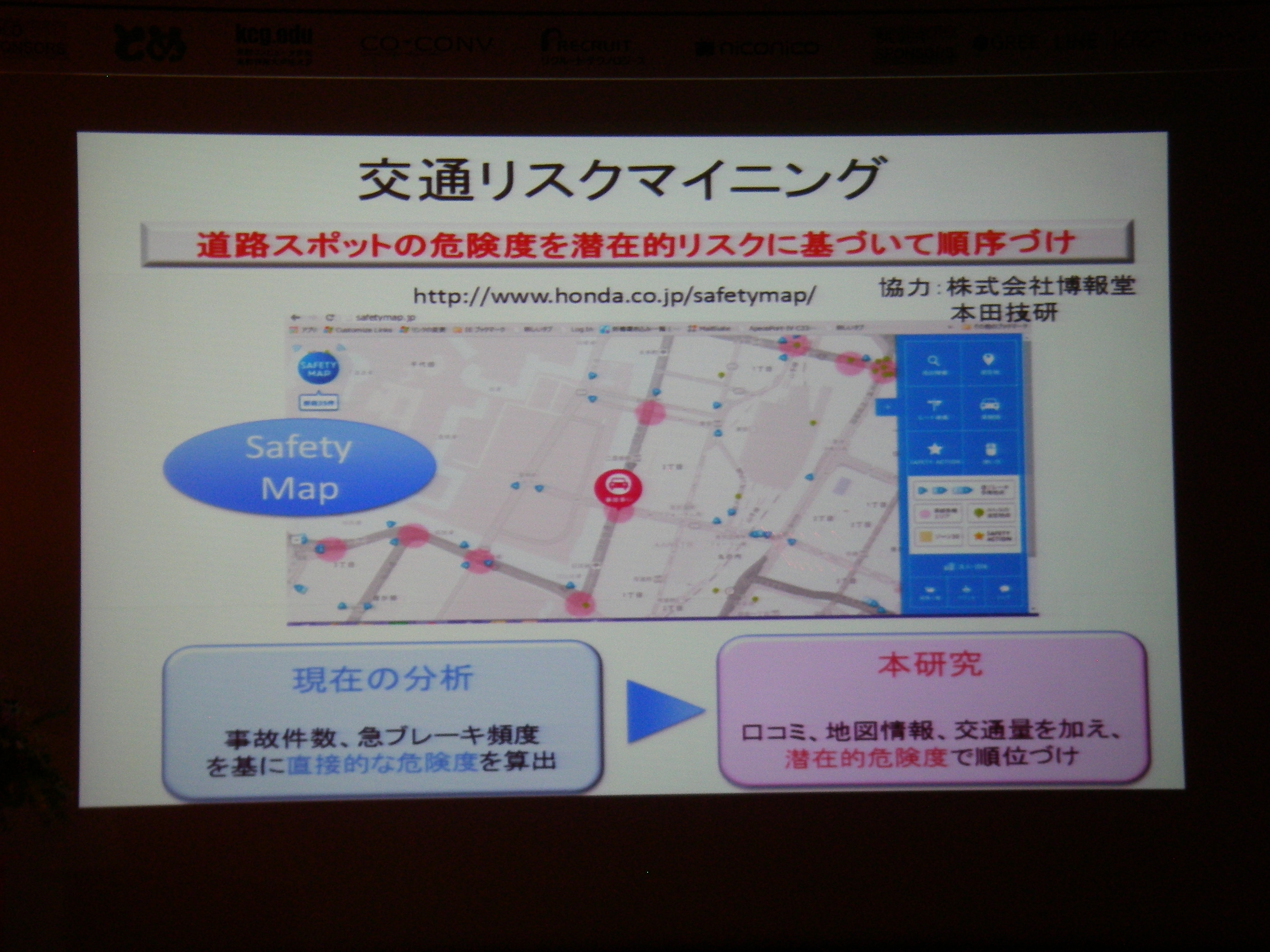
京都出張4日目(情報処理学会第77回全国大会 3日目)
木曜日, 3月 19th, 2015今日も雨模様でやんわり冷えてます。雨自体は昨晩から強くなってきてて、今朝も強いまま。しくしく。



総合受付や第1イベント会場等は100周年記念な時計台にあります。ホールとかラウンジに飲食物持ち込み禁止なのは別に良いんですが、ラウンジで専属のバーテンダー(?)がいたりして驚く。あちこちにモノだけじゃなくヒトに費用かけてるよな。正門に受付いるし、中入ってすぐに(交通量が多いわけじゃないけど)交通整理する人いるし。一般道に面した建物が多いこともあって、そういう所にはさりげない広報もされてたりして面白いです。琉大だと「そもそも歩いて通る人少ないし」とか言いそうだよな。事実その通りでもあるし。その一方でイベントとしての会場案内(掲示)については個人的に参加してきたなかではかなりレベルが低いという、謎のギャップが。開催してる建物の入り口まで辿り着いても掲示が無いとかざらだったし。
<目次>
- オリンピックに見る日本のICT技術
- 講演(1) 選手,コーチをサポートするICT技術(映像システム編)
- 講演(2) スポーツ用義足の研究開発とアスリート支援
- 講演(3) 選手を育てるICT技術(陸上競技 競歩編)
- 特別講演(2)官民が協働で推進する新しい海外留学支援制度について~「トビタテ!留学JAPAN」日本代表プログラム~
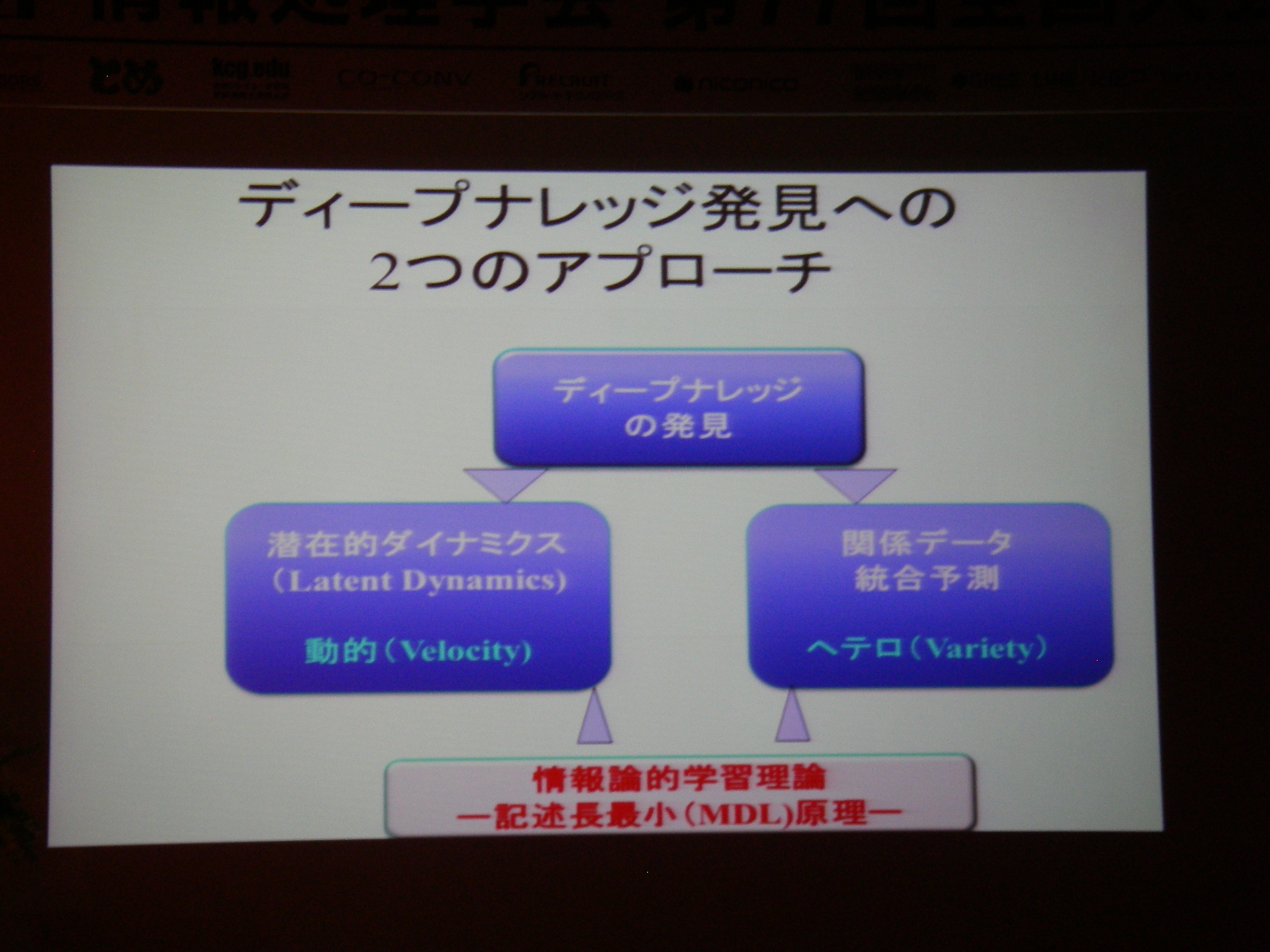
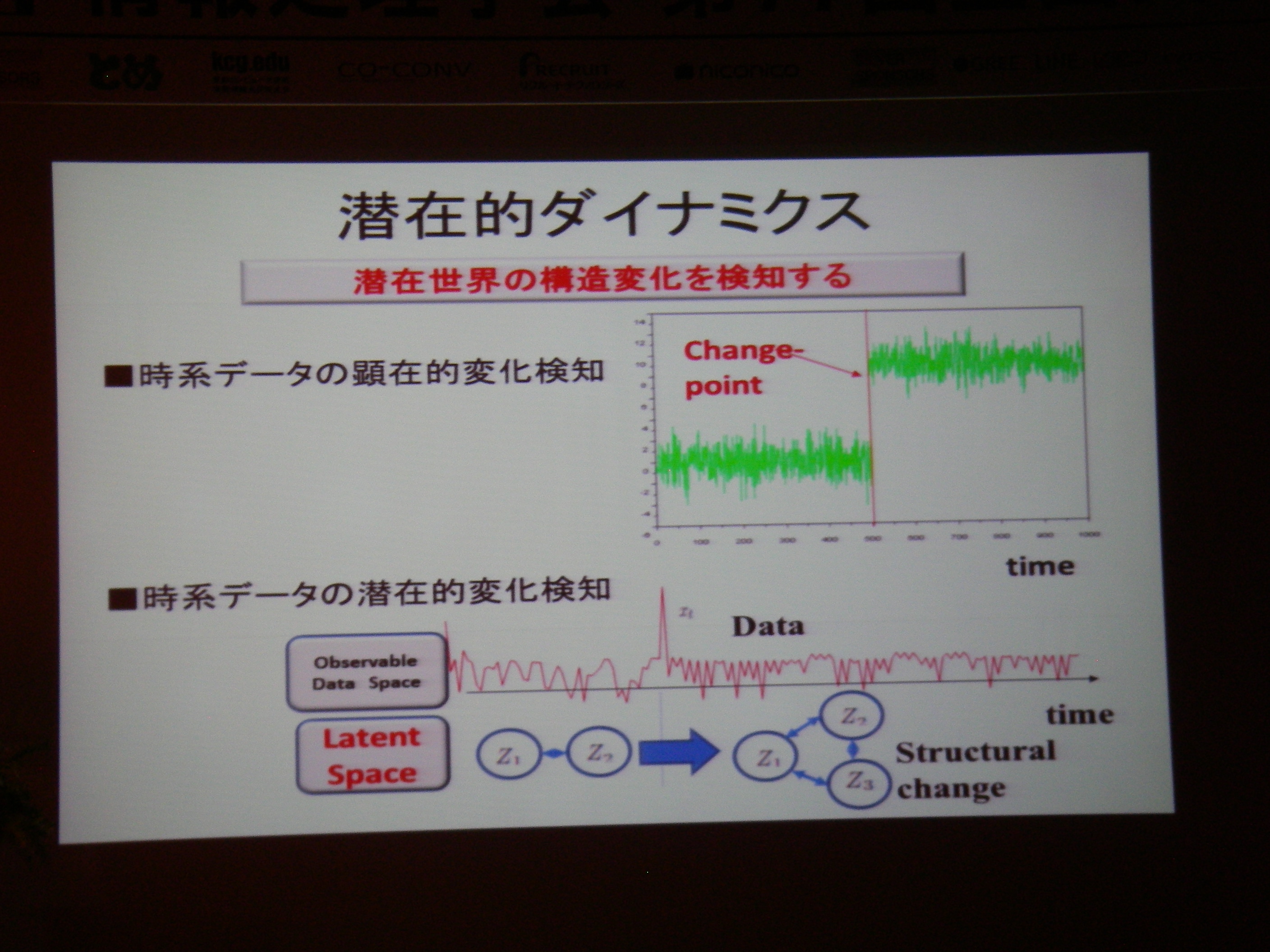
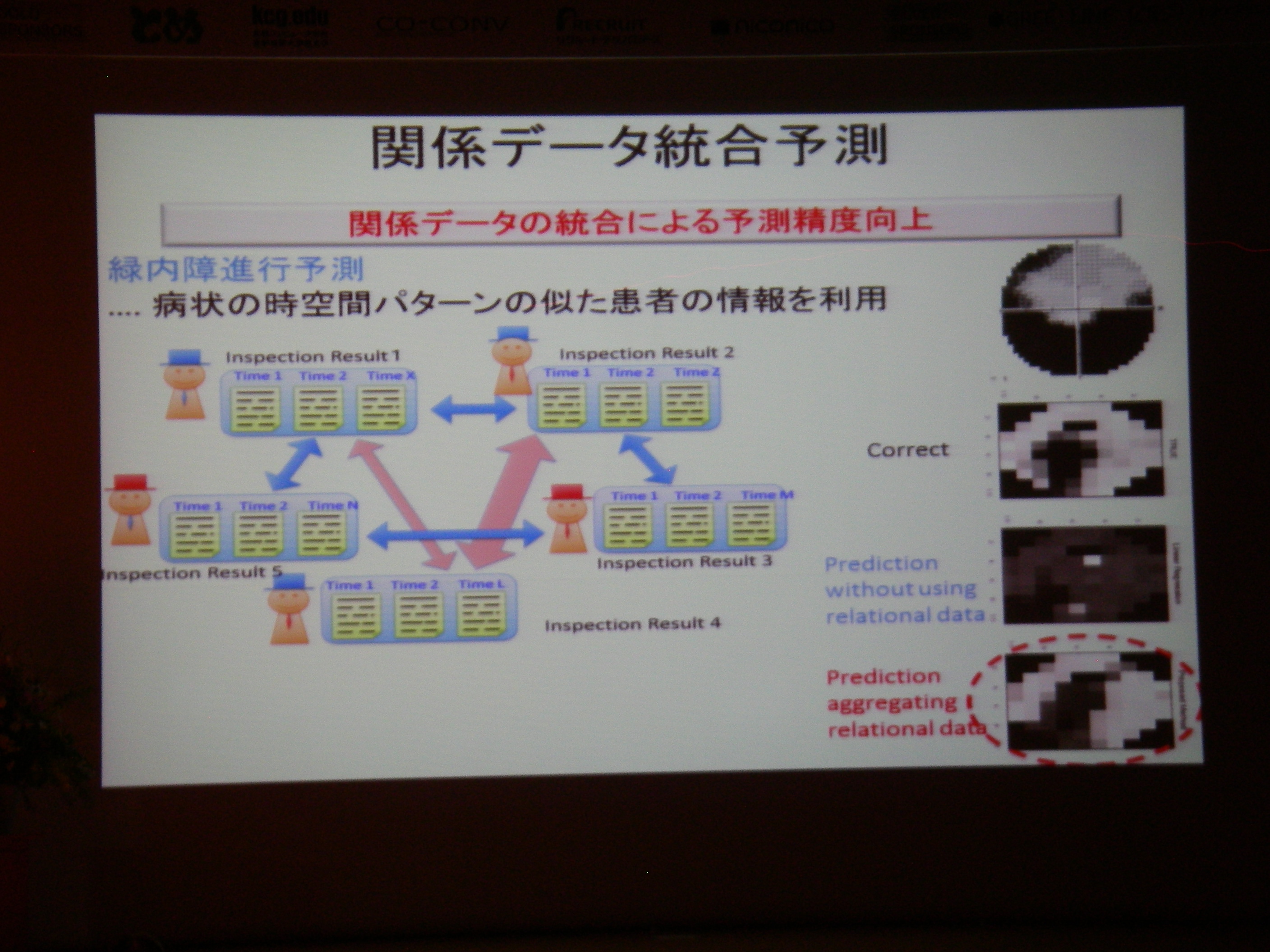
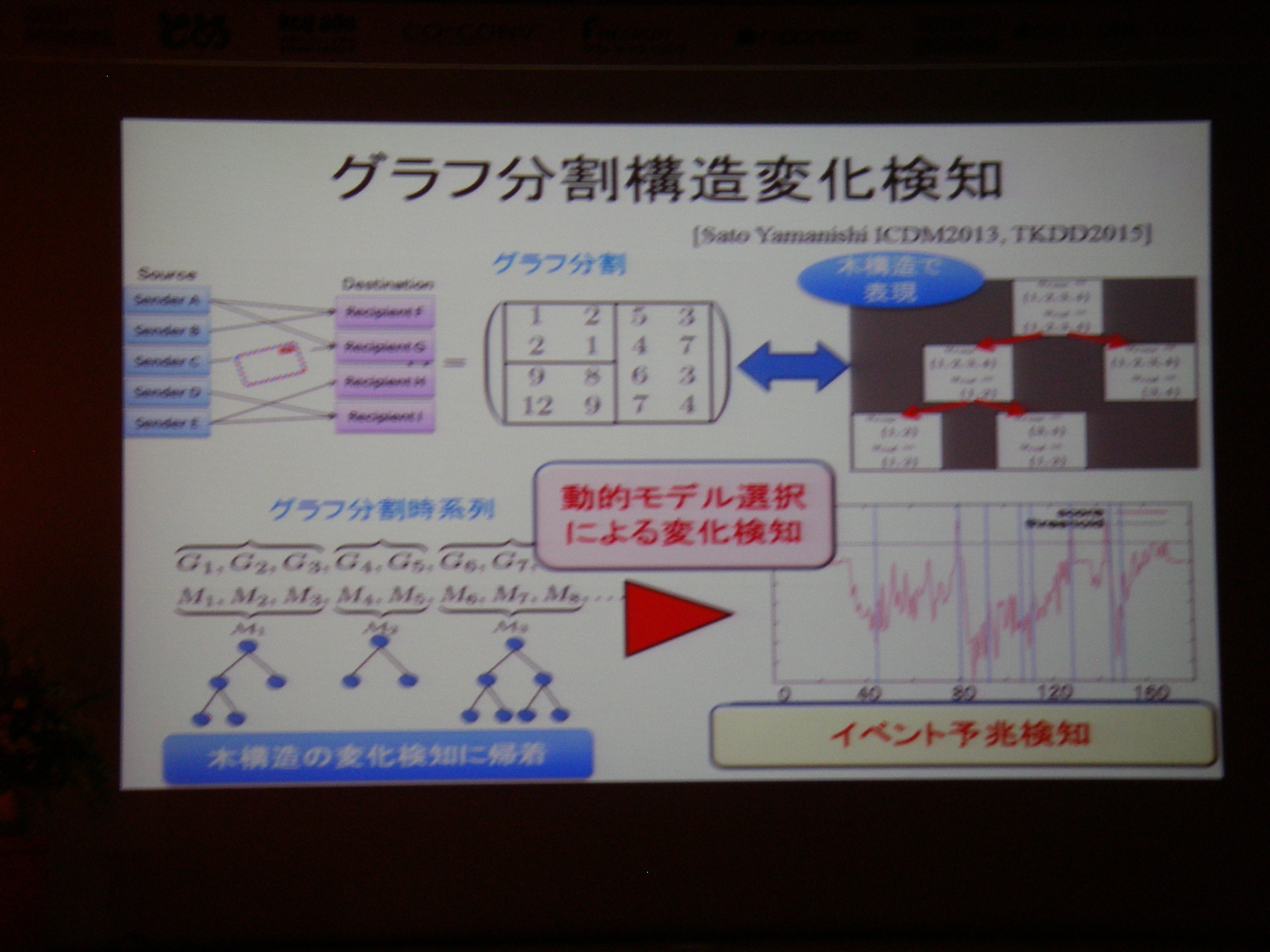
- 招待講演(5)情報処理技術を用いた脳の情報の解読と制御
- 学生セッション[6M会場] 情報推薦
- 学生セッション[6P会場] 対話システム
- お食事
オリンピックに見る日本のICT技術
1件目はどちらかというと収録+即時フィードバックのためのインフラを中心とした話(分析もしてるようだけど、発表ではほぼ割愛)。2件目はトップアスリートの分析に耐えうる高精度な分析しようとするとモニタリングだけで高コストすぎるのを、YouTube動画でどうにかしようという話。3件目は両方に跨がった事例紹介かな?(途中で抜けてしまった)。オリンピックに直結したプロジェクトも多い中、メイン会場で開催してる割には聴講者ガラガラでした。2件目保原先生の話が面白い。
講演(1) 選手,コーチをサポートするICT技術(映像システム編), 三浦 智和 (独立行政法人日本スポーツ振興センター 国立スポーツ科学センター スポーツ科学研究部 専門職)


後半しか聞けてないですが、トップアスリート支援で必要な高精細録画を「現場」で収録&即時フィードバックするための環境整備自体のコストがまだ高くつくという話。なるべく機材は小さく&軽くしたいとか、iPadとかとの連携も不可欠とか、アスリートが事細かに覚えていられるのは30秒ぐらい(?)で、現時点では収録したのを送信するのに40秒ぐらいかかるとかとか。
スキージャンプ
今後の課題: インフラ、機器
ウェイトリフティング
スーパスポレコ: フルハイビジョン対応の映像遅延再生システム
フォーム即座に繰り返しチェックできる
競技現場にマッチするシステムとは?
ニーズを実現するという大前提に加え、普段のトレーニングで活用できるシステム
現場だけで活用できるシステム(機材チーム不要)
映像+情報も合わせて即時にフィードバック
ウェアラブルもあるがトップアスリートには精度の問題も
講演(2) スポーツ用義足の研究開発とアスリート支援, 保原 浩明 (独立行政法人産業技術総合研究所 デジタルヒューマン工学研究センター 研究員)
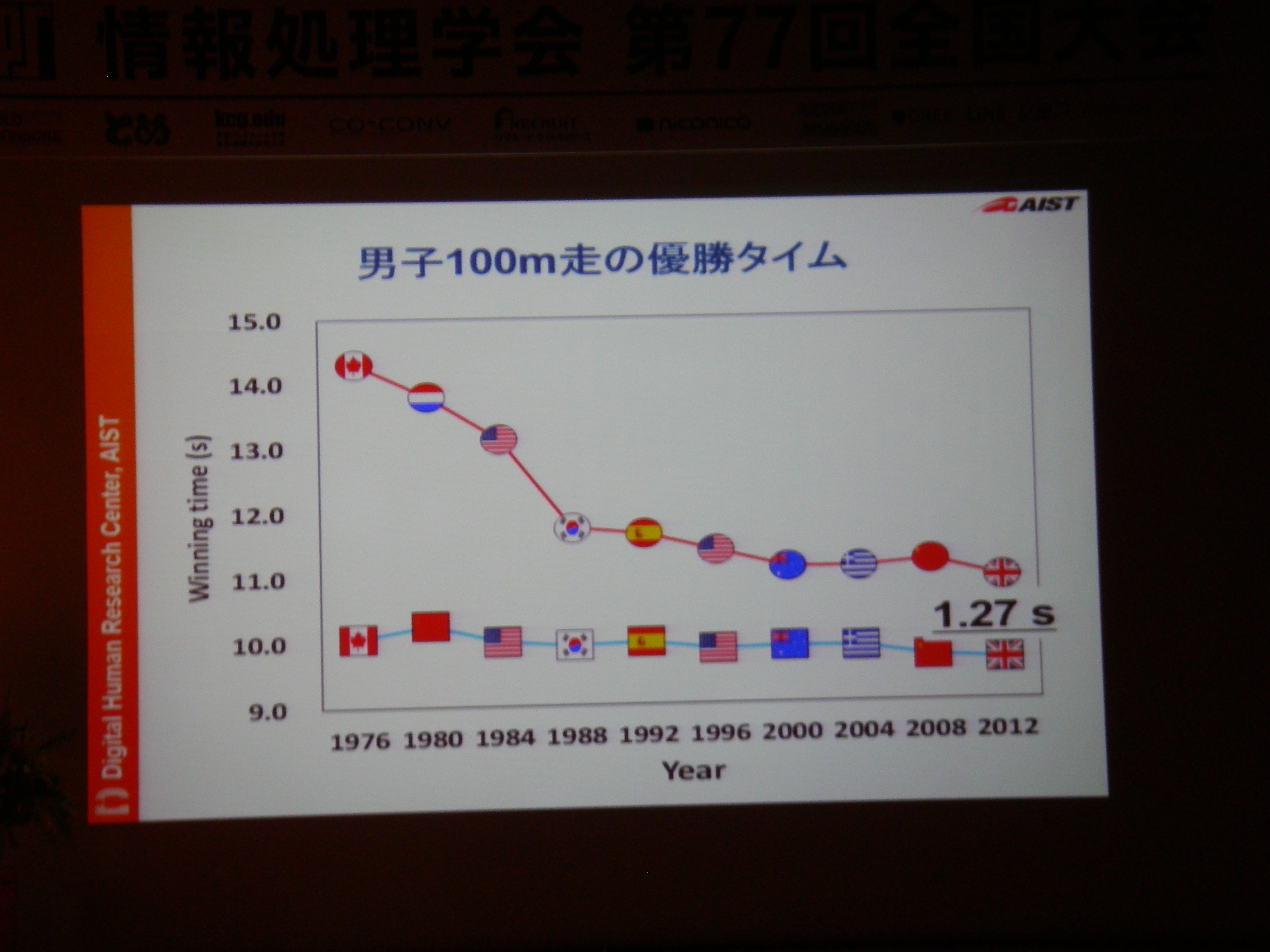



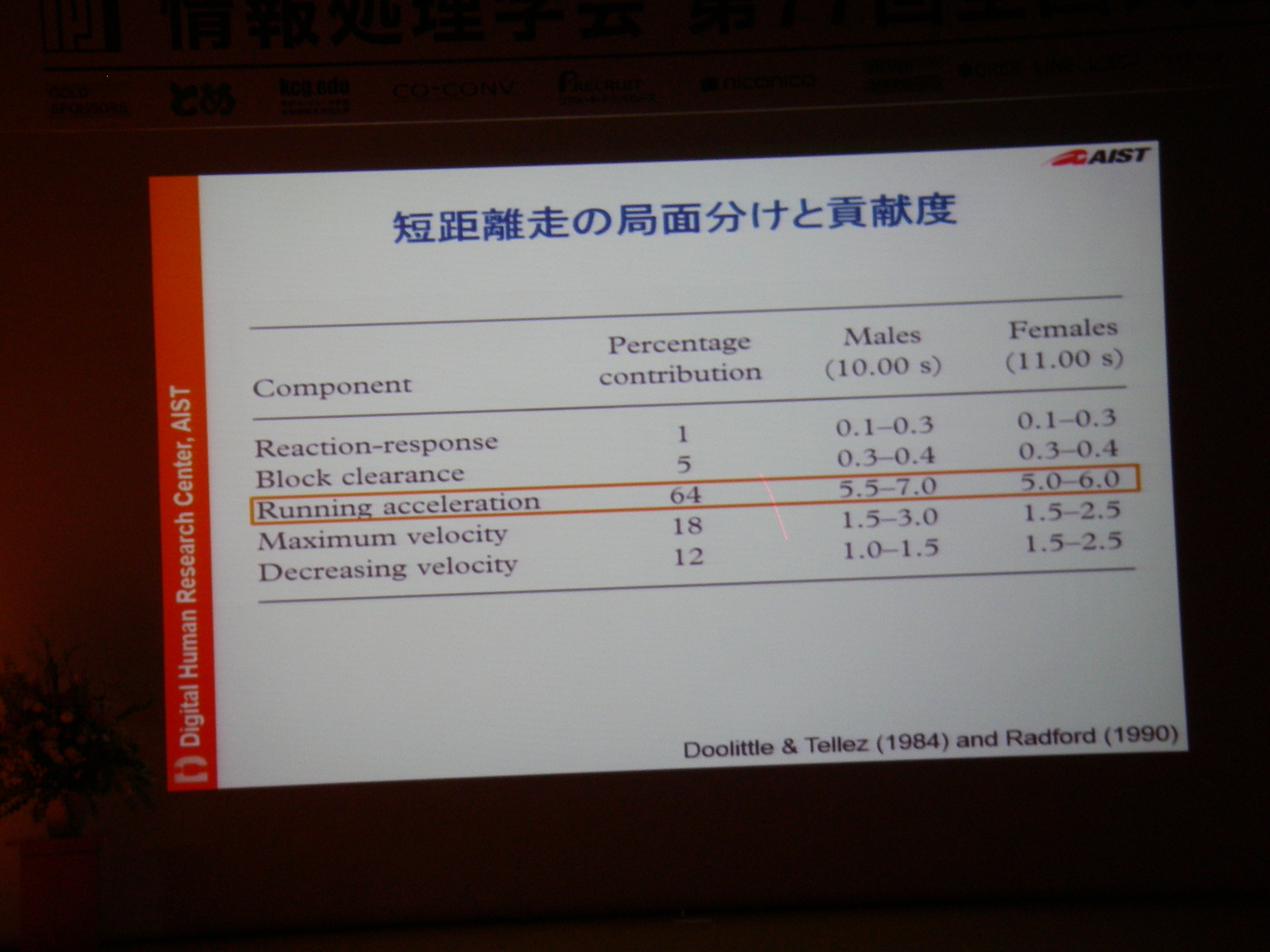

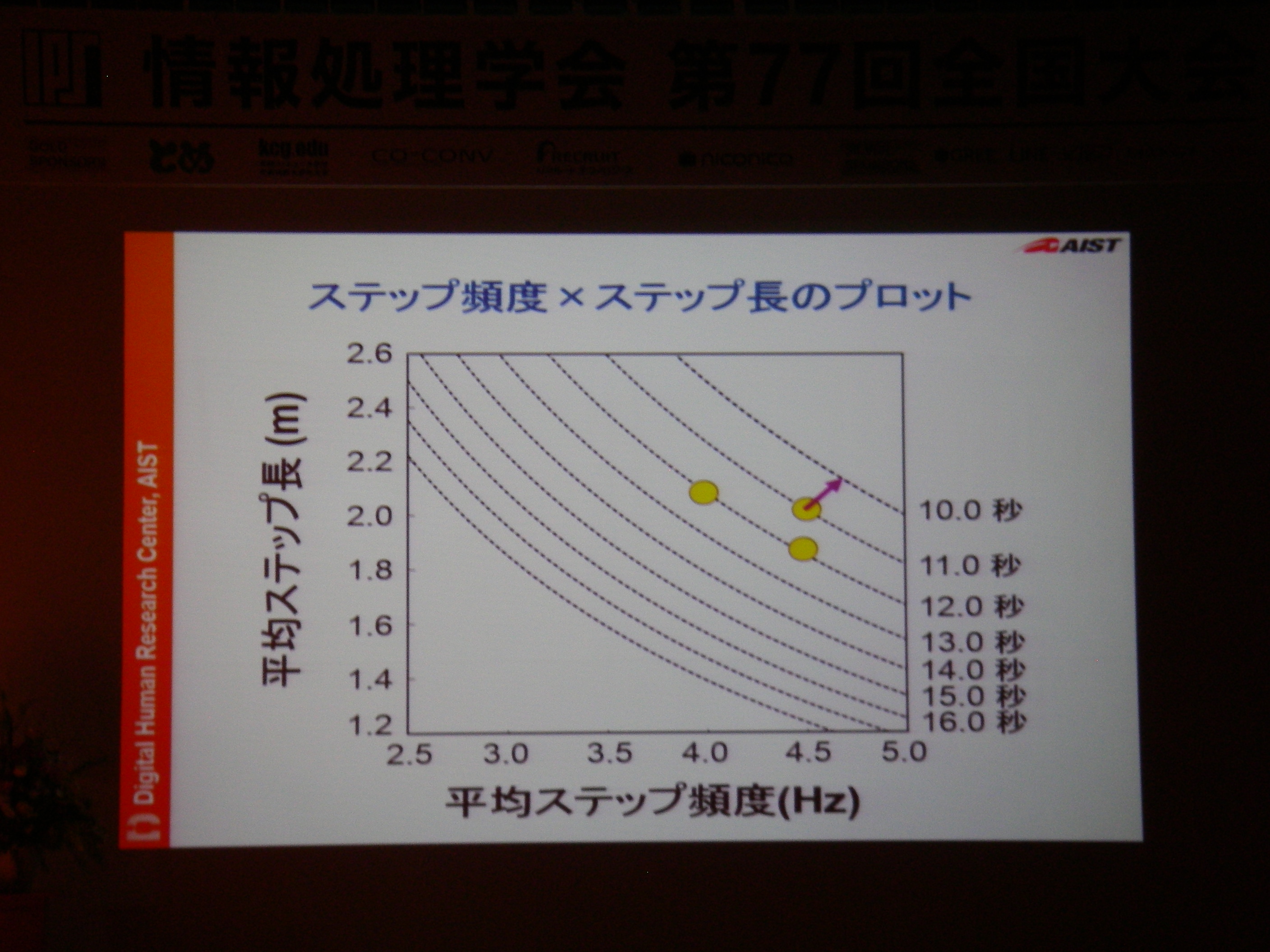
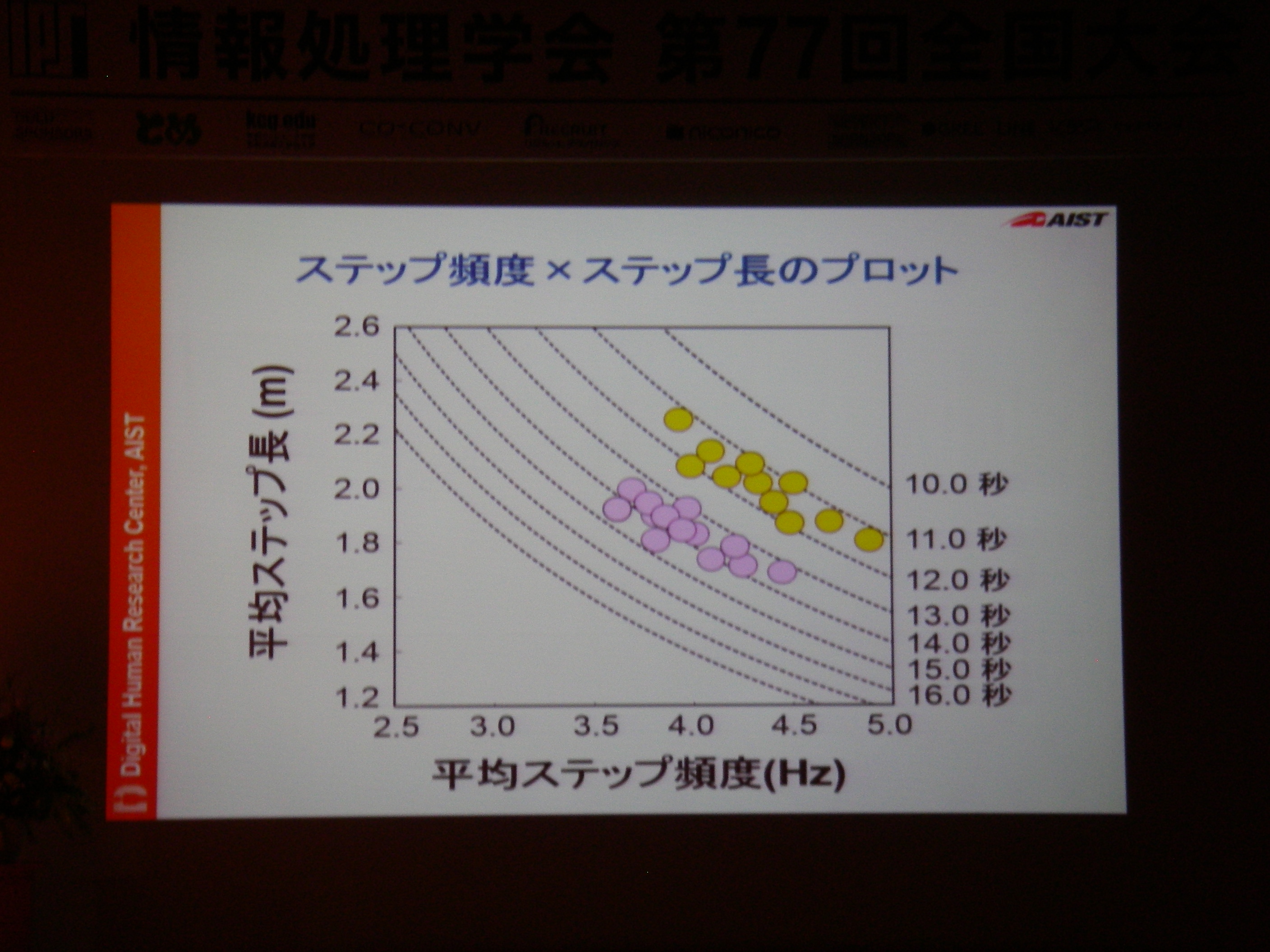
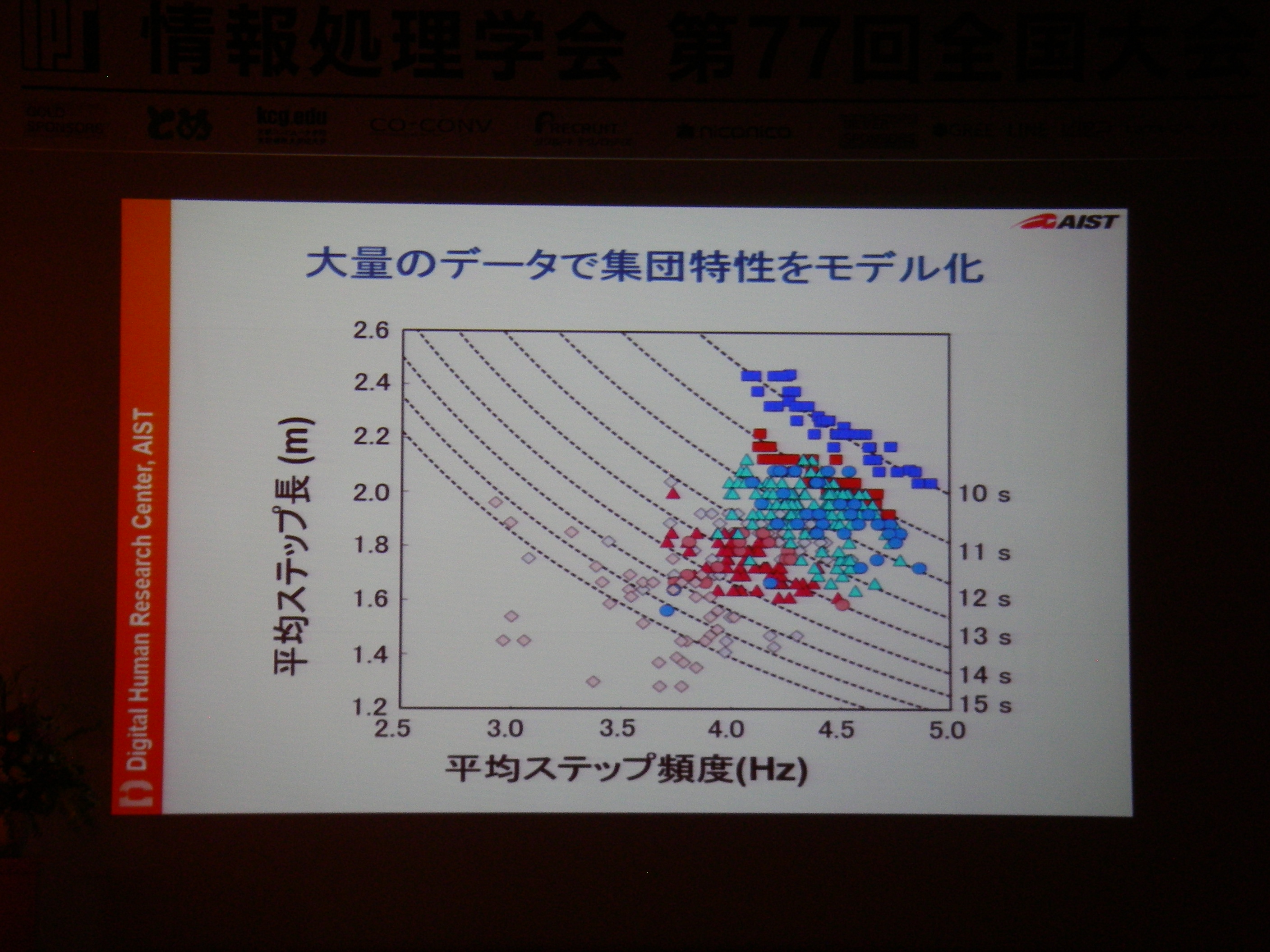

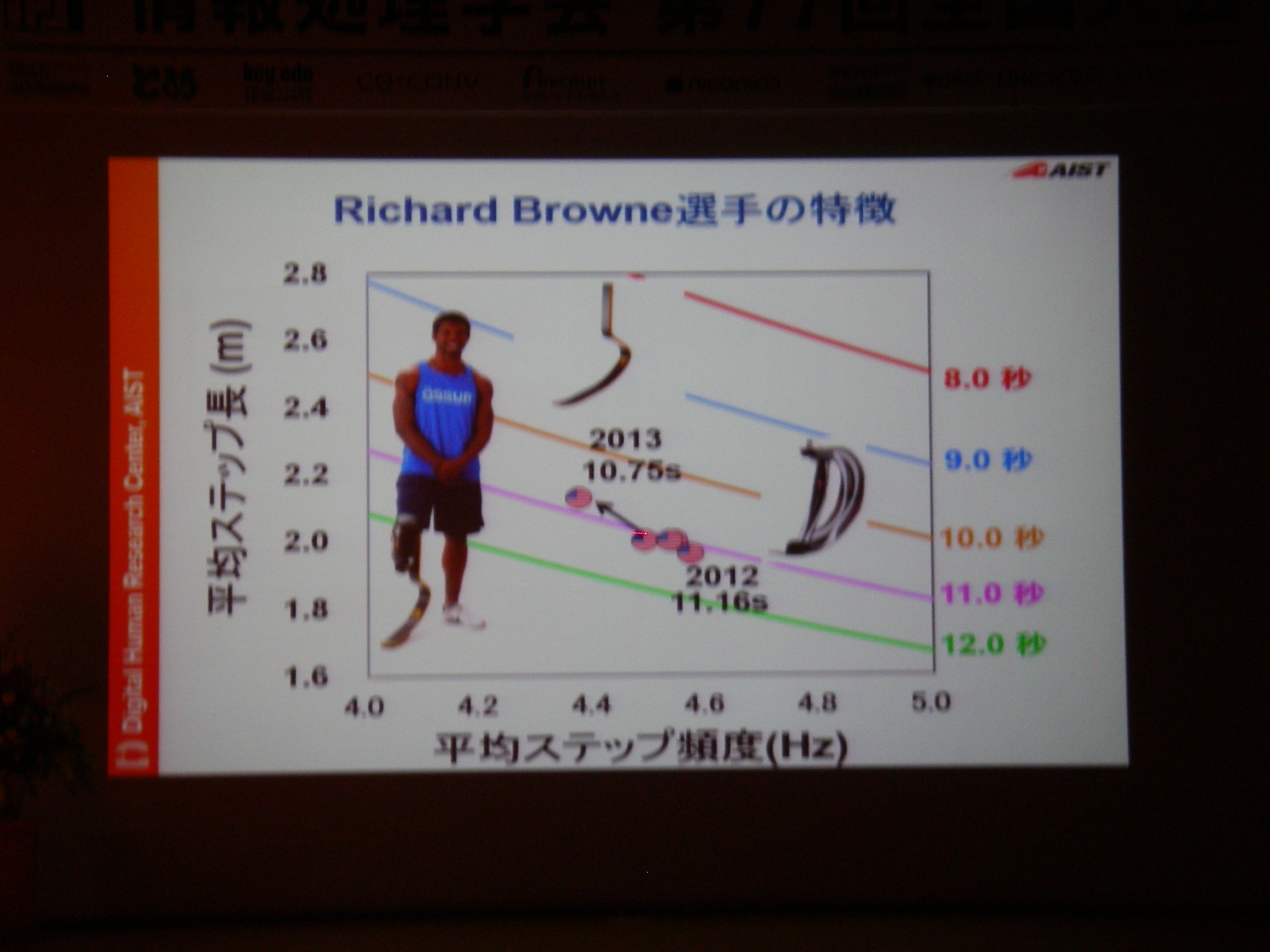
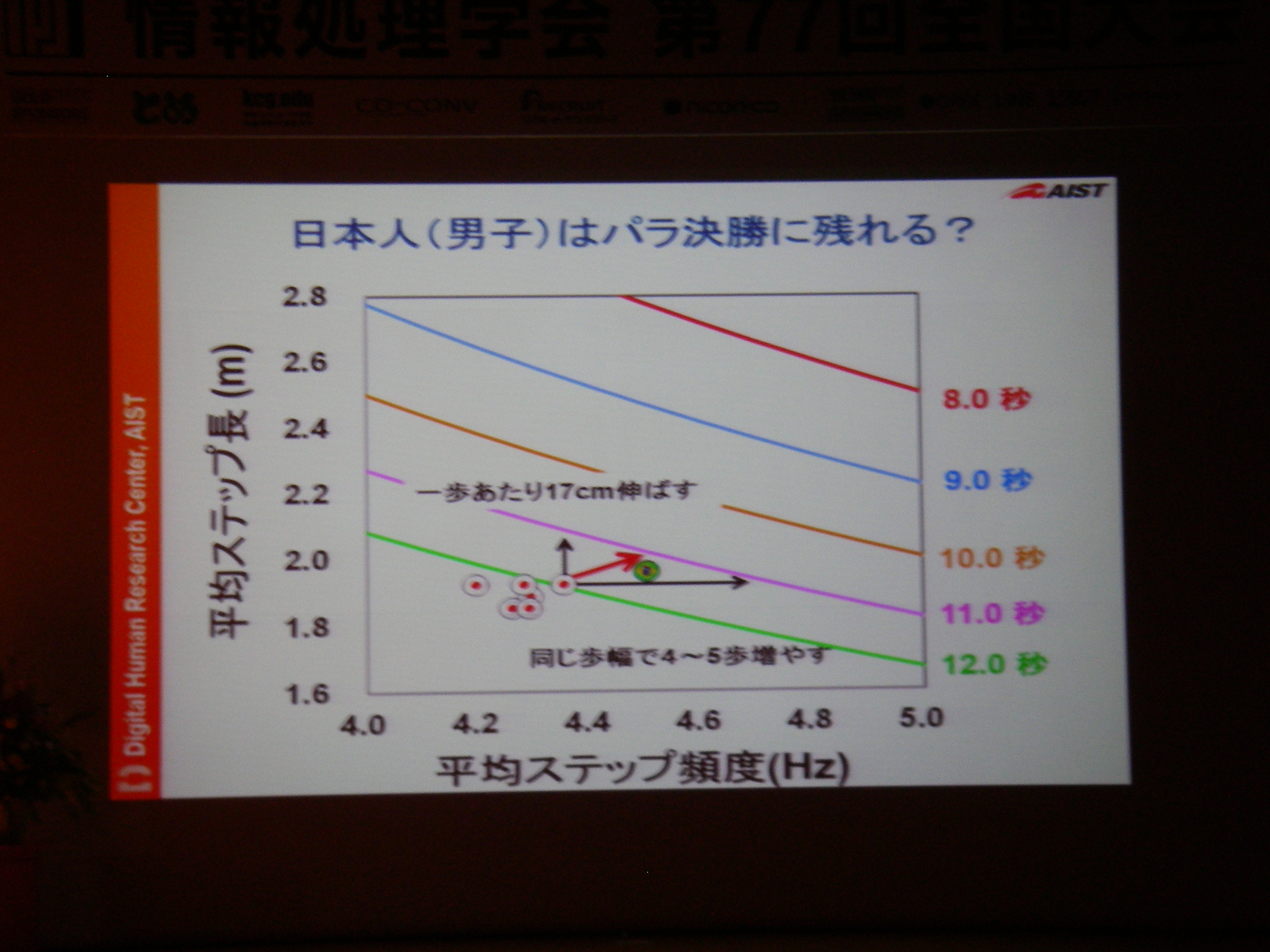

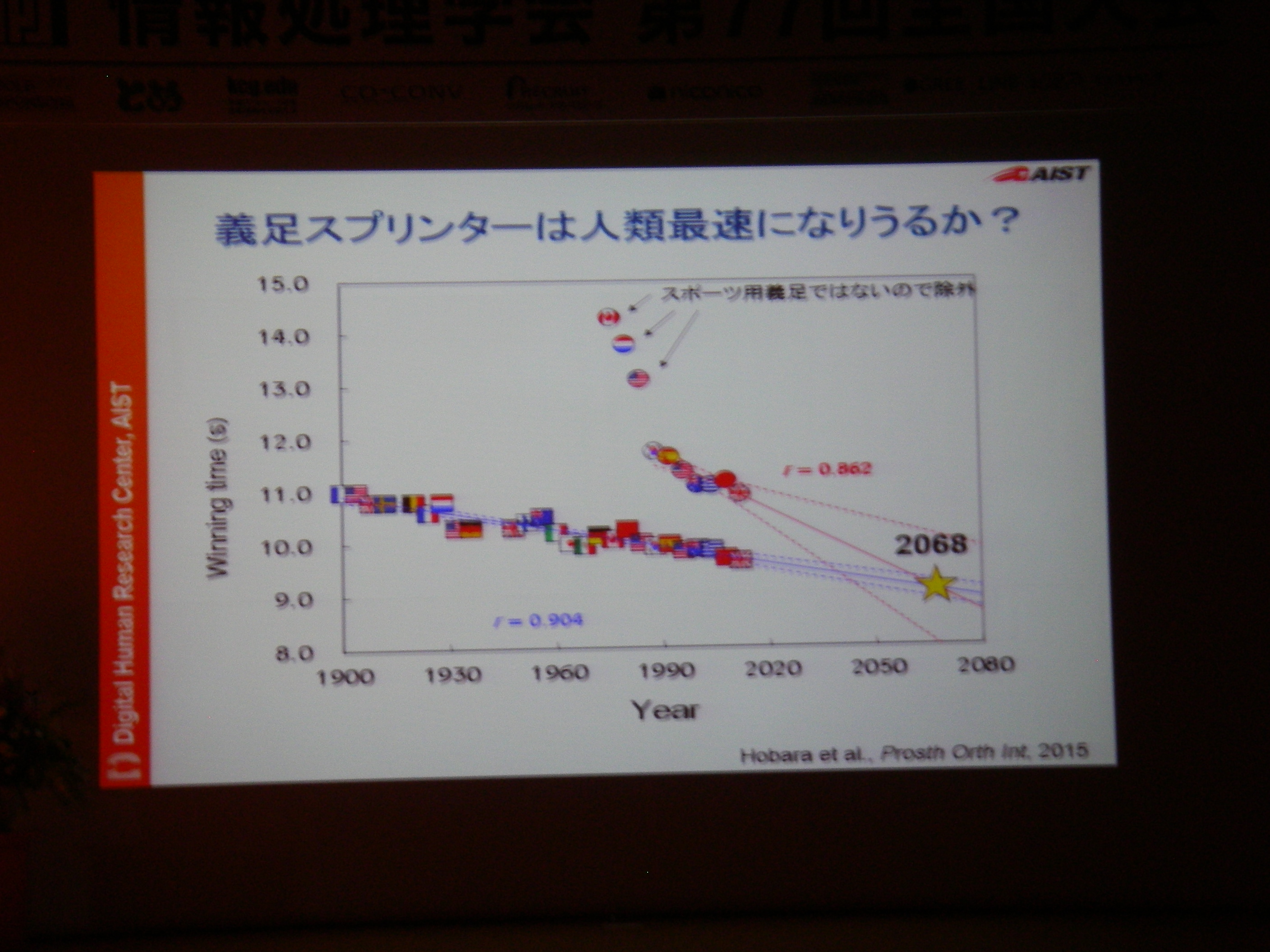
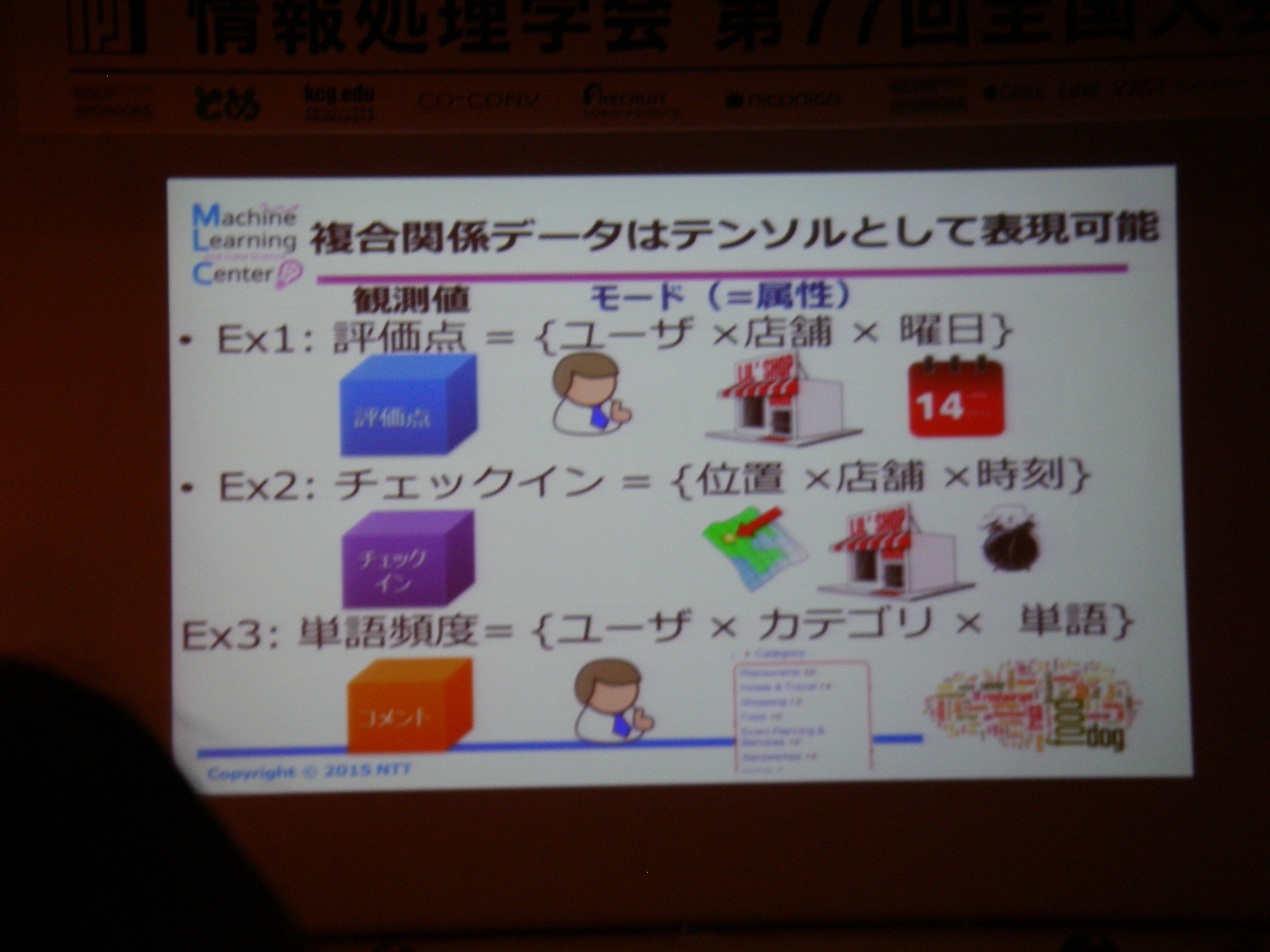
専用機器なりで高精度な情報収集して分析することは可能だけどあまりにもコストが高い。例えば100m走では機器1台100万、競技者毎に1台+1人モニタリング技術者が必要、それを8人分揃えるとか旅費とか考えたら死ぬし、そもそも実現場では収録できない状況もある。それに対し、(ある条件を満足している)YouTubeに投稿されてる動画からの分析であれば、分析コストのみでデータに基づいた支援が可能。実際にあれこれやってみてる、という話。
スポーツ用義足の機能
売った人も/利用者も/コーチもどの義足が良いのか分かっていない
ベストな組み合わせを見つけた選手が記録を打ち出している
ただし、両脚とも義足の方が良い
研究の現状
バイオメカニクスによる支援
ある条件下での基礎研究にはベスト
トップ選手の実験はほぼ不可能
本当に凄い選手は謎が多い(調べても無駄?)
言語化すること自体が困難?
モニタリングコスト(機器/人等)が高すぎる
代わりにYouTube動画からスピード曲線を描く(動画を眺めるだけではなく、データを抽出する)
欠点もあるが、本気モードを分析できる等のメリットも
欠点の発見だけに留まらない要注意
e.g., 国籍性別等どうしようもない違いを指摘してもどうしようもない
講演(3) 選手を育てるICT技術(陸上競技 競歩編), 今村 文男 (富士通株式会社 インテグレーションサービス部門 ビジネスマネジメント本部 インテグレーションサービス人事部 担当:陸上スタッフ)



特別講演 2: 官民が協働で推進する新しい海外留学支援制度について~「トビタテ!留学JAPAN」日本代表プログラム~
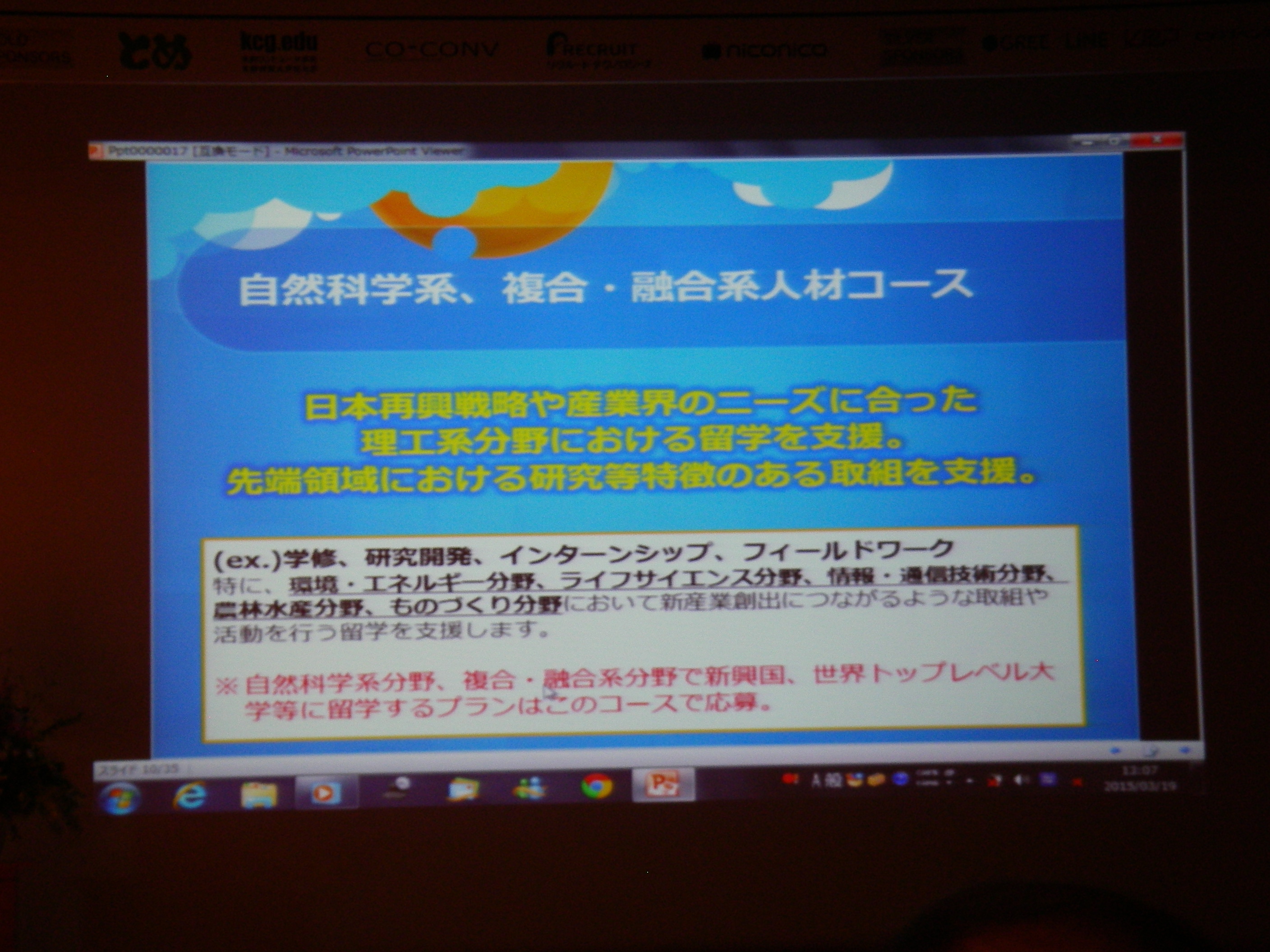



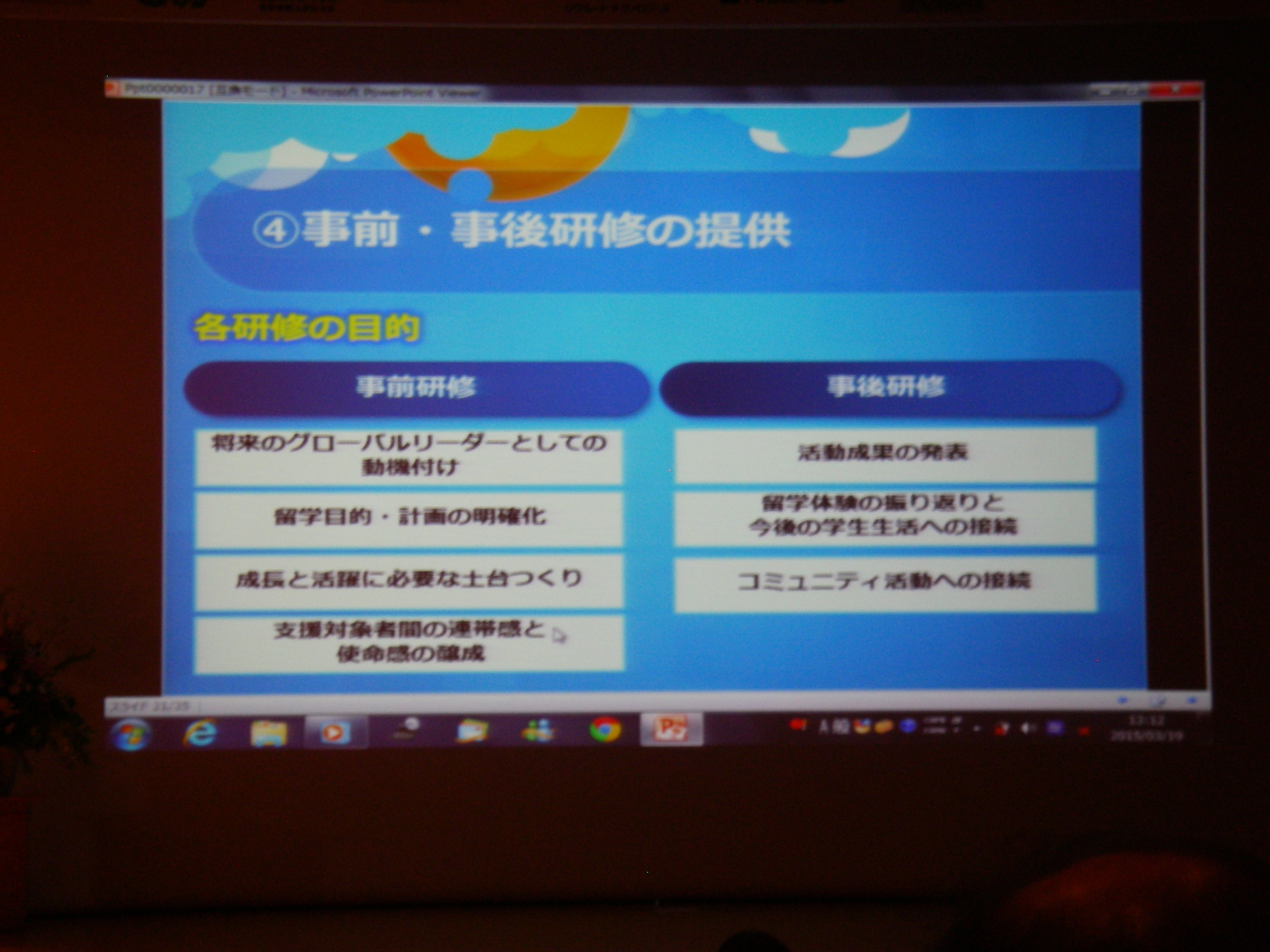
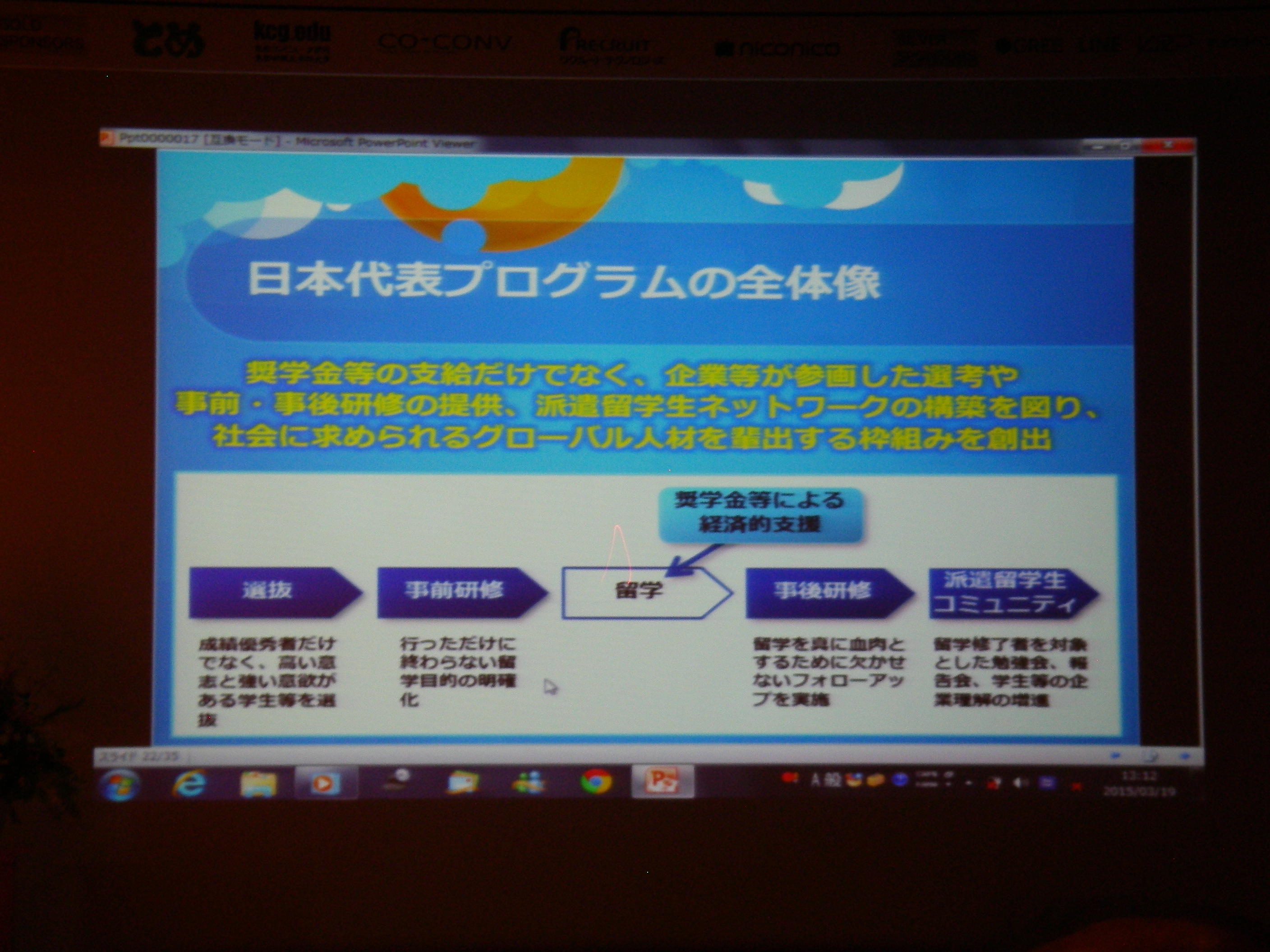




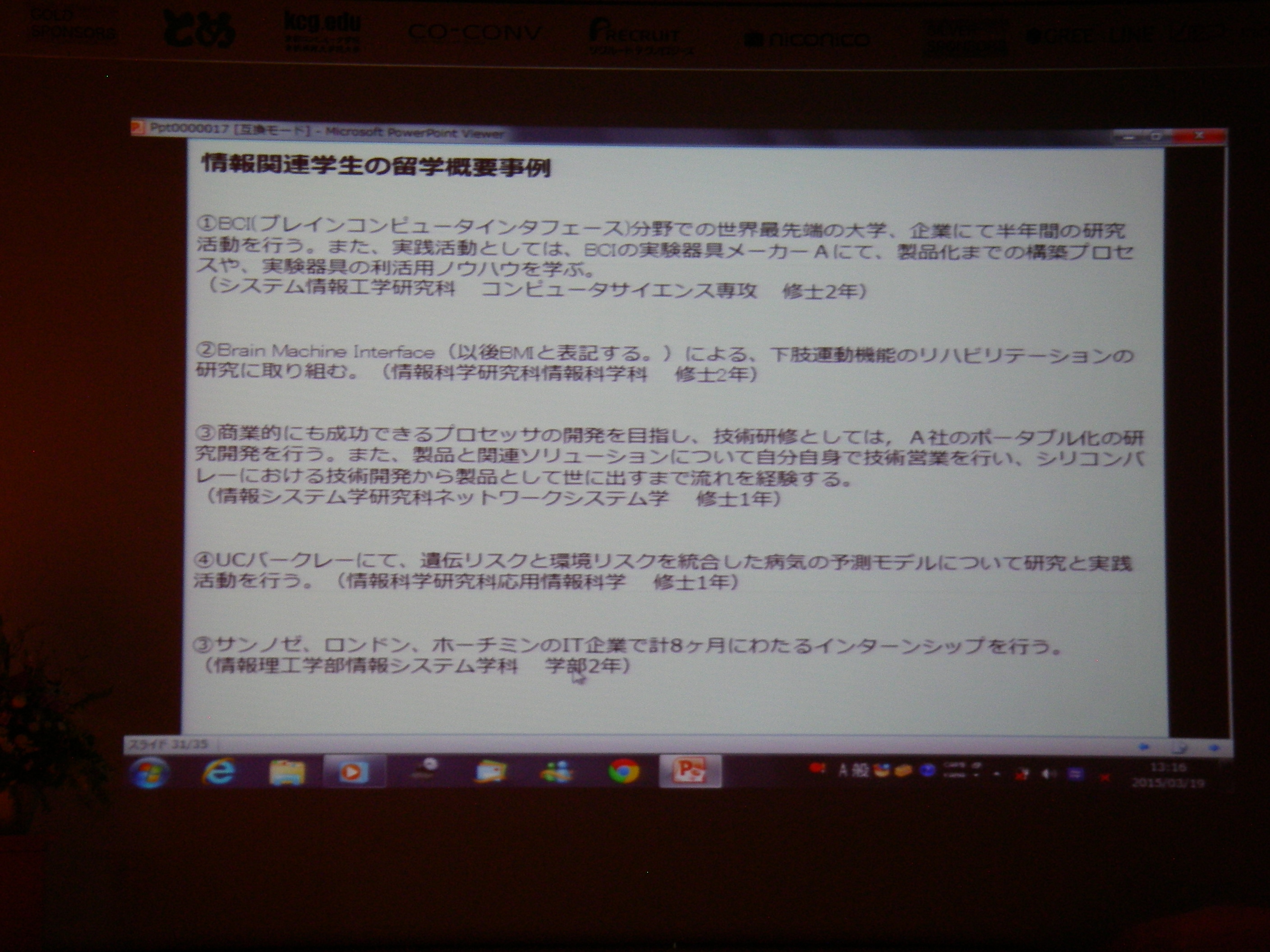
トビダテ!留学JAPANというプロジェクトの紹介。貸与型奨学金で、自由度もかなり高いのでどしどしチャレンジして欲しいとのこと。直近のやつはそろそろ〆切だけど、今後も1年に2度の公募で継続するらしい。
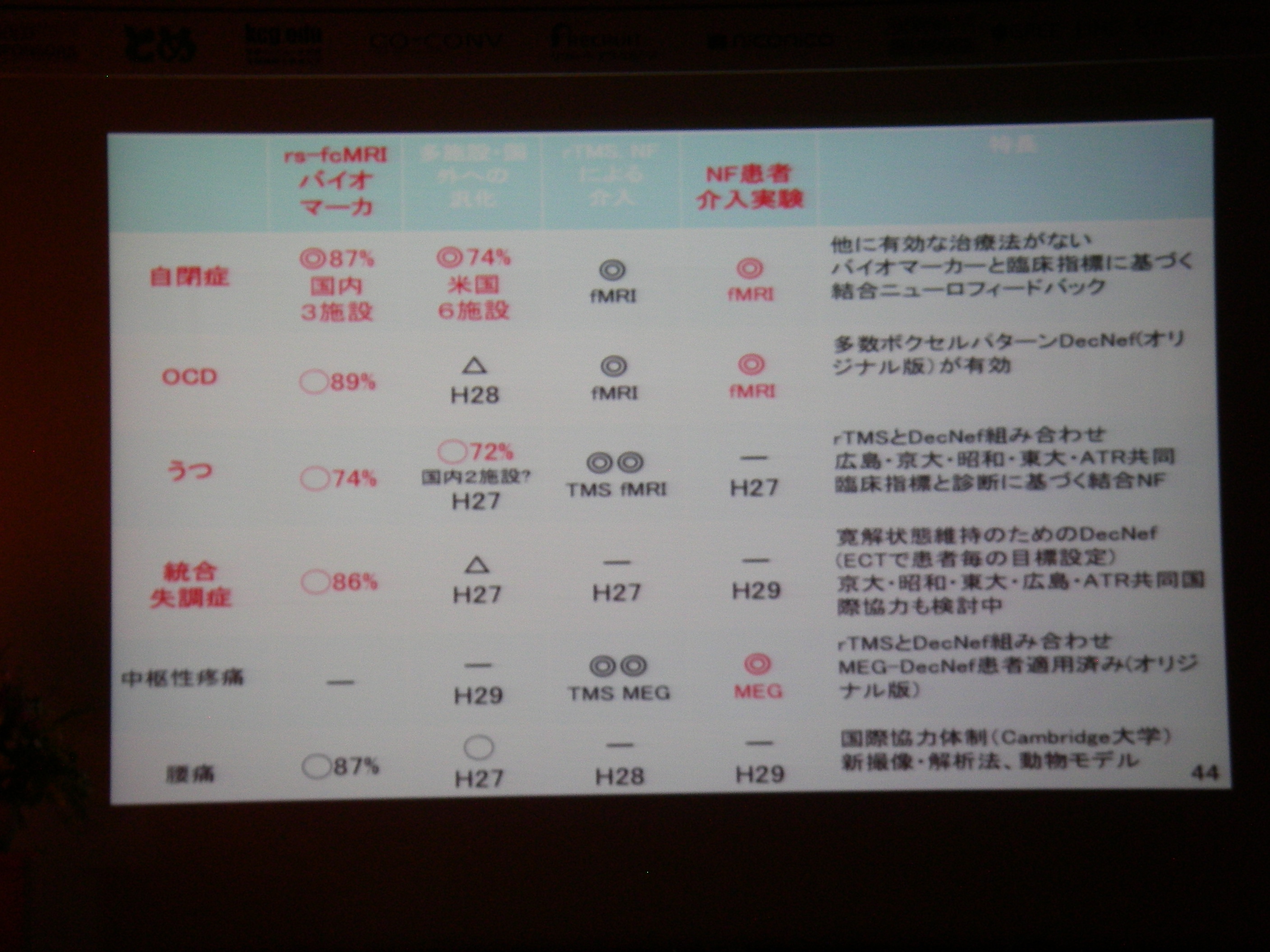
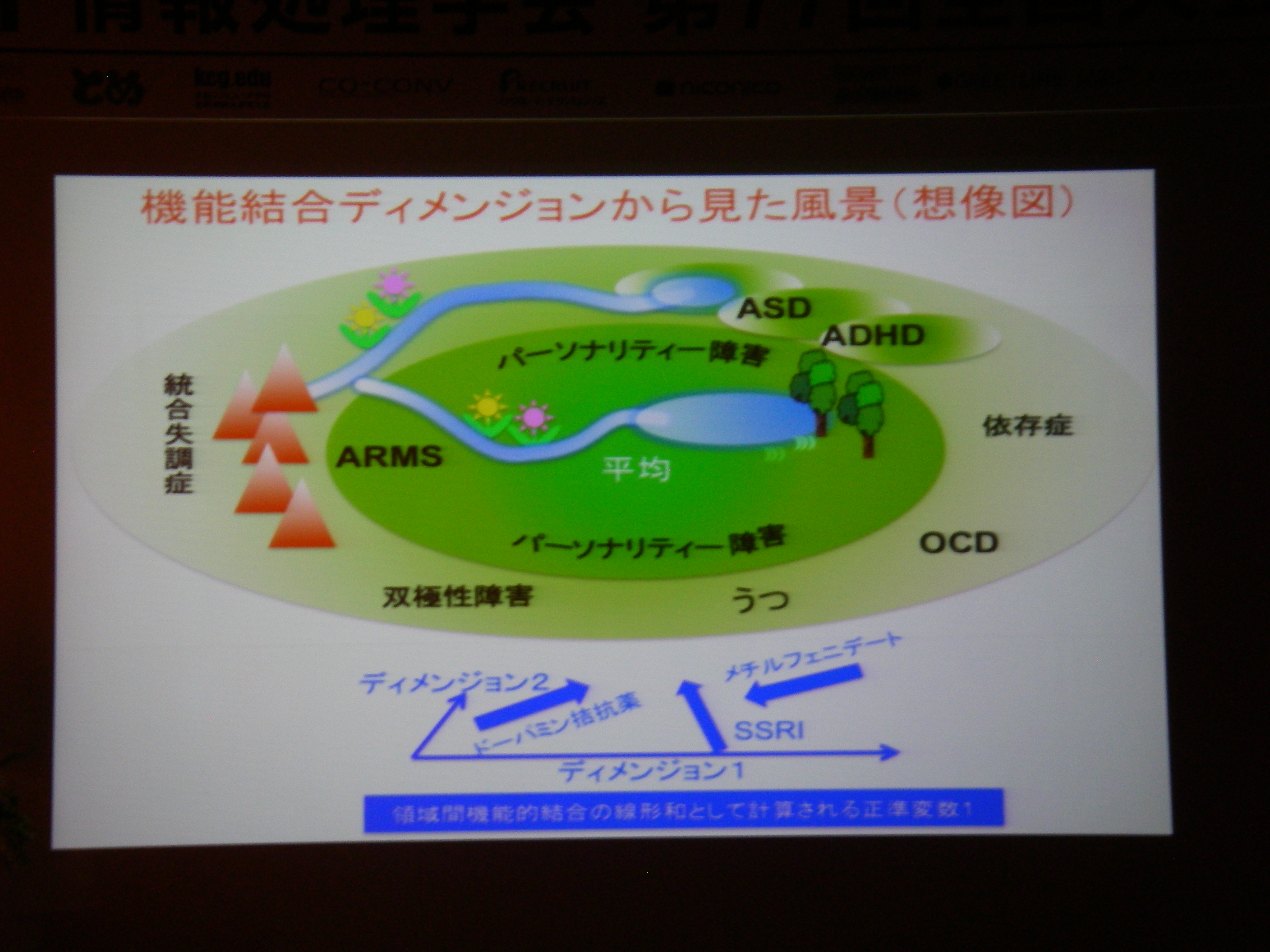
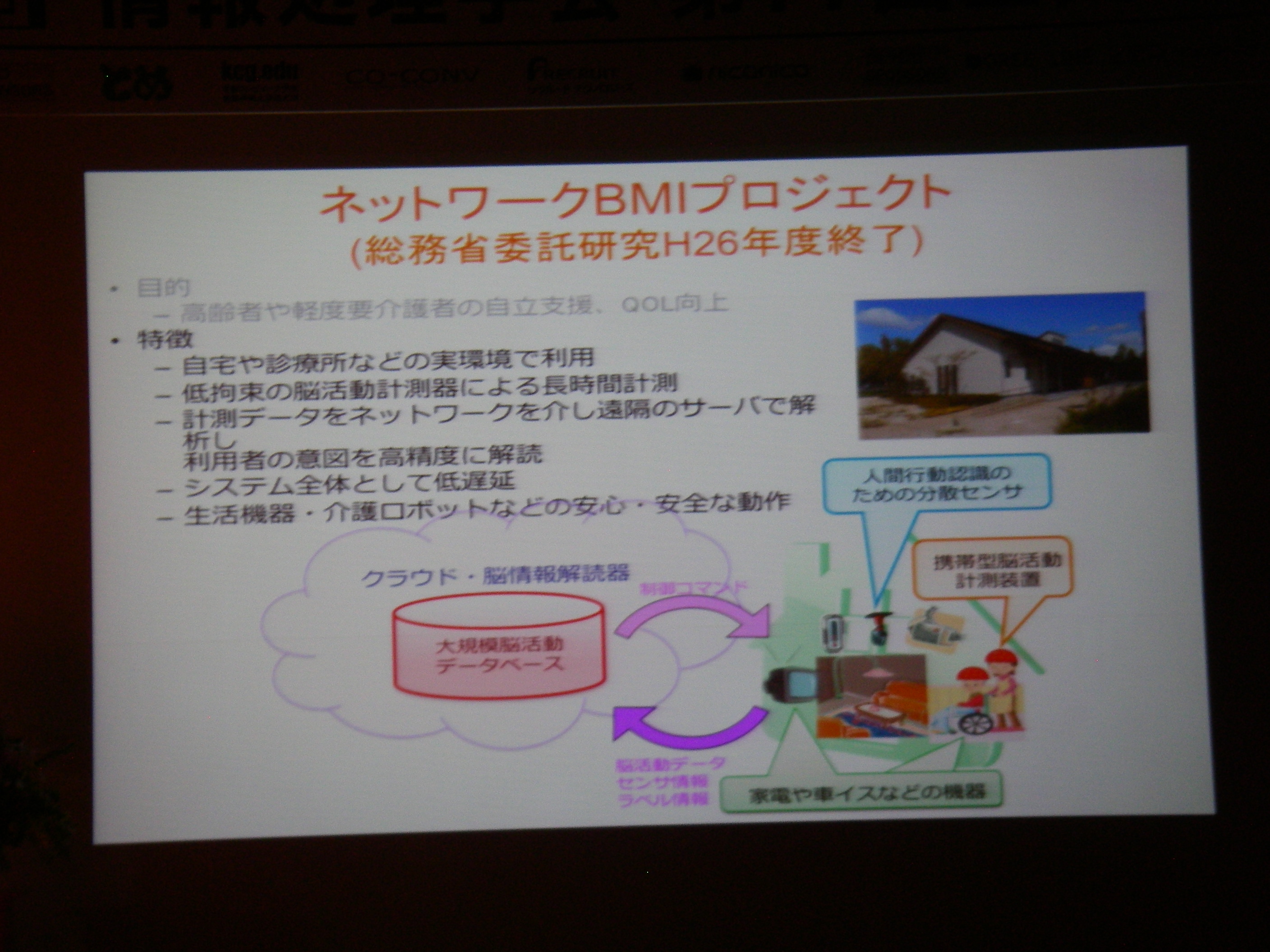
招待講演(5)情報処理技術を用いた脳の情報の解読と制御, 川人 光男(株式会社国際電気通信基礎技術研究所 脳情報通信総合研究所 所長)
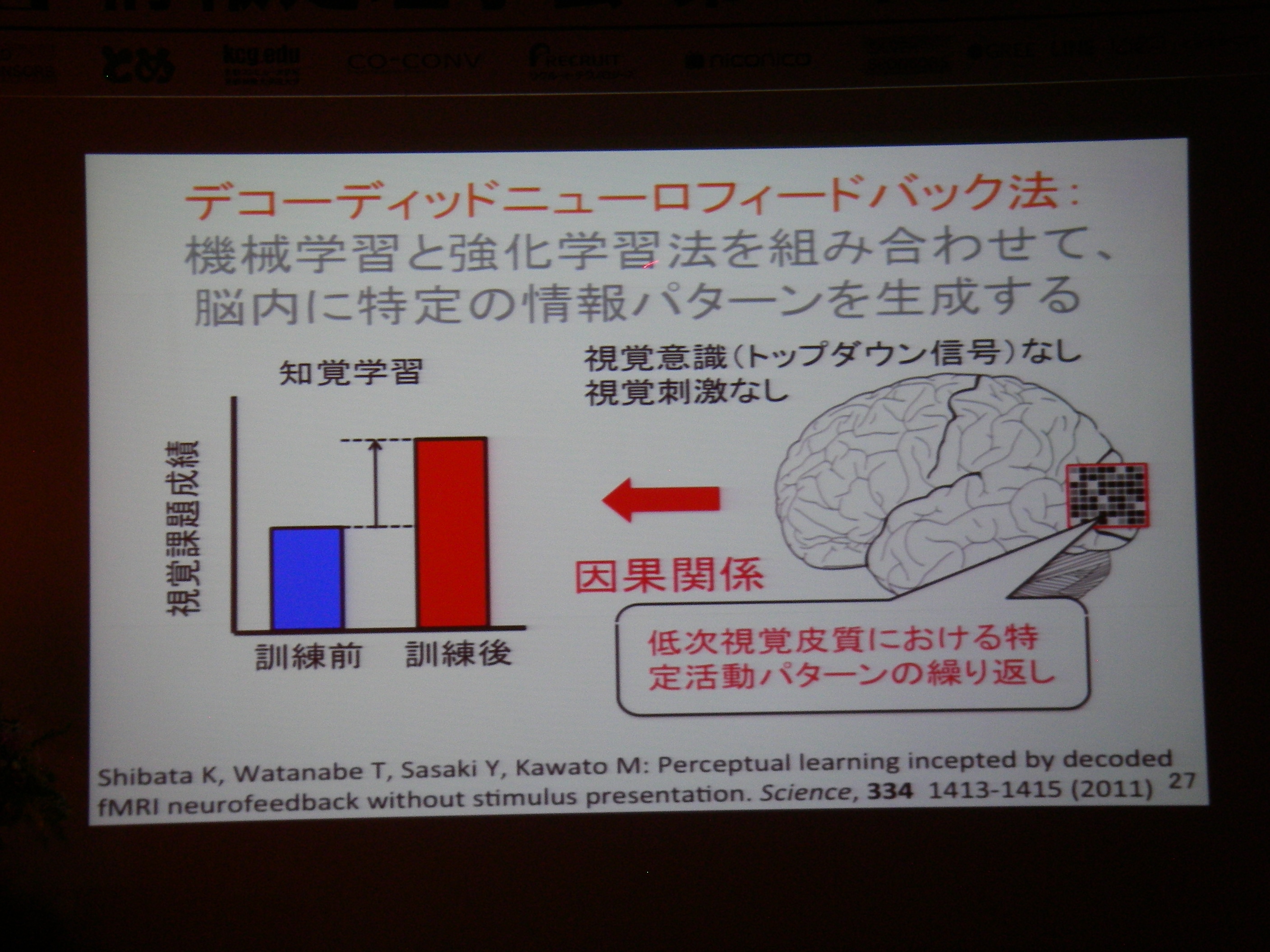
これまでのBMI(ブレイン・マシン・インタフェース)では相関を利用するぐらいの研究に終始していたが、デコーディング+フィードバックで因果関係解明も目指したい、という話。






豊富なセンサ+強力な演算能力+実応用
ブレイン・マシン・インタフェース
脳の感覚・中枢・運動機能を電気的人工回路でサポート
日本人向けには脳に直接電極を差すタイプは向かない?
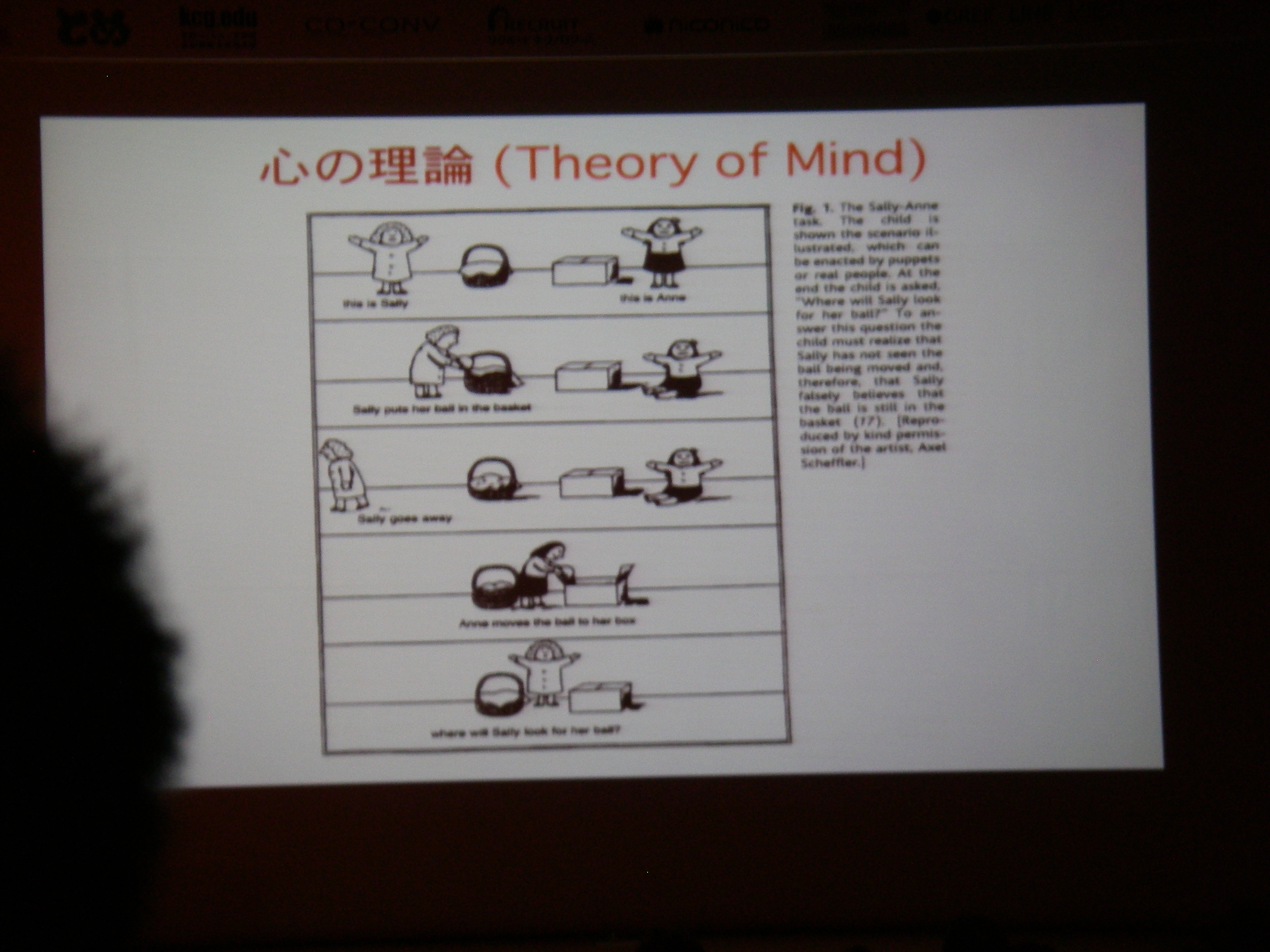
脳/心の解読(デコーディング)
classification or clustering or regression
モジュール性/階層性/スパース性、、、BMI3つの役割
活動モニタリング&分析
実時間でユーザに戻す
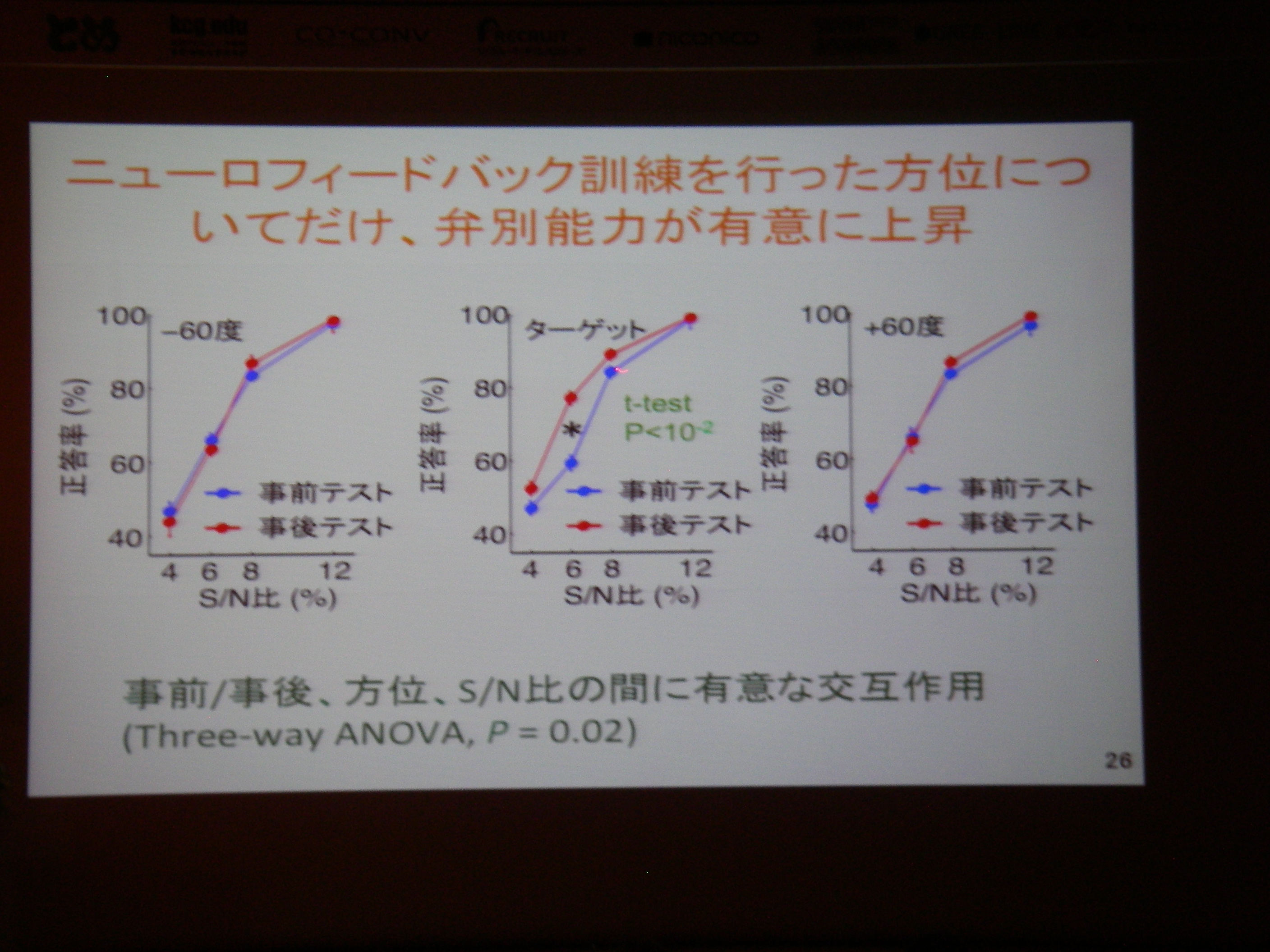
脳の活動そのものが変わる(回路が変わる): ニューロ・フィードバック
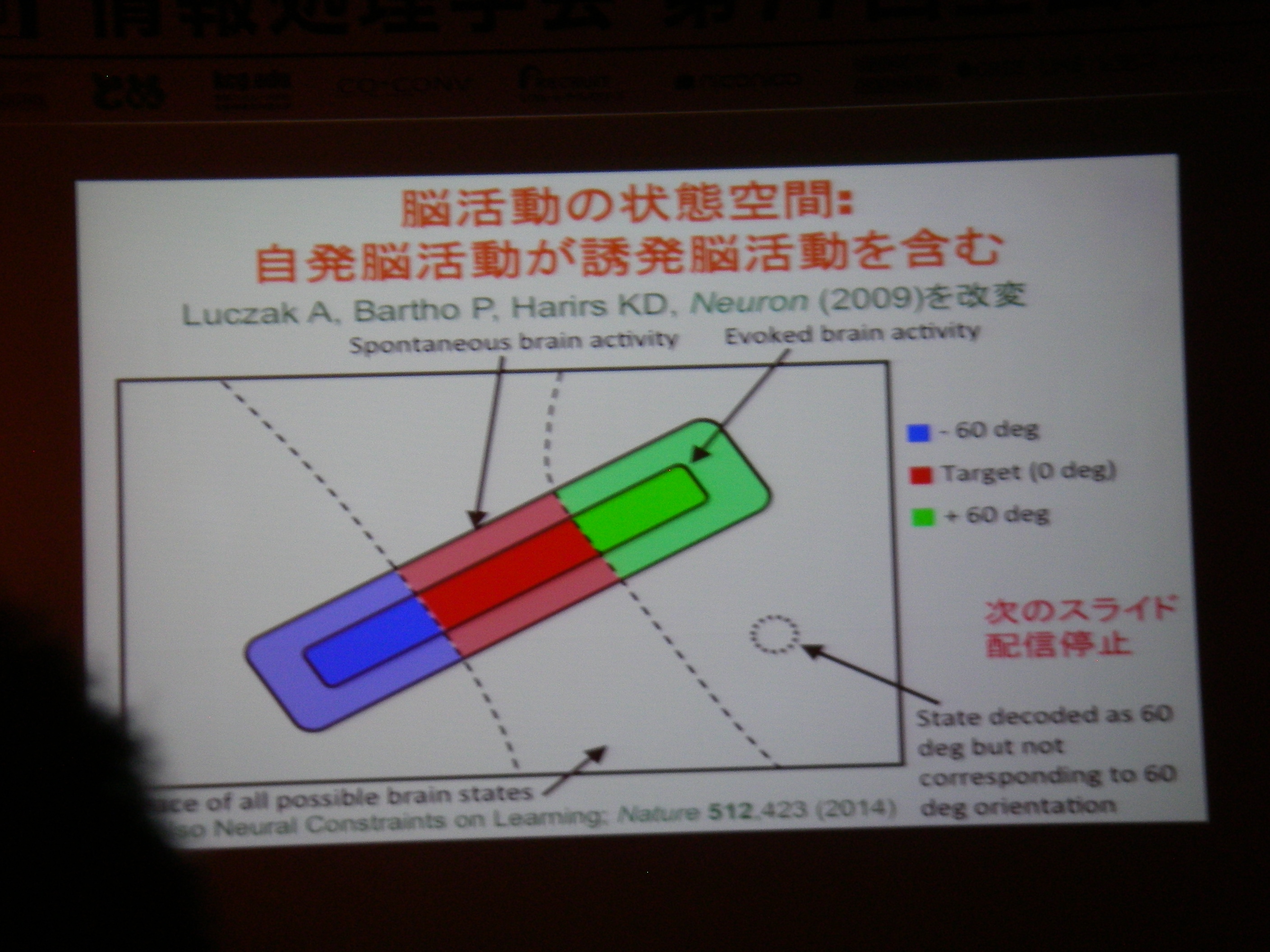
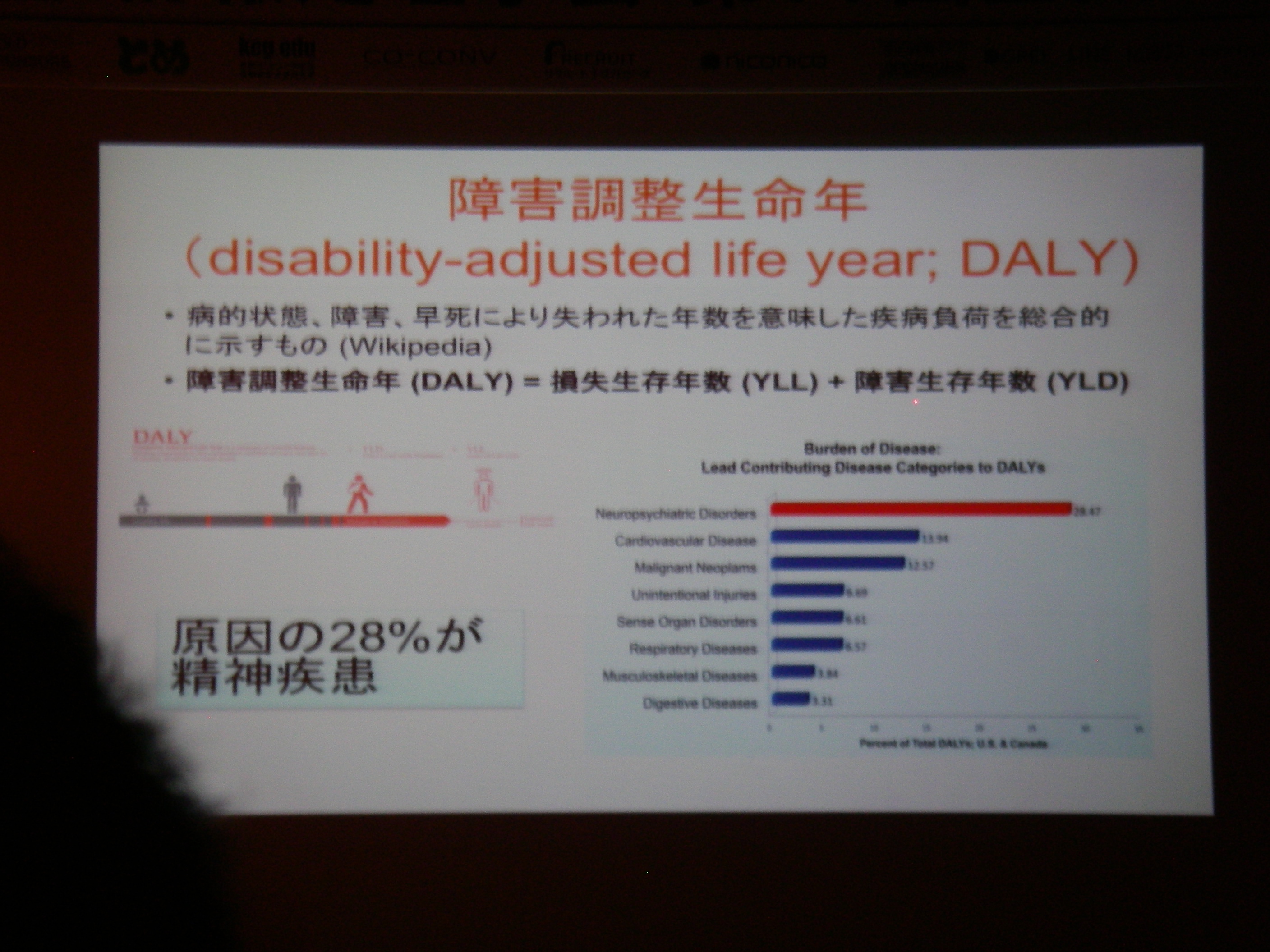
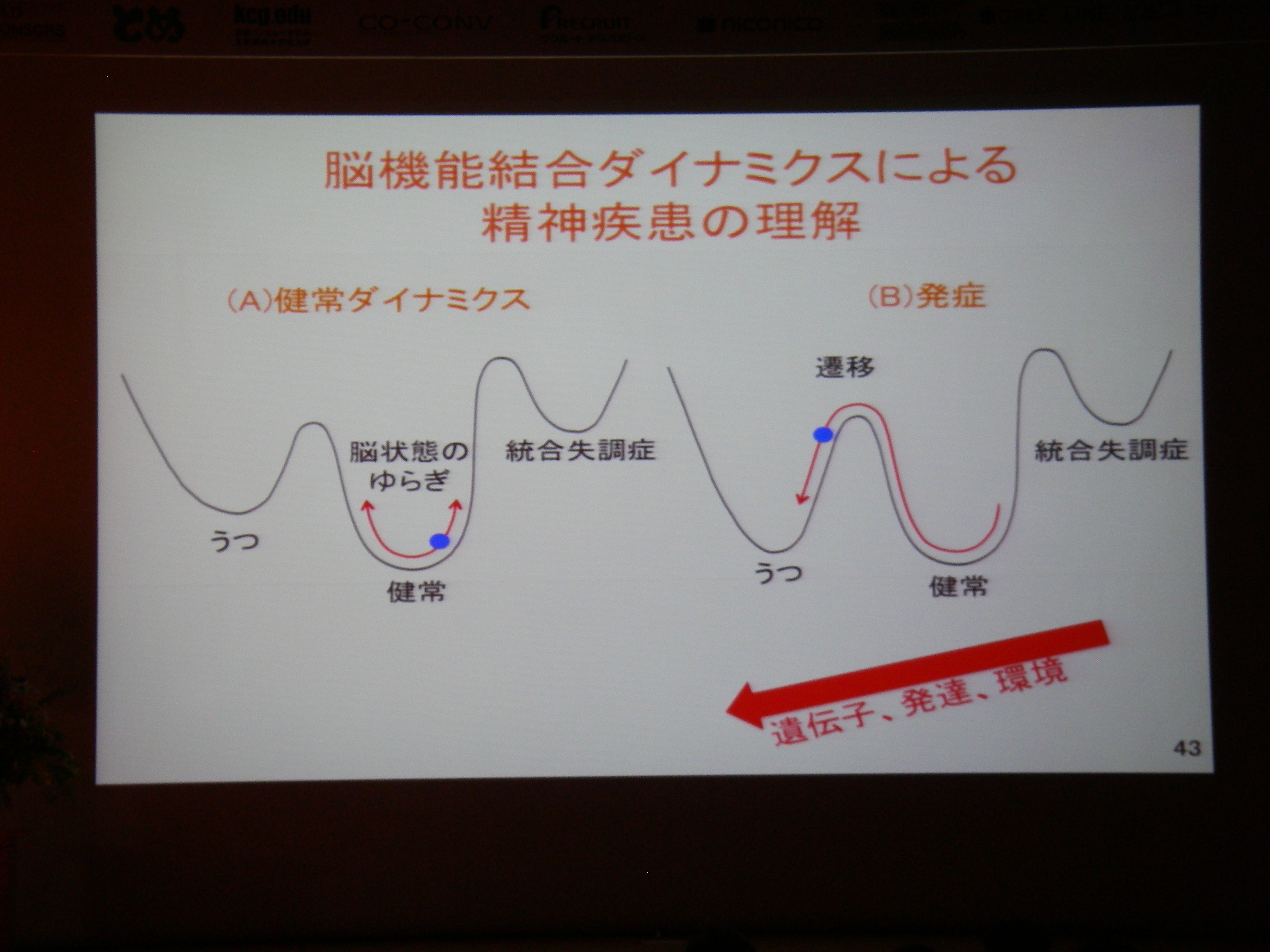
デフォールトモードネットワークの発見(15年前ぐらい前)
遅い(~0.03Hz)BOLD信号の振動の動機(相関)
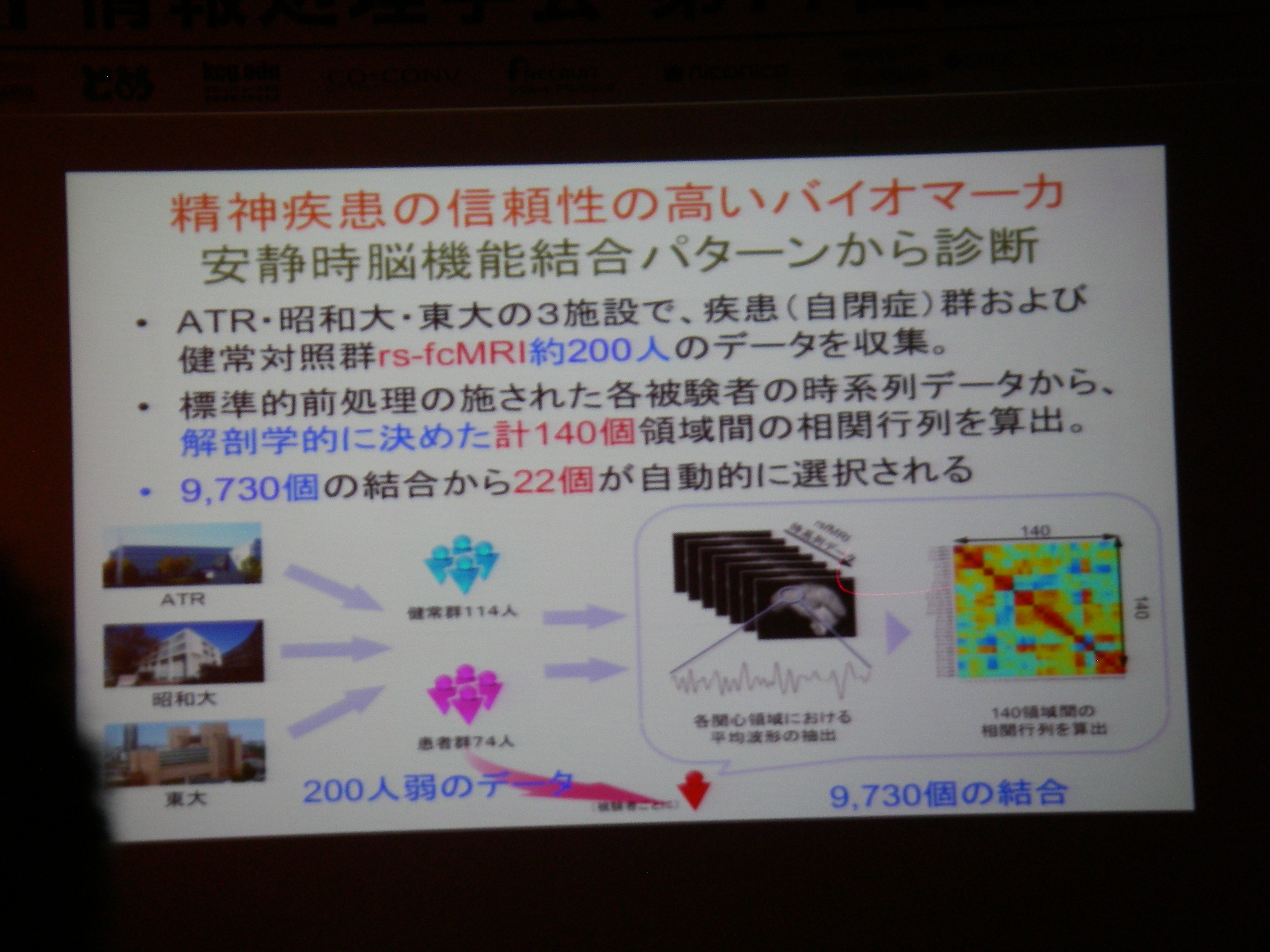
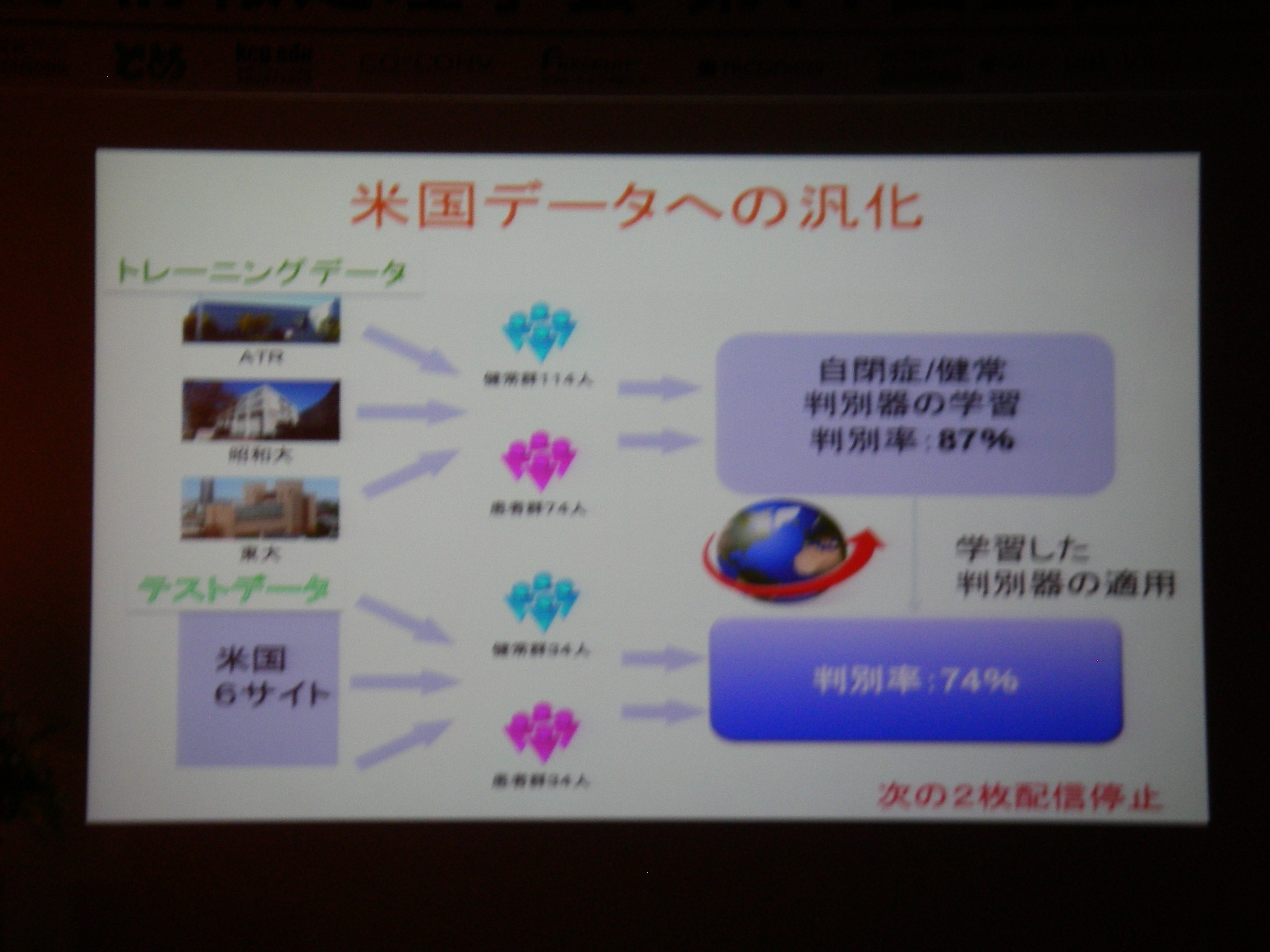
得られた状態から診断等への応用/フィードバック
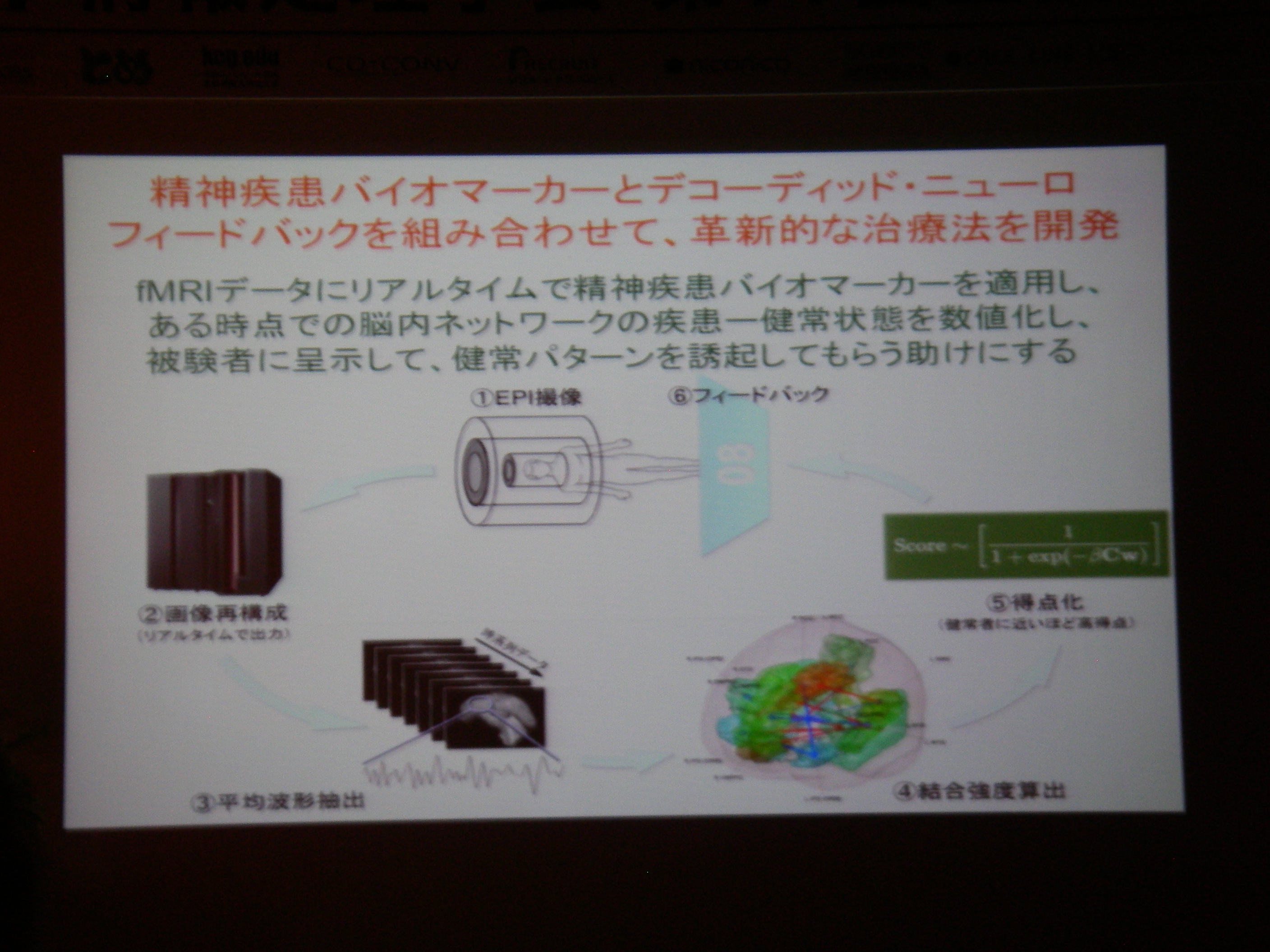
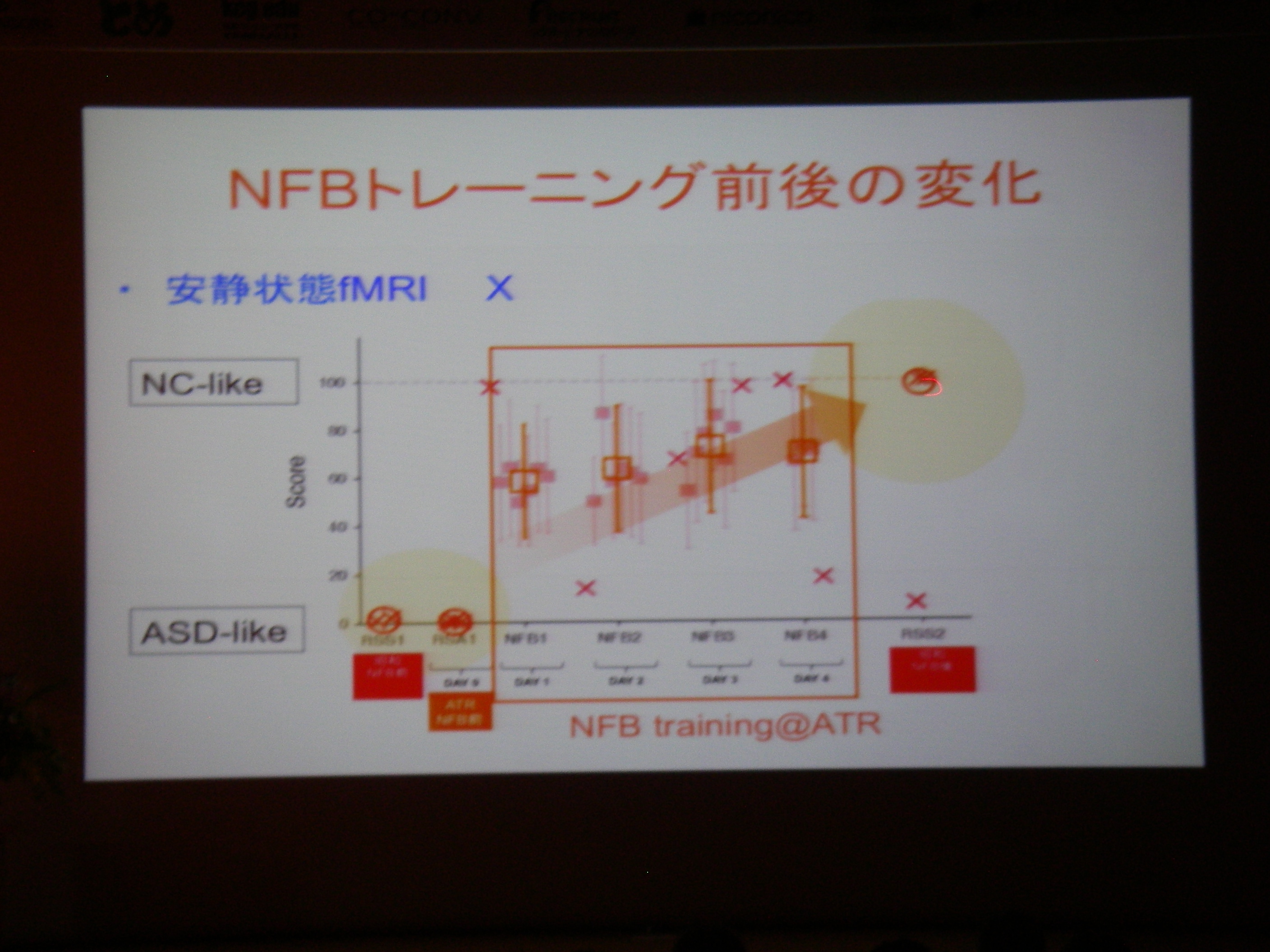
fMRI実時間ニューロフィードバック(脳の特定の場所を活動させたりするための強化学習支援)
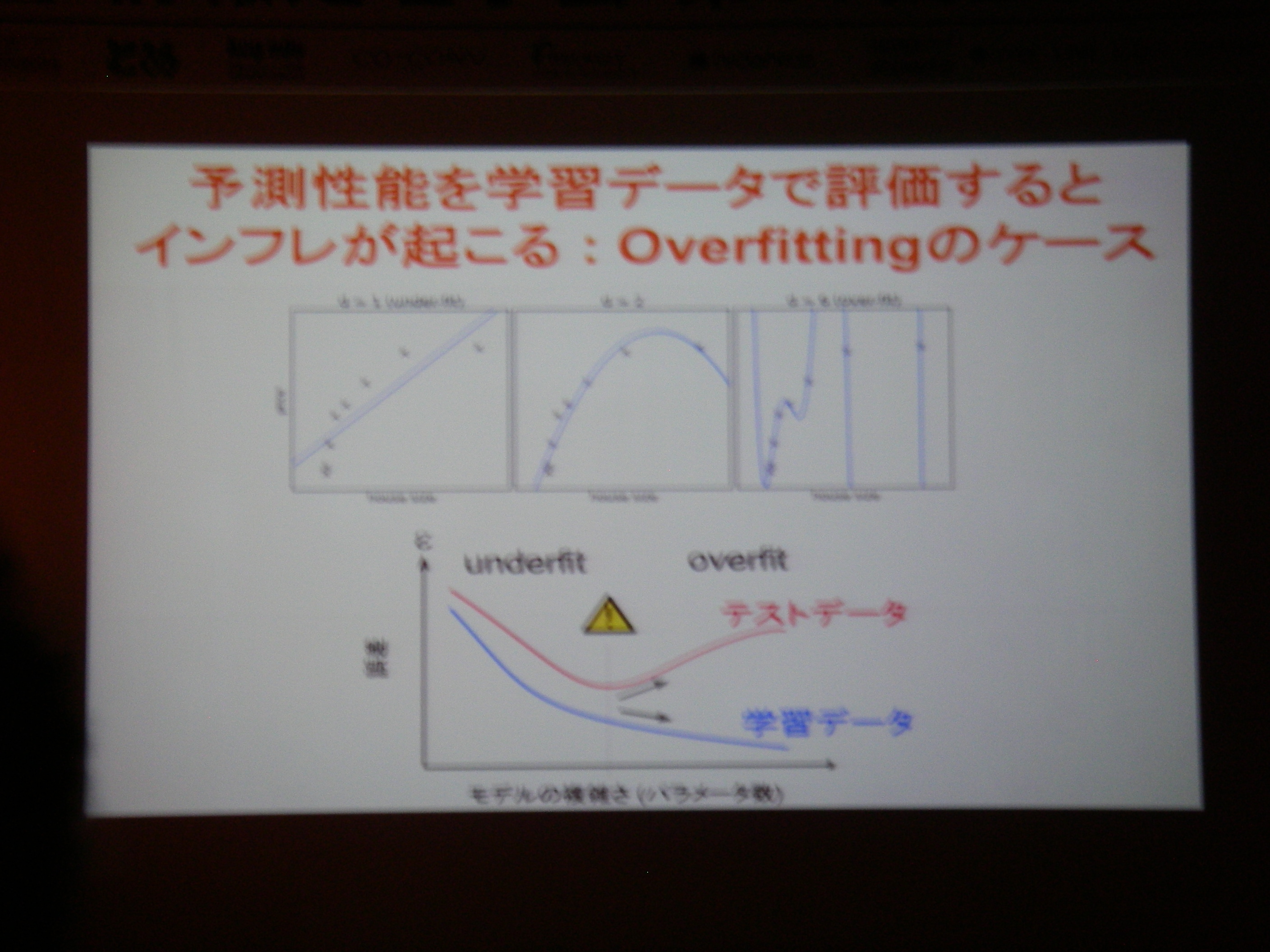
従来の相関に終始していた分析から、フィードバックすることで因果関係の解明へ(目標)
DecNef: モデル無しで機械学習+強化学習
学生セッション[6M会場] 情報推薦 座長 平手 勇宇(楽天)

嗜好抽出を目的とした電子書籍へのアノテーションの分析は、自由にアノテーション(start-endマーキングだけ)付けてもらった結果から嗜好抽出できるか、という話。できるだろうけど、表層的な情報しか使ってないのが物足りないかも(似たようなのあちこちにありそうなので)。
平良くんの感情推定に基づく小説推薦システムのための認知的評価質問セットを用いたシミュレーションは、後で質問コメントを整理してくれるでしょう。
参加者の嗜好を考慮した飲食店推薦システムの開発は、店舗毎にレーダーチャート的に用意した評価軸毎に評価してもらったログを用意し、嗜好を考慮して推薦したいという話。気持ちは分かるけど、類似事例との違いが良く分からず。
学生セッション[6P会場] 対話システム 座長 篠田 浩一(東工大)



対話を通じた情報獲得のための質問選択とその実験的評価は、情報不足で答えられない時には対話でユーザから情報取得しよう、ただしそれをなるべくユーザに負担なく、かつ、効率良くしたいという話。
SVMとCRFを用いたロボットによるロバストな命令理解とロボットの行動命令発話理解における不足情報の処理は同じチームの発表で、RoboCup@HomeのGPSRタスクを例に、よりロバストなシステムを作ろうという話。基本的には「命令」なので、「どういう種別の命令かを判別するタスク」+「どんな名詞が含まれているかを抽出するタスク」を各々高精度にすることで質を高めることができるということで、そこに機械学習導入してみたとのこと。
多様な形態の相槌をうつ音声対話システムのための傾聴対話の分析は、相づちの形態(「うん」「うんうん」とか)を判別するために視線(ここでは顔の向き、ぐらいの意味)を利用してみたという話。
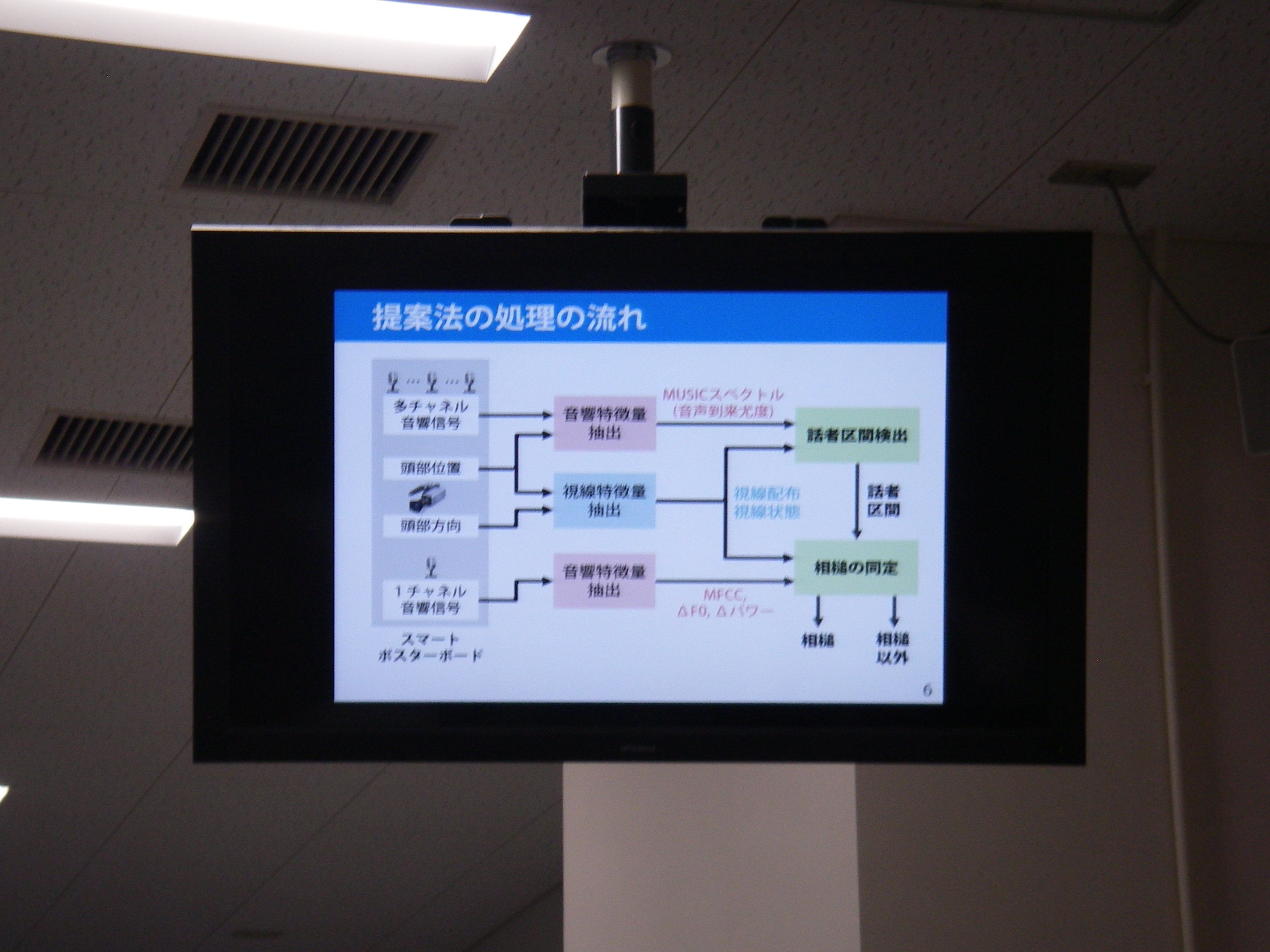
スマートポスターボードにおける視線情報を用いた話者区間検出及び相槌の同定は、話者区間(だれがいつ話しているか)+相づち判定(誰が聞き手か)をするために、10マイクロフォン+Kinect使って処理したという話。従来に比べ視線(顔の向き)を利用することでかなり精度改善に寄与したとのこと。
お食事


当初予定していた豆腐料理屋さんは既に待ち行列になってたため、その途中で見かけた拉麺小路店にあったますたにへ突撃。背脂使いつつサッパリという謎の表現してましたが、確かに一般的なこってり押しのやつと比べると相対的にはサッパリしてるか。